AIクローラーは記事より先に運営者情報を読む?llms.txt・trust.txtの巡回ログを実測

AIアシスタントに相談していると、回答の中に参照リンクが表示されることがあります。
ところが、そのリンクを実際に開いてみると、内容がまったく関係なかったり、404エラーが表示されたりすることがあります。GeminiやChat GPTでも同じような現象が確認されており、AIが誤った情報源を参照してしまうリスクは、AI検索の普及とともに無視できない問題になりつつあります。
さらに近年では、AI検索やAI要約を意識して、意図的に情報設計を行うサイトも増えてきました。もしAIが信頼性の低い情報源を正しいサイトとして認識してしまえば、その誤りが多くのユーザーへ広がっていく可能性もあります。
AI観測ラボでは、こうした状況を受けて一つの疑問を持ちました。
「そもそもAIクローラーは、サイトの信頼性をどこで判断しているのだろうか?」
答えを探るためにサーバーログを調査したところ、興味深い巡回パターンが見えてきました。AIクローラーは記事ページにたどり着く前に、特定のページを優先的に確認しているようなのです。
この記事でわかること|📖:約5分
- AIクローラーが記事より先に確認していたページの実測データ
- クローラーごとに異なる「サイト理解」の巡回パターン
- trust.txt・security.txtとは何か、なぜ注目されているのか
- 現時点での仮説と、今後の観測方針
見慣れない巡回に気づいた
AI観測ラボでは、日々サーバーログを確認しながら、AIクローラーの巡回パターンを観測しています。
そんな中、ある日ひとつの違和感に気づきました。
AIクローラーが記事ページではなく、お問い合わせページや運営者情報ページを先に確認しているような動きが見えたのです。しかも、その動きは特定のクローラーだけではなく、複数のAIクローラーで共通していました。
最初は偶然かとも思いました。しかし、ログを日をまたいで確認しても、似たような巡回パターンが繰り返されていました。記事ページへ到達する前に、サイトの「顔」にあたるページを確認しているようにも見えます。
いったい何を意味しているのか。そこから、AI観測ラボの調査が始まりました。
実際に何を見に来ていたのか
2026年5月13日のサーバーログを詳しく調査したところ、各AIクローラーが確認していたページの傾向が見えてきました。
| クローラー | 確認していたページ | 件数 |
|---|---|---|
| PerplexityBot | /operator-info/・/contact/・/glossary/・/start-guide/ | 各4件 |
| GPTBot | /operator-info/ | 4件 |
| Bingbot | /author/admin/page/2〜9 | 複数件 |
| ChatGPT-User | /llms.txt | 直接取得 |
PerplexityBotは、運営者情報・連絡先・用語集・スタートガイドといった、サイト全体の概要を把握するためにも見えるページを一通り確認していました。GPTBotは運営者情報ページに絞ってアクセスしています。
