AIに引用されるサイト・されないサイトの境界線—10の実験でわかったこと

「AIに引用されてないのに、原因がわからない」
サイトを作って、記事を書いて、robots.txtも設定した。それでもAIに引用されない。そんな相談が毎週増えています。
AI観測ラボでは2026年1月から現在まで、サーバーログ全量を使ってAIクローラーの挙動を実測してきました。GPTBot、ClaudeBot、PerplexityBot、Applebot——クローラーごとに動き方を記録し、10本以上の実験記事としてまとめてきました。
実験を重ねるうちに、見えてきたことがあります。AIに引用されるかどうかは、2つの壁を越えられるかどうかで決まります。
第一の壁:AIクローラーに読まれるか
第二の壁:読まれたコンテンツが選ばれるか
多くのサイトが「第二の壁」の対策(コンテンツの質・構造化データ)に集中しています。ただ、実測データでは大半のサイトが「第一の壁」でつまずいていました。
今日から直せる順に、10の実験データで境界線を整理します。
この記事でわかること|📖:約8分
- AIに引用されるかどうかは「読まれる前」と「読まれた後」の2段階で決まること
- SPA構造・クロール深度・サイトマップなど、第一の壁でつまずく代表的なパターン
- llms.txt・SNS・モバイル対応など、効果がないと実測でわかったこと
- Applebotだけが持つ特殊な挙動と、今から対応すべき理由
第一の壁:AIクローラーに読まれているか
コンテンツの質を上げる前に、そもそもAIクローラーがサイトを読めているかどうかを確認する必要があります。実測データで繰り返し見えてきたのは、「読まれていない」状態のまま構造化データを頑張って書いているサイトの多さでした。
1. SPA構造のサイトは、AIクローラーに読まれていない
WebflowやFramer、Wixなどのノーコードツールで作ったサイトの多くは、SPA(シングルページアプリケーション)という構造を採用しています。SPAはブラウザがJavaScriptを動かして画面を組み立てる仕組みで、見た目はきれいに表示されます。
ただ、AIクローラーの大半はJavaScriptを実行しません。HTMLをそのまま取得して終わりです。JavaScriptで組み立てる前の状態、つまりコンテンツが何も入っていないHTMLだけを持ち帰ります。
サーバーログで確認したところ、SPA構造のサイトに対してGPTBotやClaudeBotがアクセスしても、本文テキストをほぼ取得できていないことが判明しました。どれだけ質の高いコンテンツを書いても、AIクローラーには「空のページ」として映っています。
今すぐできる確認: ご自身のサイトを「ページのソースを表示」で開いて、本文がHTML内にベタ書きされてるか見てください。空なら要注意です。
