ChatGPTはどこから情報を持ってくるの?—3つの経路とサイト運営者が確認すべきこと

ChatGPTに質問すると、まるで何でも知っているかのように答えてくれます。でも、その情報はどこから来ているのでしょうか。
実は、ChatGPTが情報を集める方法は1つではありません。「過去に学習済みの情報」「質問に応じてWebを検索した情報」「誰かがURLを直接渡した情報」という3つの経路があります。
そのため、同じChatGPTの回答でも、どの経路で情報を取得したかによって答え方や情報の新しさが変わることがあります。
また、サイト運営者の視点で見ると、これらの情報取得はサーバーログに痕跡として残ることがあります。実際にAI観測ラボでも、GPTBotやOAI-SearchBot、ChatGPT-Userによるアクセスを継続的に観測しています。
この記事では、ChatGPTがどこから情報を持ってくるのかを、「学習済みデータ」「Web検索」「URLの直接取得」という3つの経路に分けてわかりやすく解説します。
この記事でわかること|📖:約5分
- ChatGPTが情報を集める3つの経路(学習・検索・URL渡し)
- ChatGPTがサイトを読んだときにサーバーログへ残る仕組み
- 自分のサイトがChatGPTに読まれているか確認する方法
- 2026年6月時点で観測したGPTBot 635件、OAI-SearchBot 124件、ChatGPT-User 73件の実測データ
ChatGPTって勝手にインターネットを見てるの?
結論からいうと、ChatGPTは状況に応じてインターネット上の情報を利用しています。ただし、「いつ・どうやって」情報を取得するかによって3つのパターンに分かれます。
例えるなれば図書館がわかりやすいです。
- 昔読んだ本の内容を覚えている(学習済みデータ)
- 知らないことを今すぐ調べに行く(リアルタイム検索)
- 誰かが「これ読んで」と本を手渡してくる(URL直接渡し)
上記3つが、ChatGPTの情報収集の全体像です。
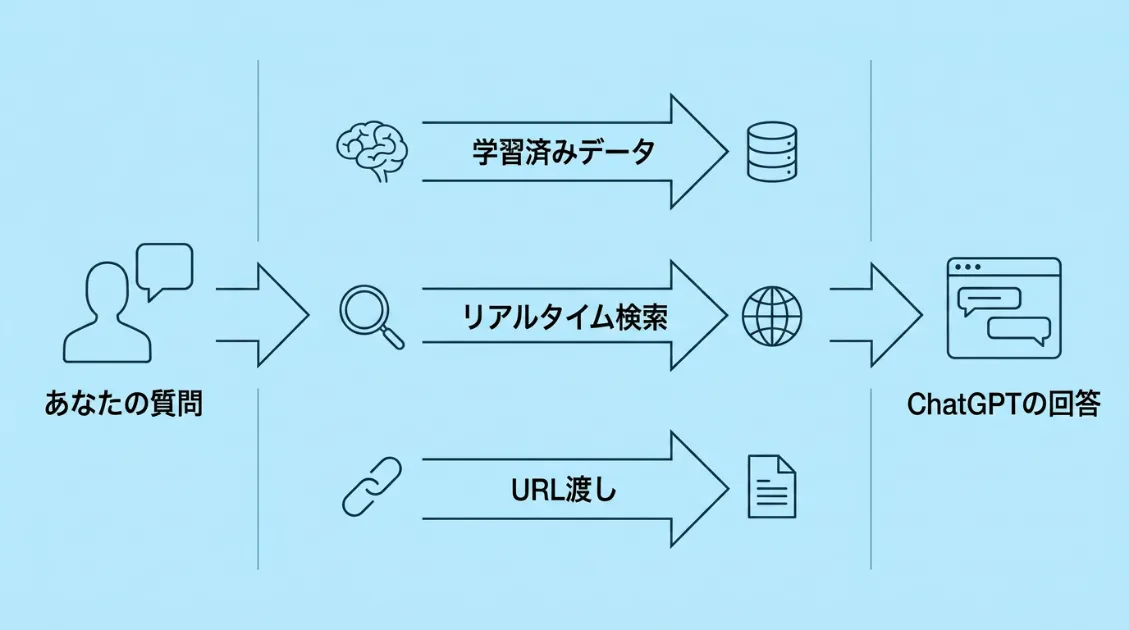