Bingbotは著者ページを2ページ目から9ページ目まで順番に巡回しており、ChatGPT-Userはllms.txtを直接取得していました。
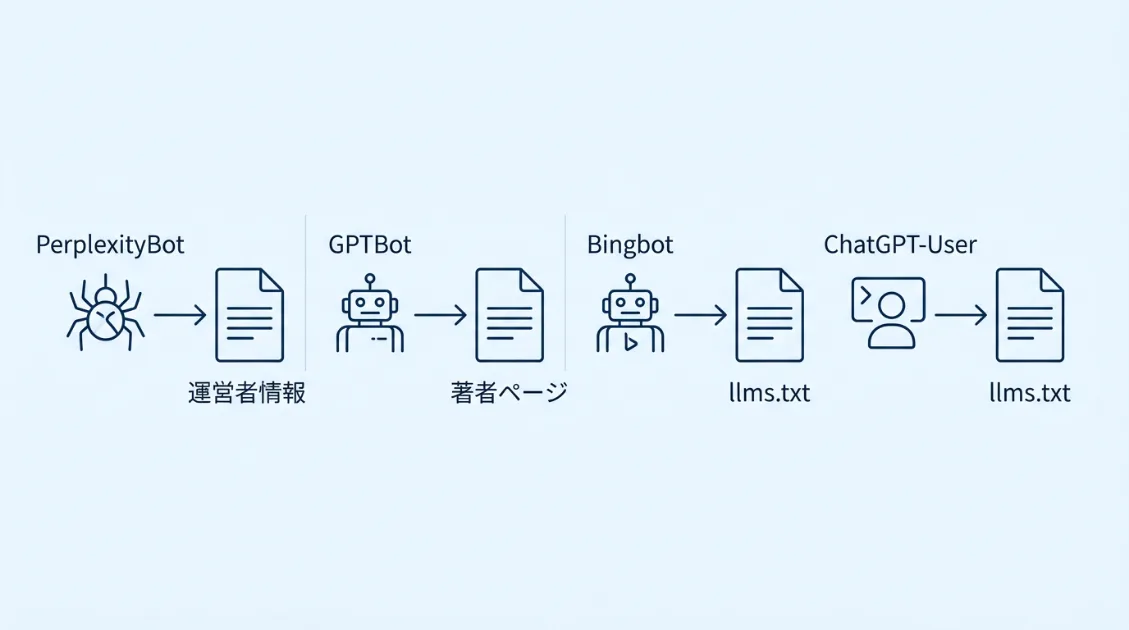
クローラーごとに巡回の目的や挙動は異なります。しかし共通していたのは、記事本文だけではなく、サイトの構造や運営情報に関係するページも確認していたという点でした。
共通していたのは「サイト説明ページ」
クローラーごとに確認するページは異なります。しかし、ひとつ注目すべき共通点がありました。
それは、どのクローラーも「このサイトは何者か」を説明するページを先に確認しているように見えたという点です。
運営者情報・お問い合わせ・著者ページ・llms.txt——これらはすべて、サイトの運営主体や専門性を説明するためのページです。記事そのものではなく、「誰が・何の目的で・どんな情報を発信しているサイトか」を伝える役割を持っています。
たとえば図書館で本を選ぶとき、多くの人は最初に表紙や著者プロフィールを確認してから中身を読み始めます。AIクローラーも、それに近い順番でサイトを理解しようとしている可能性があります。
特に興味深かったのはllms.txtへのアクセスです。llms.txtは、AIクローラー向けにサイト概要や構造を説明するためのファイルです。AI観測ラボでも設置していますが、ChatGPT-Userはこのllms.txtを直接取得していました。
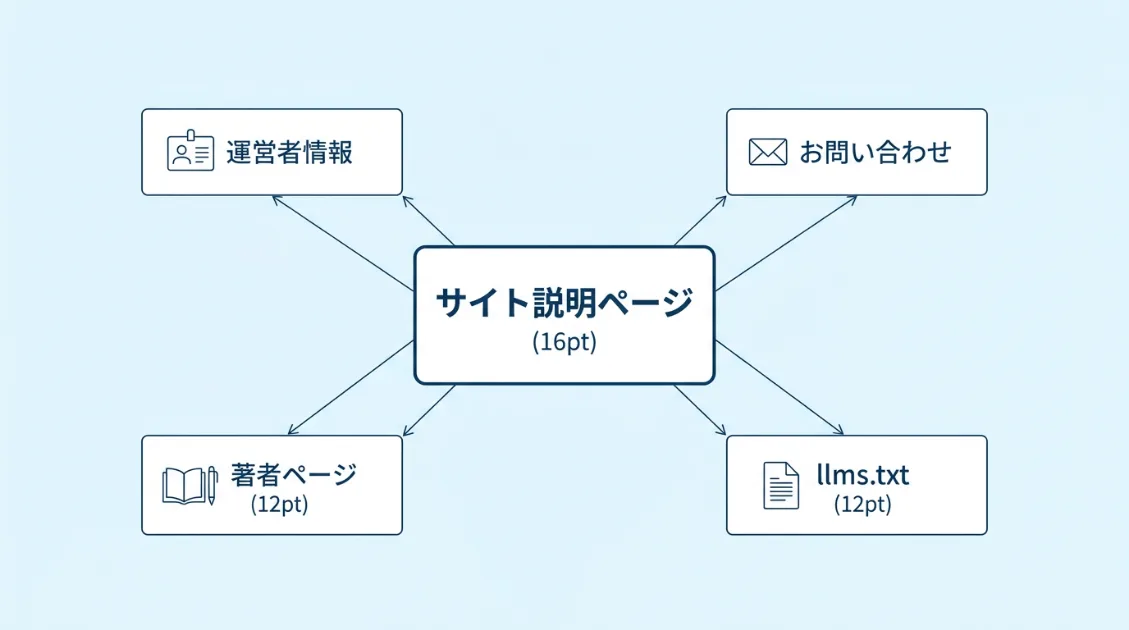
これは、記事本文へ到達する前に、まずサイト全体の構造や方針を確認しようとしていた動きにも見えます。
もちろん、これがAI側の「信頼性評価」と直接結びついているかは現時点では分かっていません。ただ、記事ページより先にサイト説明ページを確認するパターンが、複数のクローラーで共通していたという事実は、観測として記録しておく価値があると感じています。
AIは記事の前に「サイト理解」をしている可能性
なぜAIクローラーはサイト説明ページを優先的に確認するのでしょうか。現時点では仮説の段階ですが、いくつかの可能性が考えられます。
仮説①:サイト全体の文脈を把握してから記事を読む
人間でも、初めて訪れたサイトでは「このサイトは何をしているのか」を最初に確認することが多いと思います。AIクローラーも、記事単体ではなく、サイト全体の文脈を把握した上でコンテンツを理解しようとしている可能性があります。
llms.txtやoperator-infoのような「サイト概要ページ」を先に確認することで、個々の記事の専門性や位置づけを理解しやすくなるとも考えられます。
仮説②:運営主体の確認が巡回の起点になっている
GPTBotとPerplexityBotがどちらも運営者情報ページを確認していたのは、偶然ではないかもしれません。AI検索やAI要約に利用する情報として、「誰が発信しているか」という情報を重視している可能性があります。
E-E-A-T(経験・専門性・権威性・信頼性)はGoogle検索でも重視されていますが、AIクローラー側でも似たような視点でサイト全体を把握しようとしている可能性があります。