Framer・Webflow・Wixを使っているサイトは、SSR(サーバーサイドレンダリング)への切り替え、またはHTMLサイトマップの整備が現実的な対策になります。
→ 詳しくはノーコードツールで作ったサイト、AIに読まれていますか?で実測データをまとめています。
2. AIクローラーのクロール深度は、思ったより浅い
「記事をたくさん書けばAIに読まれる」と考えているサイト運営者は多いです。ただ、AIクローラーがサイトの何階層目まで潜るかは、想像より浅いことが実測でわかっています。
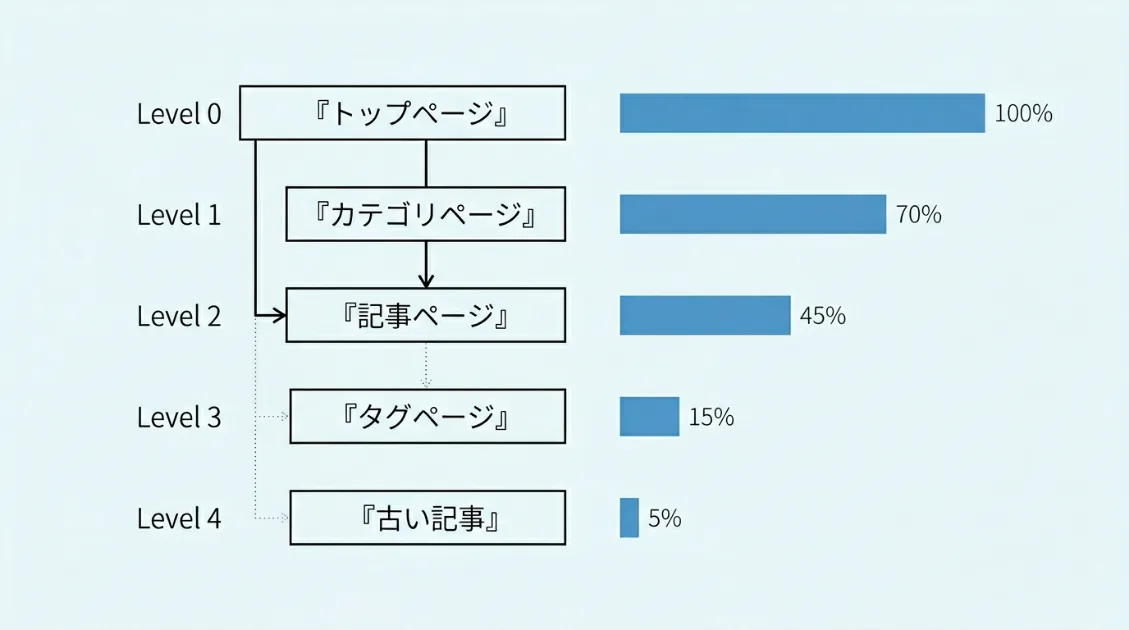
8日間・610件のアクセスログを分析したところ、GPTBotとPerplexityBotのクロールはトップページから2〜3階層以内に87%が集中していました。カテゴリページや古い記事は、そもそもクローラーが到達していないケースが大半です。
階層が深い記事は、新着記事なのにどれだけ内容が良くても「存在していない記事」と同じ扱いになります。サイト設計の段階で、重要な記事をトップページや主要カテゴリから2クリック以内に置く構造が必要です。
また、内部リンクの少ない孤立した記事もクローラーに発見されにくい傾向がありました。記事公開直後に、既存の人気記事から内部リンクを3本以上設置することが、クロール到達率を上げる現実的な方法です。
→ 詳しくはAIクローラーは何階層まで潜るのか—GPTBot・PerplexityBot・Googlebot実測比較で実測データをまとめています。
3. サイトマップへの到達率は、クローラーによってバラバラ
「サイトマップを送信すれば、AIクローラーが全ページを読んでくれる」と思っているサイト運営者は多いです。ただ、実測ではクローラーによってサイトマップへの到達率に大きな差があることがわかっています。
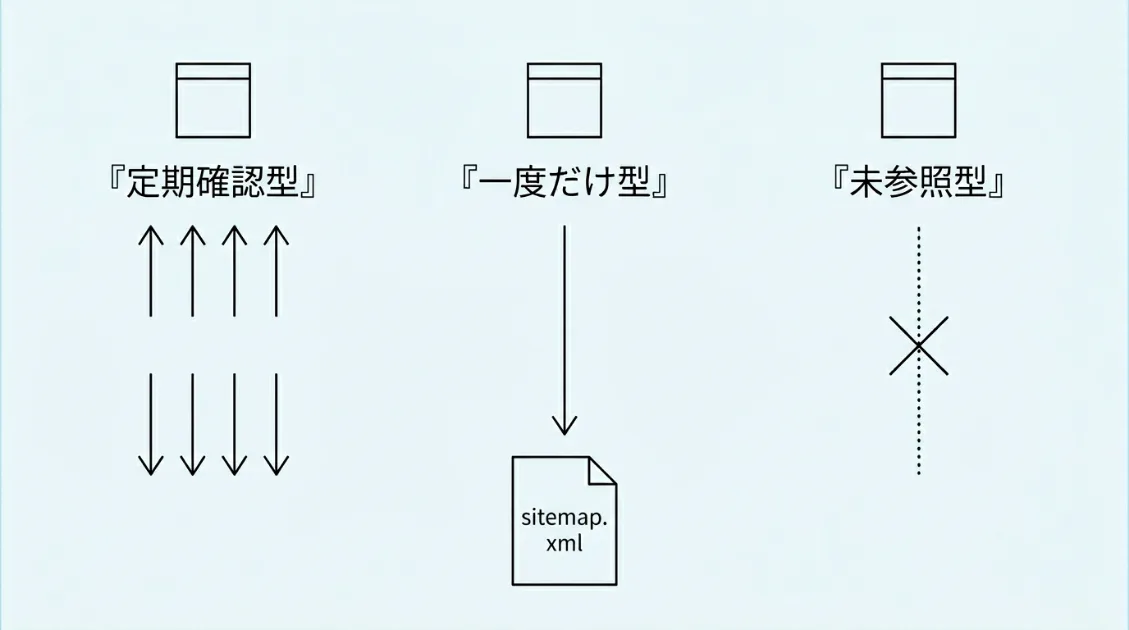
WordPressのサイトマップ(sitemap.xml)へのアクセスログを分析したところ、3つのパターンが見えてきました。Googlebotのように定期的に確認するクローラー、PerplexityBotのように一度だけ確認して以降は来ないクローラー、そしてGPTBotのようにサイトマップをほぼ参照しないクローラーです。
サイトマップを送信していても、GPTBotにはサイトの存在自体が伝わっていない可能性があります。サイトマップに頼りきった設計だと、主要なAIクローラーに読まれないままになります。
サイトマップの整備は必要ですが、それだけでは不十分です。特に新規ドメインや記事数が少ないサイトは、トップページや主要記事からの内部リンクを充実させることが、サイトマップに頼らないクロール経路の確保につながります。
→ 詳しくはWordPressのsitemapはAIクローラーに届いているかで実測データをまとめています。