サイト運営者の視点で見ると、それぞれの行動はGPTBot、OAI-SearchBot、ChatGPT-Userといったアクセスとしてサーバーログに記録されることがあります。
昔読んだ情報(学習済みデータ)
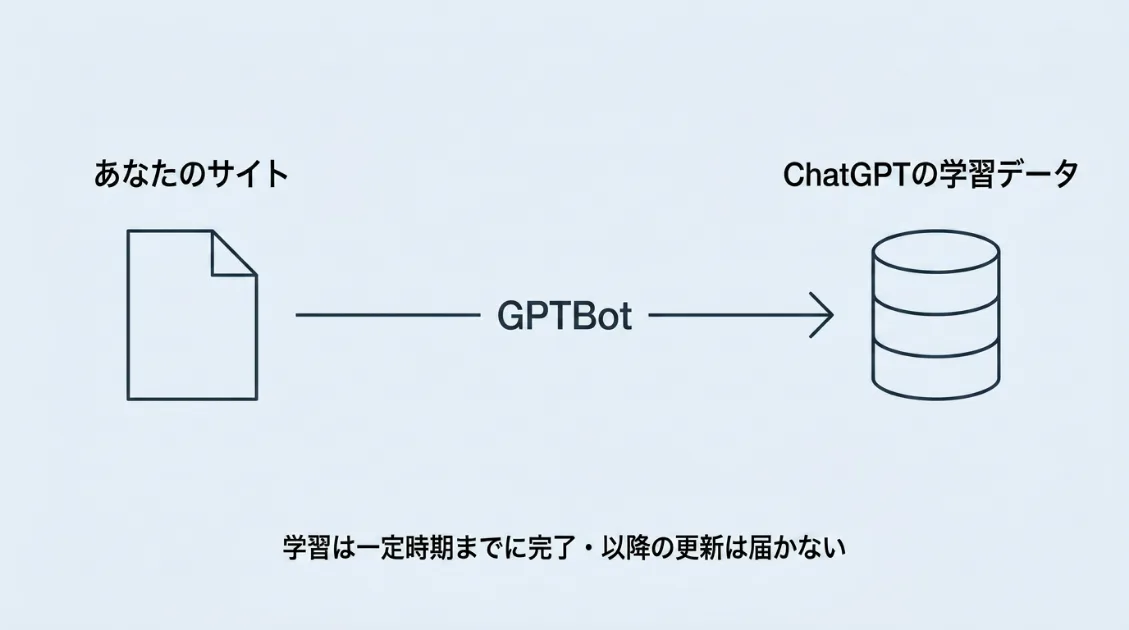
ChatGPTは、インターネット上に公開されている大量のWebページを事前に読み込んで学習しています。ただ、一度覚えた情報は自動で更新されるわけではないため、古い内容が含まれることがあります。
たとえば「富士山の高さは?」と聞けば、ChatGPTはインターネットを調べに行かずに答えられます。過去に学習した情報がすでに頭の中に入っているからです。
サイト運営者の視点から見ると、この学習用データの収集に利用されるクローラーの1つがGPTBotです。GPTBotがサイトを訪問することで、そのページが将来の学習対象として収集される可能性があります。
しかしながら学習済みデータには注意点が1つあります。学習した時点より後に更新した情報は、ChatGPTには届きません。記事を書いても、すぐにChatGPTの回答へ反映されるわけではないということです。
そのため、最新ニュースや直近の価格情報などは、次に紹介する「リアルタイム検索」で取得されるケースがあります。
ChatGPTが最新情報を探すとき
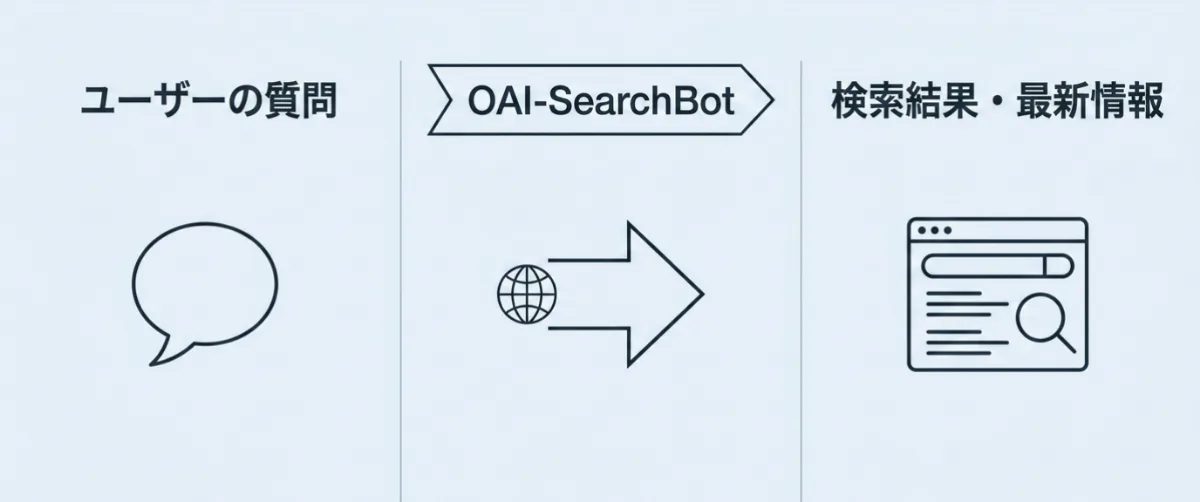
学習済みデータだけでは、最新のニュースや直近の出来事には答えられません。なのでChatGPTは、必要に応じてリアルタイムでWeb上の情報を取得することがあります。
「今日の天気は?」「最近のAIニュースを教えて」といった質問をすると、ChatGPTはその時点の情報を参照して回答を生成します。
ただ、ChatGPTが毎回必ず検索するわけではありません。質問の内容によって、学習済みデータで答えるか、Web上の情報を参照するかを判断しています。