仮説③:著者ページの巡回は人物情報の確認かもしれない
Bingbotが著者ページを2ページ目から9ページ目まで順番に巡回していたのも興味深い動きです。著者一覧を継続的に巡回していたことから、サイトに関わる人物情報を収集している可能性も考えられます。
ただし、これらはあくまで観測データから導いた仮説です。「AIクローラーが信頼性を評価している」と断定できる根拠を、現時点ではまだ持っていません。
今回確認できたのは、「記事本文より先にサイト説明ページを確認しているような巡回パターンが複数存在していた」という観測結果です。
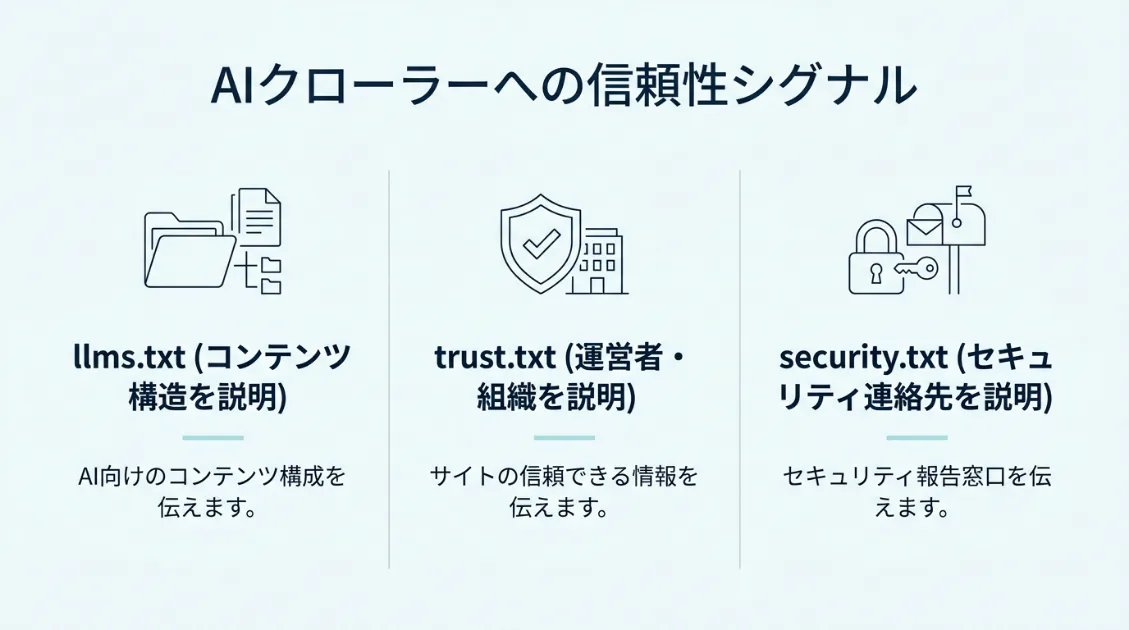
trust.txt・security.txtとは何か
サイトの信頼性をAIクローラーへ伝える仕組みとして、近年注目され始めているファイルが2つあります。trust.txtとsecurity.txtです。どちらも/.well-known/ディレクトリに設置するテキストファイルです。
security.txtとは
security.txtは、サイトのセキュリティに関する連絡先情報を記載するファイルです。もともとは、セキュリティ研究者が脆弱性を発見した際に、どこへ報告すればよいかを示す目的で作られました。
記載内容には、担当者のメールアドレス・連絡先の有効期限・PGP公開鍵などがあります。RFC 9116として標準化されており、海外を中心に企業サイトでの採用も進んでいます。
AIクローラーとの直接的な関係は明らかになっていません。ただ、security.txtの存在によって、サイト運営体制や管理意識を機械的に把握しやすくなる可能性はあります。
trust.txtとは
trust.txtは、サイトの運営主体・所属組織・関連サイトなどを記載するファイルです。security.txtより新しい概念で、日本語での解説記事はまだ多くありません。
たとえば、「このサイトは○○という組織が運営しています」「関連サイトはこちらです」といった情報を、機械が読み取りやすい形式で記載します。
AIクローラーがサイトの運営主体や関係性を把握するための補助情報として利用される可能性もあり、今後注目されるファイルのひとつと考えられます。
llms.txtがAIクローラー向けに「サイトのコンテンツ構造」を説明するファイルだとすれば、trust.txtは運営者・組織・信頼性の文脈を補足するためのファイルと整理できます。
AI観測ラボでは、2026年5月13日にtrust.txtとsecurity.txtを/.well-known/へ設置しました。
設置直後のサーバーログでは、security.txtに4件・trust.txtに1件のアクセスが確認されています。ただし、これは設置前に404として記録されていたアクセスであり、設置後の観測データは現在蓄積中です。
まだ仮説段階だが、観測価値は高い
今回のログ調査で見えてきたのは、AIクローラーが記事ページより先にサイト説明ページを確認しているような巡回パターンです。
