GPTBotとは—仕組み・設定方法・許可すべきかをログで確かめた

GPTBotは、OpenAIが運営するウェブクローラーです。ChatGPTなどのAIモデルが回答を生成するための学習データを収集する目的で、世界中のサイトを巡回しています。
では、このGPTBotは「許可すべきか、それともブロックすべきか」。ここが多くのサイト運営者が迷うポイントです。
AI観測ラボのサーバーログを確認したところ、GPTBotは2026年2月末から4月にかけて260件以上アクセスしており、ほぼ毎日巡回していることがわかりました。少なくともAI関連コンテンツを扱うサイトであれば、「GPTBotは来ている」と考えて問題ありません。
この記事では、公式ドキュメントの最新情報とサーバーログの実測データをもとに、GPTBotの仕組みから設定方法、そして「許可・拒否どちらを選ぶべきか」という判断基準まで整理します。
この記事でわかること|📖:約8分
- GPTBotの役割とOAI-SearchBotとの違い
- robots.txtでの許可・拒否の書き方
- 許可すべきか・拒否すべきかの判断基準
- 2026年のサーバーログで確認したGPTBotの実際の動き
GPTBotとは
GPTBotは、OpenAIが開発・運営するウェブクローラーです。クローラーとは、インターネット上のウェブページを自動で巡回してデータを収集するプログラムのことです。Googleが検索結果を作るためにGooglebotを使っているように、OpenAIはAIモデルの学習データを集めるためにGPTBotを使っています。
収集したデータは、ChatGPTなどのAIモデルの精度向上に使われます。OpenAIの公式ドキュメントには「GPTBotによるアクセスを許可することで、AIモデルがより正確になり、安全性の向上にも役立つ」と記載されています。
なお、GPTBotは「許可すべきか・拒否すべきか」で迷われることが多いクローラーですが、結論から言うとサイトの目的によって判断が分かれます(後半で詳しく解説します)。
ただし、以下の3種類のコンテンツは収集対象から除外されます。
- 有料会員向けコンテンツ(ペイウォール)
- 個人を特定できる情報(PII)を含むページ
- OpenAIのポリシーに違反するコンテンツ
User-AgentとIPアドレス
GPTBotはサーバーログ上で以下のUser-Agentで識別できます。AI観測ラボのログでも、同じ文字列での訪問を確認しています。
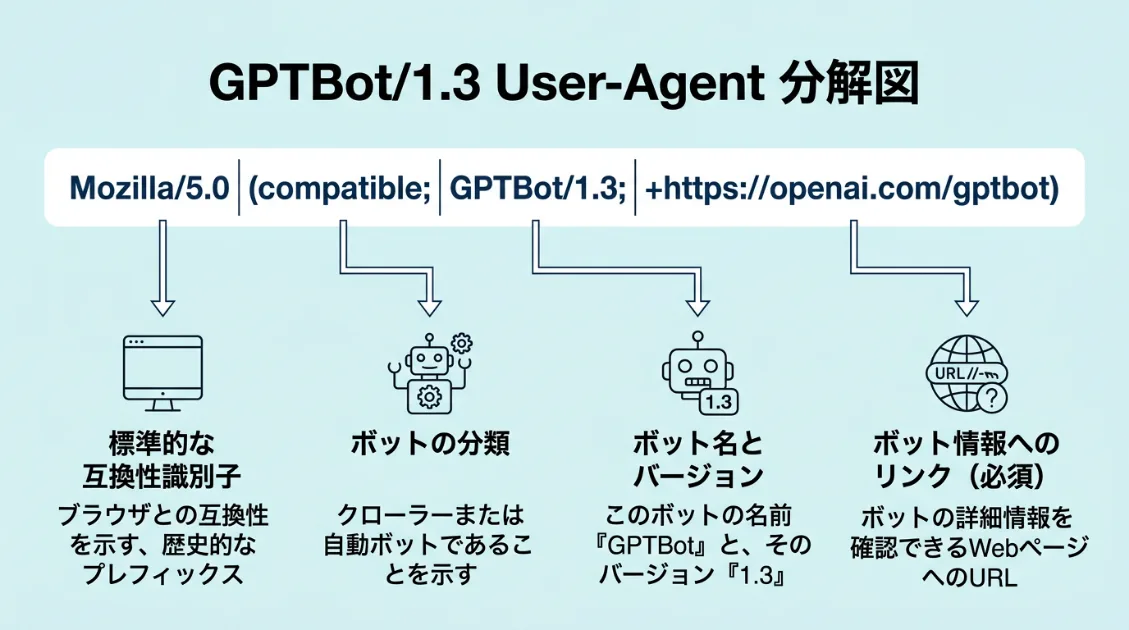
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot)バージョンは現在1.3です。2023年の公開時は1.0でしたが、2026年時点では1.3に更新されています。記事の多くが古いバージョンを掲載したままになっているため注意が必要です。
実際のサーバーログでは、GPTBotは記事単位で定期的に巡回しており、特定のディレクトリに偏るのではなく、サイト全体を横断的にクロールしている傾向が確認されています。
IPアドレスの範囲はOpenAIの公式ページで随時公開されています。ただしIPアドレスは変更される可能性があるため、識別にはUser-Agentを使うほうが確実です。