4. robots.txtを無視するクローラーが存在する
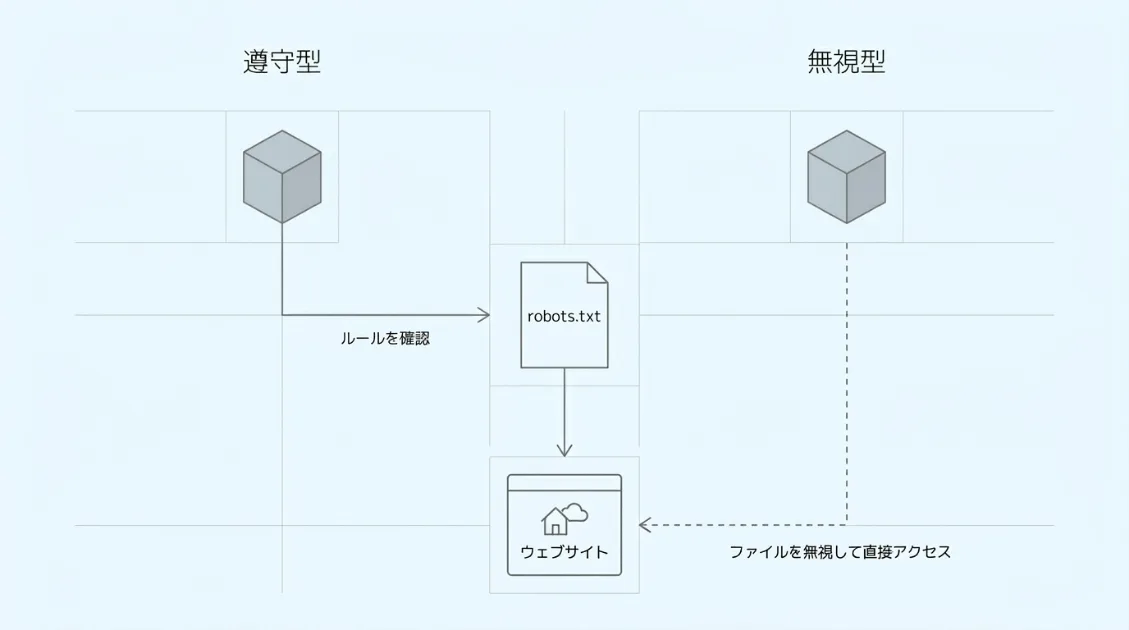
robots.txtはクローラーへのアクセス制御の基本で、アクセス拒否の最終防衛ラインです。「Disallowを書けば来なくなる」と思っているサイト運営者がほとんどだと思います。ただ、実測では robots.txt の指示を無視するクローラーの存在が確認できています。
TikTokを運営するByteDance社のクローラー「ByteSpider」は、robots.txtでDisallowを設定していても関係なくアクセスしてきます。Doubao(ByteDanceが開発した中国版ChatGPT)の学習データ収集が目的とされており、世界中のサイトに1日数千リクエスト送り続けています。
GPTBotやClaudeBotはrobots.txtをきちんと確認してからアクセスしてきます。ただ、ByteSpiderのように無視するクローラーも存在するため、「robots.txtを書いたから大丈夫」という前提は崩れています。
海外からの大量アクセスでサーバー負荷が上がっている場合は、robots.txtだけに頼らず、Cloudflareのボット管理機能やサーバー側のアクセス制限を組み合わせることが、確実なクロール制御につながります。
→ 詳しくはAIクローラーの許可・拒否設定【robots.txt実例付き】とByteSpiderとは?世界最多リクエストのAIクローラーをログで調べたで実測データをまとめています。
第二の壁:読まれたコンテンツが選ばれるか
AIクローラーに読まれても、引用されるとは限りません。「読まれた後」にも壁があります。ただ、実測データで見えてきたのは「効果があると思われていた対策が、実は引用に関係していなかった」というケースの多さでした。
5. llms.txtはAIクローラーに読まれていない
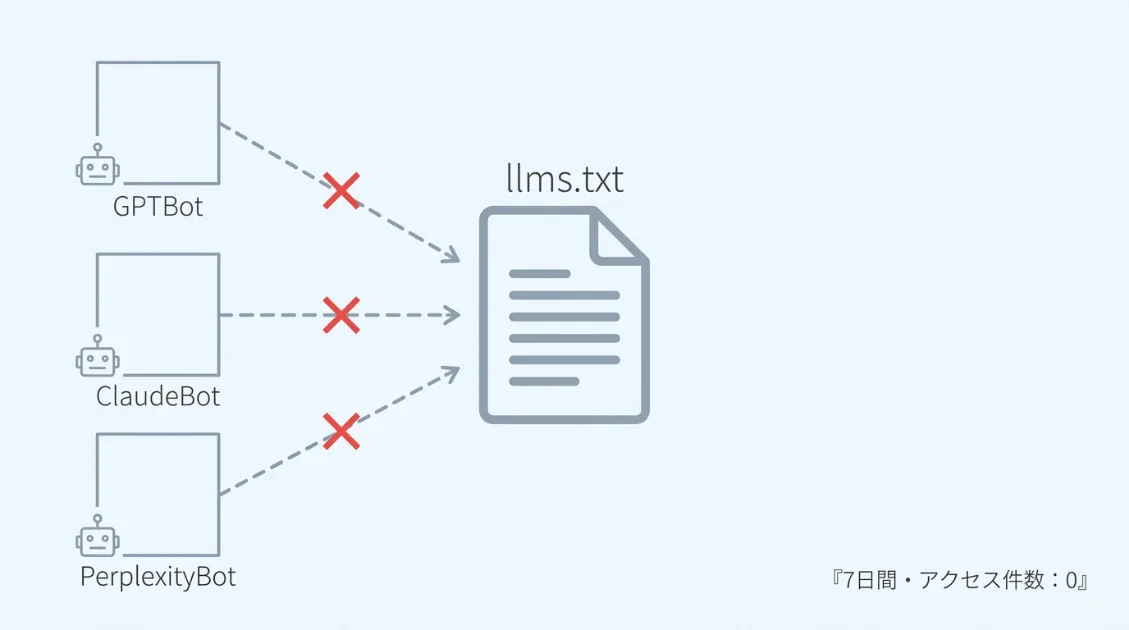
llms.txtはAIクローラー向けにサイトの情報をまとめたファイルで、2025年末から急速に「設置すればAIに読まれやすくなる」と広まっています。ただ、実測では異なる結果が出ています。
llms.txtを設置して7日間のサーバーログを確認したところ、ChatGPT・Claude・Perplexityの主要3社いずれもllms.txtにアクセスした記録がありませんでした。クローラーはllms.txtを無視して、通常の記事ページを直接クロールしていました。
llms.txtの設置自体は悪くありません。ただ、「設置したから大丈夫」というAI対策やった感で他の対策が後回しになるのは避けるべきです。現時点では、llms.txtよりもrobots.txtの設定やサイト構造の整備が優先度の高い対策です。