しかしながら確認した巡回パターンが「AI側の信頼性評価」と直接結びついているかどうかは、現時点では断定できません。
慎重に見るべき理由は、大きく3つあります。
理由①:各クローラーの巡回ロジックは非公開
PerplexityBot・GPTBot・Bingbotが、どのような優先順位でページを巡回しているのかは公開されていません。サーバーログから動きは観測できますが、背景にあるアルゴリズムまでは確認できません。
理由②:サンプル数がまだ少ない
今回の調査は、2026年5月13日のログを中心に確認したものです。日によって巡回パターンが変化する可能性もあるため、継続的な観測が必要になります。
理由③:trust.txt・security.txtの設置効果はこれから
trust.txtとsecurity.txtを設置したのは2026年5月13日です。設置後にクローラーの巡回パターンがどう変化するかについては、まだ十分なデータがありません。
設置前後でどのような違いが出るのかを比較できるようになるには、もう少し観測期間が必要です。
とはいえ、複数のAIクローラーが共通してサイト説明ページを確認していたという事実は、観測データとして記録しておく価値があります。
AI検索が普及するにつれて、「AIがどのように情報源を理解しようとしているのか」は、サイト運営者にとって重要なテーマになっていく可能性があるからです。
AI観測ラボでは、「AIクローラーは信頼性を評価している」と断定するのではなく、「信頼性を確認しているように見える巡回パターンが存在していた」という段階で記録を続けていきます。
現在設置して継続観測中
AI観測ラボでは、今回の調査結果を受けて、trust.txtとsecurity.txtを/.well-known/ディレクトリへ設置しました。
現在設置しているファイルの内容は以下のとおりです。
設置したファイル
- security.txt:セキュリティに関する連絡先・有効期限を記載
- trust.txt:サイトの運営主体・関連サイト・運営目的を記載
設置前のサーバーログでは、/.well-known/security.txtに4件、/.well-known/trust.txtに1件の404アクセスが記録されていました。
つまりは、ファイルが存在しない状態でも、クローラー側がアクセスを試みていたことになります。
設置後にアクセスパターンがどう変化するのか、どのクローラーがどのタイミングで取得しに来るのかについて、引き続きログを観測していきます。
今後の観測ポイント
- trust.txt・security.txt設置後にアクセスしてくるクローラーの種類が増えるか
- 設置前後で運営者情報ページへの巡回パターンに変化があるか
- llms.txtと合わせてサイト説明ファイルを揃えることで巡回頻度が変化するか
観測データが十分に蓄積された段階で、続編として改めて報告する予定です。
AIがサイトをどのように理解しようとしているのか。その入口にある巡回パターンを、AI観測ラボでは引き続き追いかけていきます。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。