User-AgentとIPアドレスによるクローラー識別の違いについては、AIクローラーはIPで判定するな—User-Agentを使うべき理由で詳しく解説しています。
また、GPTBotを含むAIクローラー全体の違いや役割については、AIクローラーの種類と役割の違いまとめでも整理しています。
GPTBotの設定方法
GPTBotへの対応は、robots.txtに数行追加するだけで完了します。ただし、重要なのは「どの設定を選ぶか」です。
結論から言うと、AIに引用されたい・将来的な露出を狙う場合は「許可」、コンテンツの流出や学習利用を避けたい場合は「拒否」を選びます。目的に応じて使い分けるのが基本です。
許可・拒否・部分許可の3パターンを順番に説明します。
すべて拒否する場合
サイト全体へのアクセスをGPTBotに許可しない場合は、robots.txtに以下を追加します。
User-agent: GPTBot
Disallow: /上記設定をすると、GPTBotはサイト内のページをクロールしなくなり、AIモデルの学習データにも使われなくなります。
すべて許可する場合
robots.txtに何も書かなければ、デフォルトで許可の状態になります。明示的に許可したい場合は以下のように書きます。
User-agent: GPTBot
Allow: /AIに引用される可能性を広げたい場合や、AI経由の流入を狙う場合はこちらを選びます。
一部だけ許可する場合
特定のディレクトリだけ許可・拒否したい場合は、以下のように組み合わせます。
User-agent: GPTBot
Allow: /blog/
Disallow: /members/上の例では、/blog/配下は許可、/members/配下は拒否という設定です。有料会員向けコンテンツや個人情報を含むページだけ除外したい場合に有効です。
OAI-SearchBotと分けて設定できる
GPTBotとOAI-SearchBotは、robots.txtで独立して設定できます。たとえば「ChatGPT検索には載りたいがAI学習には使われたくない」という場合は、以下のように書き分けます。
User-agent: GPTBot
Disallow: /
User-agent: OAI-SearchBot
Allow: /OpenAIの公式ドキュメントでは、両方を許可している場合、重複クロールを避けるために1回のクロール結果を共有するケースがあるとされています。目的に応じて適切に使い分けることが重要です。
OAI-SearchBotについては、OAI-SearchBotとは?GPTBotと何が違うのかをまとめましたで詳しく解説しています。
WordPressでの確認方法
WordPressの場合、Yoast SEOを使っているとrobots.txtをダッシュボードから編集できます。「SEO」→「ツール」→「ファイルエディター」から確認・編集が可能です。
robots.txtの書き方全般については、robots.txtでAIクローラーにどう見せるか—コピペで使える設定例つきにまとめています。
GPTBotは2026年現在も来ているのか