→ 詳しくはllms.txtを設置し7日間のサーバーログを見たが、AIクローラーは誰も読んでいなかった【AI実験室 #04】で実測データをまとめています。
6. SNSをいくら頑張っても、AI引用には関係ない
「SNSでバズれば、AIにも引用されやすくなる」と考えているサイト運営者は多いです。ただ、実測では SNSの拡散とAI引用のあいだに関係は見られませんでした。
86,000件のAIクローラーアクセスを分析したところ、1万リツイート超えの記事でもAIクローラーのアクセス頻度に影響を与えた形跡はありませんでした。SNSでシェアされた記事が優先的にクロールされる、といった傾向も確認できませんでした。
そもそもXやInstagramのHTMLソースはAIクローラーがコンテンツを読み取れない構造になっています。被リンク目的でSNSに投稿しているなら、SNS上の言及がAIクローラーの巡回経路に組み込まれている可能性は低く、現時点では根拠が薄い状態です。
SNS運用はブランド認知や人間へのリーチには有効です。ただ、AI対策としてSNSを頑張るのは、工数の無駄遣いになる可能性が高いです。AIクローラーはSNSではなく、サイト本体のコンテンツと構造を見ています。
→ 詳しくはSNSをいくら頑張ってもAIには引用されない—86,000件の分析でわかった現実とXもInstagramもAIに読まれていない—SNS4社のHTMLソースを比べてみたで実測データをまとめています。
7. モバイル対応は、AI引用に直結しない
「モバイル対応していないサイトはAIにも評価されない」という話をよく見かけます。Googleの検索評価ではモバイル対応が重要な指標になっているため、AI引用でも同じだと思われがちです。ただ、実測では異なる結果が出ています。
GPTBotとClaudeBotのアクセスログを分析したところ、PC版のHTMLしかない古いサイトでも両クローラーともアクセス頻度に変化はありませんでした。AIクローラーはスマートフォンのブラウザではなく、HTMLを直接取得する仕組みで動いているため、モバイル用とPC用でHTMLが同じならクロール頻度に影響しないと考えられます。
モバイル対応はユーザー体験やGoogle検索の評価には引き続き重要です。ただ、AI対策としてモバイル対応の優先度を最上位に引き上げるのは、実測データとは合いません。
→ 詳しくはモバイル対応はAI引用に関係するのか—サーバーログで実測したで実測データをまとめています。
8. noindexを設定すると、AIクローラーも来なくなる
「noindexはGoogleなどの検索エンジン向けの設定で、AIクローラーには関係ない」と思っているサイト運営者は多いです。ただ、実測では noindex の設定がAIクローラーの挙動にも影響することが確認できています。