サイト運営者の視点から見ると、このような情報取得の際に観測されるクローラーの1つがOAI-SearchBotです。実際にサーバーログを確認すると、OAI-SearchBotが記事ページへアクセスしているケースを確認できます。
AI観測ラボでも、GPTBotの巡回後にOAI-SearchBotが同じURLへアクセスしている事例を複数回観測しています。
URLを直接渡された場合
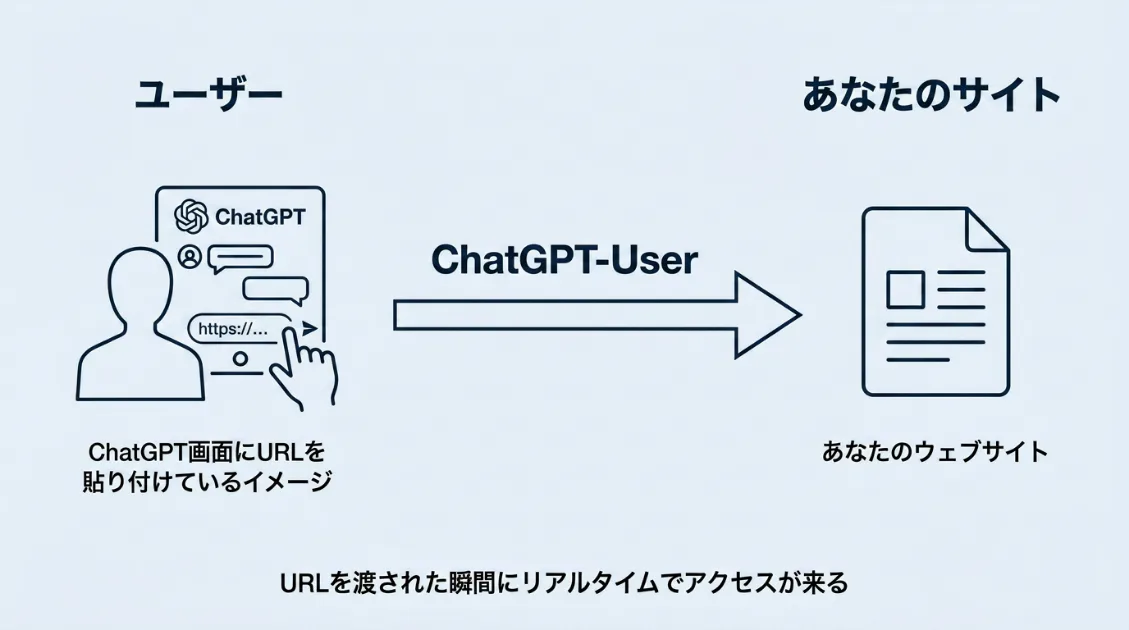
3つ目の経路は、誰かがChatGPTとの会話の中にURLを貼り付けたときです。「このページを要約して」「このサイトの内容を教えて」といった使い方がこれにあたります。
この場合、ChatGPTは指定されたURLの内容を確認するためにページへアクセスすることがあります。学習済みデータやリアルタイム検索とは異なり、特定のページを直接取得するのが特徴です。
サイト運営者の視点から見ると、このアクセスはサーバーログにChatGPT-Userとして記録されます。誰かがChatGPTにサイトのURLを渡した際、短時間のうちにアクセスが発生するケースが確認されています。
AI観測ラボでも継続的にChatGPT-Userのアクセスを観測しています。これは少なくとも誰かがChatGPT経由でページの内容を確認しようとした可能性を示すデータと言えるでしょう。
自分のサイトはChatGPTに読まれているのか確認する方法
ChatGPTがサイトを読みに来たとき、サイトには必ず「来訪記録」が残ります。人間が玄関を通るときに足跡が残るのと同じイメージです。
ただし、この記録はGA4やSearch Consoleには表示されません。サーバーが自動で記録しているアクセスログという別の場所に残ります。
参考として、AI観測ラボの2026年6月時点の実測データを掲載します。
| 経路 | 記録される名前 | 件数 |
|---|---|---|
| URLを直接渡された場合 | ChatGPT-User | 635件 |
| リアルタイム検索 | OAI-SearchBot | 124件 |
| 学習データの収集 | GPTBot | 73件 |