結論から言うと、GPTBotは2026年現在も継続的にサイトを巡回しています。AI観測ラボのサーバーログでも、2026年2月末から4月にかけて合計260件以上のアクセスを確認しており、ほぼ毎日訪問している状態です。
少なくともAI関連のコンテンツを扱っているサイトであれば、「GPTBotはすでに来ている」と考えて問題ありません。
ここでは実際のサーバーログをもとに、GPTBotのアクセス頻度と挙動を具体的に見ていきます。
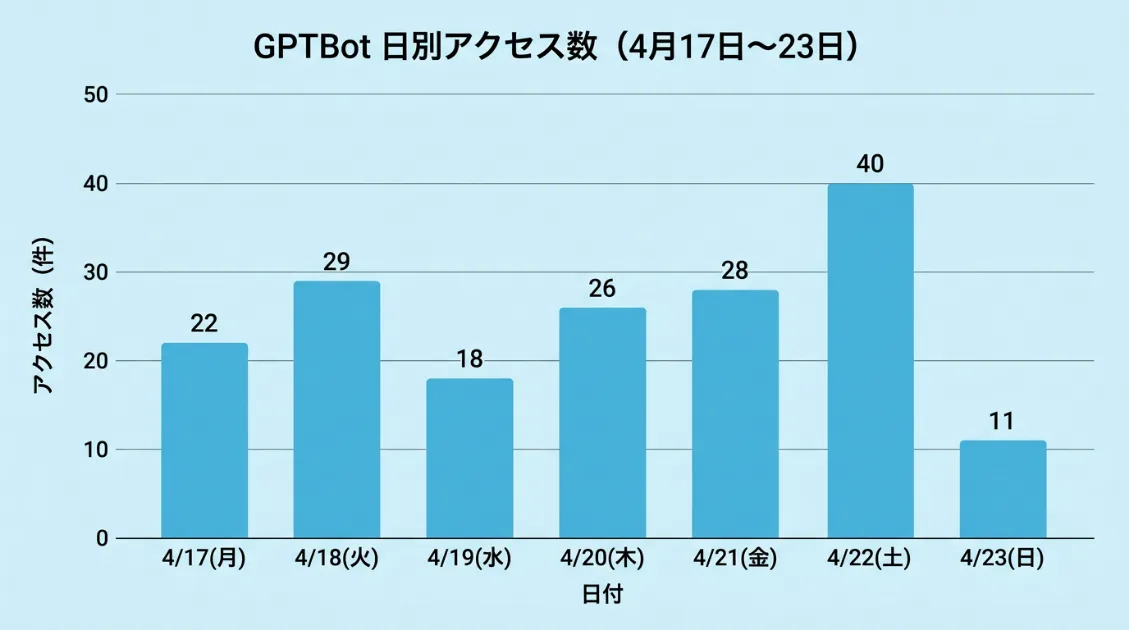
日別のアクセス数(2026年4月)
| 日付 | アクセス数 |
|---|---|
| 4月17日 | 22件 |
| 4月18日 | 29件 |
| 4月19日 | 18件 |
| 4月20日 | 26件 |
| 4月21日 | 28件 |
| 4月22日 | 40件 |
| 4月23日 | 11件 |
| 合計 | 174件 |
日ごとのばらつきはあるものの、一定の頻度で継続的に巡回していることがわかります。
どのページを読んでいるか
アクセス先を確認すると、GPTBotが最も多く訪問したページは「AIクローラーの種類と目的を比べてみた」という記事で50件でした。次いでGPTBotの挙動を記録した実験記事が28件です。
GPTBot自身やAIクローラーに関する記事を優先的に巡回している傾向があり、「テーマの関連性が高いページほどクロールされやすい」可能性が示唆されます。
また、サイトへの最初のアクセスはほぼ毎回sitemapの確認から始まっています。sitemap_index.xmlへのアクセスが14件記録されており、sitemapを起点に記事ページへ到達するパターンが繰り返されています。
つまりは、GPTBotはランダムに巡回しているのではなく、サイト構造を理解したうえでクロールしている可能性が高いと考えられます。
GPTBotがsitemapをどう使って記事ページに到達するかは、GPTBotはサイトマップを3回確認してからクロールしていた【AI実験室 #15】で詳しく記録しています。
GPTBotは許可すべきか、拒否すべきか
結論から言うと、GPTBotは「サイトの目的」によって許可・拒否を使い分けるのが最適です。
AIに引用される機会を増やしたい場合は許可、コンテンツの流出や学習利用を避けたい場合は拒否を選びます。単純な二択ではなく、「どこまで公開するか」という設計の問題です。
AI観測ラボのサーバーログで確認した実測データも含めて、それぞれの違いを整理します。
許可した場合に起きること
GPTBotを許可すると、収集したコンテンツがOpenAIのAIモデルの学習データとして使われる可能性があります。直接的なSEO効果はありませんが、ChatGPTがそのサイトの情報を学習することで、AI検索での引用につながるケースがあります。
AI観測ラボでGPTBotを許可した状態で運営したところ、7日間で174件のアクセスを確認しました。GPTBotは記事ページだけでなく、sitemapやタグページも巡回しており、サイト構造全体を把握しようとする動きが見られました。
AI経由の露出を狙う場合、このクロールを止めてしまうと「そもそも認識されない」という状態になる可能性があります。