WordPressのタグページにnoindexを設定したところ、設定後24時間以内に、それまで定期的にアクセスしていたGPTBotがタグページへの訪問をほぼゼロにしました。設定前後のログを比較すると、noindexを認識してクロール対象から外した可能性が高いことがわかります。
noindexはAIクローラーに読まれたくないページを除外する手段として有効です。重複コンテンツになりやすいタグページや検索結果ページにnoindexを設定しておくことで、クロール予算を節約して本文記事にAIクローラーを集中させられます。
逆に言えば、Search ConsoleやSEOプラグインで意図せずnoindexが設定されているページは、AIクローラーにも無視されている可能性があります。
→ 詳しくはタグをnoindexにしたら、GPTBotが来なくなったで実測データをまとめています。
9. 公開直後のサイトは、AIに誤って紹介される
新しいサイトや記事を公開したとき、「すぐにAIに正しく紹介してもらえる」と期待しているサイト運営者は多いです。ただ、実測では公開直後のサイトがAIに誤った内容で紹介されるケースが確認できています。
公開から2週間のサイトをChatGPT・Claude・Gemini・Perplexityの4つのAIで検証したところ、特にドメイン取得から1ヶ月未満のサイトで、複数のAIが存在しない情報を事実として回答したり、古いキャッシュをもとに誤った内容を返したりする場面がありました。
AIの学習データやキャッシュが更新されるまでのあいだ、サイトの内容と異なる情報が引用される状態が続きます。
公開直後は焦ってAI引用を確認しすぎる必要はありません。クローラーがサイトを十分にクロールし、AIの学習データやインデックスに反映されるまでには2週間〜1ヶ月程度かかるケースが多いです。
新しいサイトほど、XMLサイトマップの送信と内部リンク整備でクロールされる環境を整えることが先決です。
→ 詳しくは公開2週間のサイト、AIは誤って紹介するのか?—4大AIで検証で実測データをまとめています。
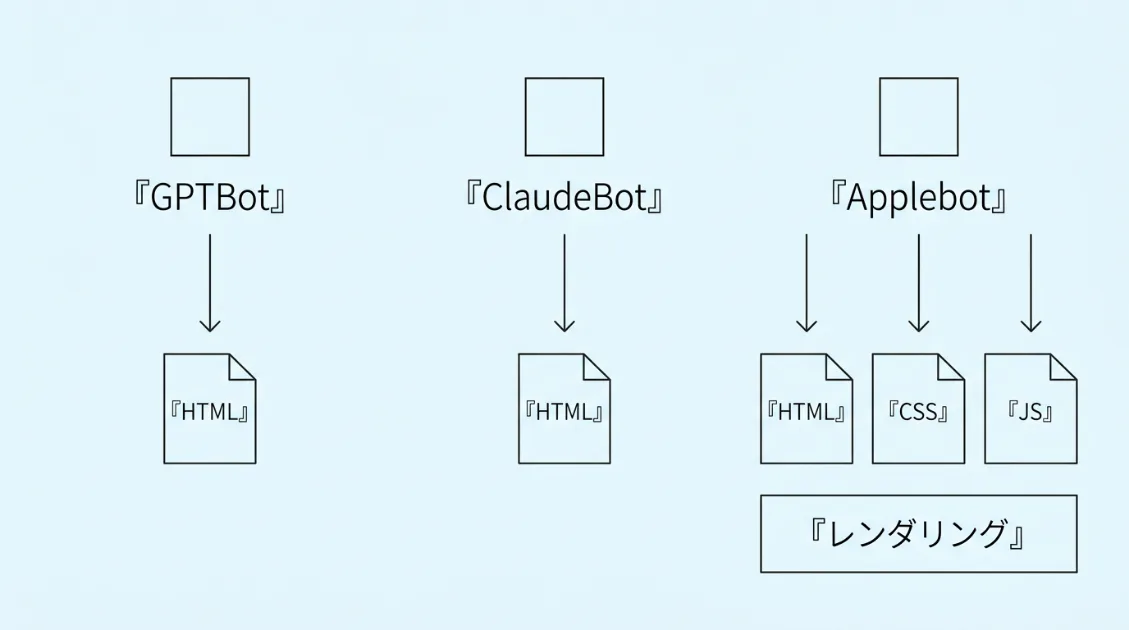
10. Applebotだけが、JavaScriptをレンダリングして読んでいる
AIクローラーはHTMLを取得するだけで、JavaScriptは実行しない——業界の共通認識でした。ただ、実測でApplebotだけは異なる挙動をしていることが確認できています。
サーバーログを分析したところ、ApplebotはHTMLを取得した後にCSSやJavaScriptファイルも個別にリクエストしていました。GPTBotやClaudeBotがHTMLの生データだけを持ち帰るのに対して、ApplebotはブラウザがWebページを表示するのと近い動きをしています。
Applebotはこれまで検索インデックス用のクローラーとして知られていました。