ChatGPT-Userが最も多い結果になりました。記事のURLが誰かのChatGPT上で共有されるたびにアクセスが来るため、コンテンツが人の目に触れている数と比例する傾向があります。
各クローラーの詳しい動きや確認方法は、それぞれの解説記事をご覧ください。
- GPTBotとは—仕組み・設定方法・許可すべきかをログで確かめた
- OAI-SearchBotとは?ChatGPT検索専用クローラーの役割と仕組み
- 誰かがChatGPTにURLを貼った—サーバーログで見えた正体
アクセスログを確認する方法として、Microsoft Clarityが手軽です。無料で導入でき、AI Bot Activityの設定を有効にするだけでAIクローラーの動きを可視化できます。
詳しい設定手順はClarity AI Bot Activity設定と実測データをご覧ください。
サーバーログを直接確認したい場合は、GA4とサーバーログの補完方法も参考にしてください。
まとめ
ChatGPTが情報を持ってくる経路は3つあります。
- 過去に学習した情報(GPTBotが収集)
- 最新情報をリアルタイムで検索する場合(OAI-SearchBotによるアクセスが観測されることがある)
- 誰かがURLを直接渡した場合(ChatGPT-Userがアクセス)
サイトを運営している立場から見ると、この3つはすべてアクセスログに記録として残ります。AI観測ラボでは2026年6月時点でChatGPT-Userが635件、OAI-SearchBotが124件、GPTBotが73件のアクセスを確認しています。
ChatGPTに読まれているかどうかは、GA4やSearch Consoleでは確認できません。検索順位だけでなく、「AIに読まれているか」を確認することも、AI検索時代のサイト運営では重要になってきています。
各クローラーの詳しい動きは、それぞれの解説記事をご覧ください。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。