拒否した場合に起きること
GPTBotをrobots.txtで拒否すると、OpenAIのAIモデル学習への提供を止めることができます。ただし、OAI-SearchBotとは独立した設定なので、GPTBotだけ拒否してもChatGPT検索への表示には直接影響しません。
一方で、AIに学習されないことで将来的な引用機会を失う可能性もあります。
拒否を検討すべきサイトの例は以下のとおりです。
- 有料会員向けコンテンツを抱えているサイト
- 著作権上の理由でデータ提供を避けたいサイト
- 個人情報を多く含むサイト
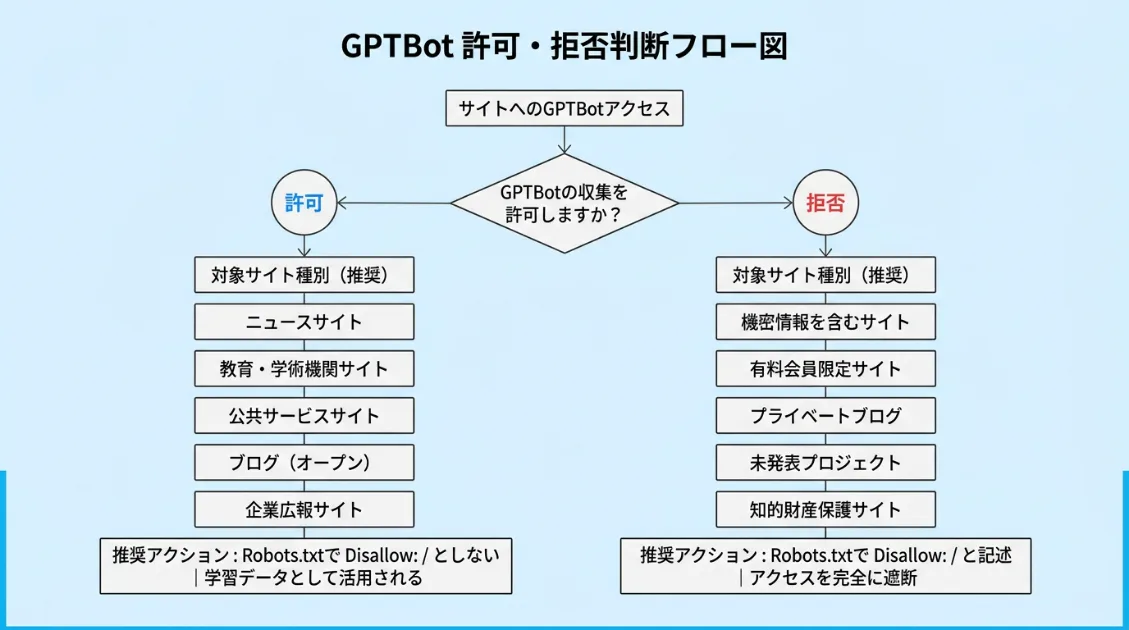
判断の基準
判断に迷う場合は、以下の基準で考えると整理しやすくなります。
| サイトの状況 | 推奨設定 |
|---|---|
| 情報発信・ブログ・メディア | 許可(AI引用の機会を増やす) |
| EC・有料コンテンツあり | 部分許可(公開ページのみ許可) |
| 個人情報・機密情報を含む | 拒否 |
| 著作権コンテンツが中心 | 拒否 |
迷った場合は「公開しても問題ないページだけ許可する」という部分許可から始めるのが安全です。
AIクローラーを許可すべきか拒否すべきかの全般的な考え方は、AIクローラーを拒否する前に知っておくべきことで詳しく解説しています。
GPTBotとOAI-SearchBotの違い
結論から言うと、GPTBotとOAI-SearchBotは「まったく別の役割を持つクローラー」です。
特に重要なのは、GPTBotを拒否してもOAI-SearchBotを許可していれば、ChatGPT検索には表示されるという点です。逆にOAI-SearchBotを拒否すると、検索結果に表示されなくなります。
この2botの違いを理解していないと、「AIに出ない原因」を見誤ることになります。
| GPTBot | OAI-SearchBot | |
|---|---|---|
| 目的 | AIモデルの学習データ収集 | ChatGPT検索への表示 |
| トリガー | 自動・定期巡回 | ユーザーの検索クエリ |
| 拒否した場合の影響 | 学習データに使われない | ChatGPT検索に表示されない |
| robots.txtタグ | GPTBot | OAI-SearchBot |
GPTBotとOAI-SearchBotの設定は完全に独立しているため、目的に応じて個別に制御することができます。
- AIに学習されたくない → GPTBotを拒否
- ChatGPT検索に表示したい → OAI-SearchBotを許可
また、OpenAIの公式ドキュメントには、両方を許可している場合、重複クロールを避けるために1回のクロール結果を両方の用途に使う場合があると記載されています。
サイト負荷の観点から、基本は両方許可しつつ必要に応じて制御するのが現実的です。
AI観測ラボのログでは、OAI-SearchBotは7日間で46件のアクセスを記録しており、GPTBotとは異なるIPアドレスから独立して巡回していることが確認できています。