ただ、iOS 27でSiriがApple Intelligenceとして大きく進化することが発表されており、Applebotの重要性は今後急速に高まると考えられます。日本国内シェア50%超のiPhoneユーザーへのAI引用を狙うなら、今からApplebotに読まれる環境を整えておくことが先手になります。
FramerやWebflowのSPAで構築したサイトでも、Applebotにはレンダリングして読まれている可能性があります。
ただし、robots.txtに `User-agent: Applebot` のDisallowが書かれている場合はクロール自体が止まります。Applebot-Extendedの設定も含めて、一度確認しておくことをおすすめします。
→ 詳しくはAIクローラーはHTMLしか読まない—ただApplebotだけは違ったとiOS 27でSiriが変わる—Applebotの動き方と今後の展開で実測データをまとめています。
まとめ:AIに引用されるには、2つの壁を順番に越える
10の実験データを整理すると、引用されるサイトとされないサイトの境界線は明確になってきます。
まず「第一の壁」を自社サイトで確認してください。SPA構造になっていないか、重要な記事がトップページから2クリック以内に置かれているか、サイトマップだけに頼った設計になっていないか。コンテンツの質を上げる前に、AIクローラーが物理的にサイトを読める状態になっているかどうかが出発点です。
「第一の壁」を越えられている場合、次は「第二の壁」です。llms.txtやSNS運用・モバイル対応は、実測データではAI引用への直接的な影響が確認できませんでした。一方で、noindexの事故とApplebotの拒否は、引用の機会を確実に減らします。
Applebotは現時点では他のAIクローラーと異なる挙動をしており、iOS 27以降のSiri進化を考えると今から対応しておく価値があります。SPAで絶望した人も、Applebot経由なら引用の入口になり得ます。
実測データはすべて1サイトの観測結果であり、サイトの規模や構成によって結果は異なります。ただ、「なんとなく対策している」状態から「何が効いて何が効いていないかを把握している」状態に移行するための出発点として、参考にしてもらえれば幸いです。
今日から確認できるチェックリスト
- HTMLのbodyにテキストがベタ書きされているか確認する
- 重要な記事がトップページから2クリック以内にあるか確認する
- サイトマップに加えて内部リンクが充実しているか確認する
- robots.txtでApplebotとApplebot-ExtendedのDisallowがないか確認する
- 意図せずnoindexが設定されているページがないか確認する
- 公開から1ヶ月以内のサイトはクロール環境の整備を優先する
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。