OAI-SearchBotの挙動や設定方法の詳細は、OAI-SearchBotとは?GPTBotと何が違うのかをまとめましたで解説しています。
よくある質問
GPTBotとは何ですか?
GPTBotは、OpenAIが運営するウェブクローラーで、AIモデルの学習データを収集するためにサイトを巡回します。
GPTBotをブロックしたらChatGPTに引用されなくなりますか?
いいえ、直接は影響しません。ChatGPT検索への表示はOAI-SearchBotが担当しているため、GPTBotをブロックしても検索結果には表示される可能性があります。
GPTBotは許可すべきですか?
AIに引用される可能性を高めたい場合は許可、コンテンツの学習利用を避けたい場合は拒否します。サイトの目的に応じて判断します。
GPTBotはSEOに影響しますか?
直接的なSEO順位への影響はありません。ただしAI検索での引用や露出には間接的に影響する可能性があります。
GPTBotはHTTP/1.1とHTTP/2.0のどちらで来ますか?
AI観測ラボのサーバーログでは、GPTBotはHTTP/2.0でアクセスしていることを確認しています。
GPTBotが404を踏んでいる場合はどうすればいいですか?
301リダイレクトで正しいURLに誘導するか、sitemapを最新の状態に更新することで改善できます。
GPTBotのバージョンは現在いくつですか?
2026年4月時点では、GPTBot/1.3でのアクセスが確認されています。
robots.txtを設定していない場合、GPTBotは来ますか?
はい、来ます。robots.txtで拒否しない限り、デフォルトでアクセスされます。
まとめ
GPTBotはOpenAIが運営するAIモデル学習用のクローラーで、2026年現在も継続的にサイトを巡回しています。AI観測ラボのログでは、7日間で174件、2月末からの累計で260件以上のアクセスを確認しました。
対応の結論はシンプルです。AIに引用される可能性を広げたい場合は許可、コンテンツの流出や学習利用を避けたい場合は拒否または部分許可を選びます。
GPTBotとOAI-SearchBotは独立して制御できるため、「学習は拒否するが検索には出す」といった設計も可能です。サイトの目的に合わせて設定を調整することが重要です。
まずはrobots.txtの設定を確認し、「許可・拒否どちらにするか」を決めるところから始めてみてください。
GPTBotの挙動をさらに詳しく知りたい場合は、以下の記事で実測データをもとに解説しています。
- GPTBotはサイトマップを3回確認してからクロールしていた【AI実験室 #15】—48時間の全行動を記録
- GPTBotはなぜ記事本文を読まないのか—「sitemap巡回型」の正体—サイトマップ中心の行動パターンを解説
- AIクローラーの種類と目的を比べてみた—実測データで見えた各ボットの動き方—GPTBot・OAI-SearchBot・PerplexityBotの比較
- AIクローラーは全員違う動きをしていた—4社の行動パターンをサーバーログで比較した結果【AI実験室 #13】—4社横断の比較
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。