GPTBotより先に、ChatGPT-Userが来ていた—国別データとログで見えた意外な現実

「AIに学習されたくないからGPTBotをブロックした」——そう設定したことのあるサイト運営者は多いと思います。ただGPTBotをブロックしても、ChatGPTに引用されなくなるわけではありません。
OpenAIのクローラーは1種類ではなく、用途別に3種類あります。学習用・検索用・リアルタイムフェッチ用で、それぞれ動き方がまったく異なります。GPTBotをブロックしても、残りの2種類は動き続けます。
AI観測ラボのサーバーログ(2026年4月3日〜10日)を解析したところ、ChatGPT-Userが7日間で60件以上アクセスしてきました。同じ期間、GPTBotのアクセスはゼロでした。
GPTBotを警戒している間に、別のクローラーがサイトを読み込んでいたのです。
この記事でわかること|📖:約8分
- OpenAIのクローラーが3種類あり、それぞれ用途がまったく異なること
- GPTBotをブロックしてもChatGPTに引用される仕組みと、逆にブロックすると困るクローラーの違い
- AI観測ラボのサーバーログで確認した、ChatGPT-Userの7日間実測データ
- robots.txtをどう設定すべきかの現実的な考え方
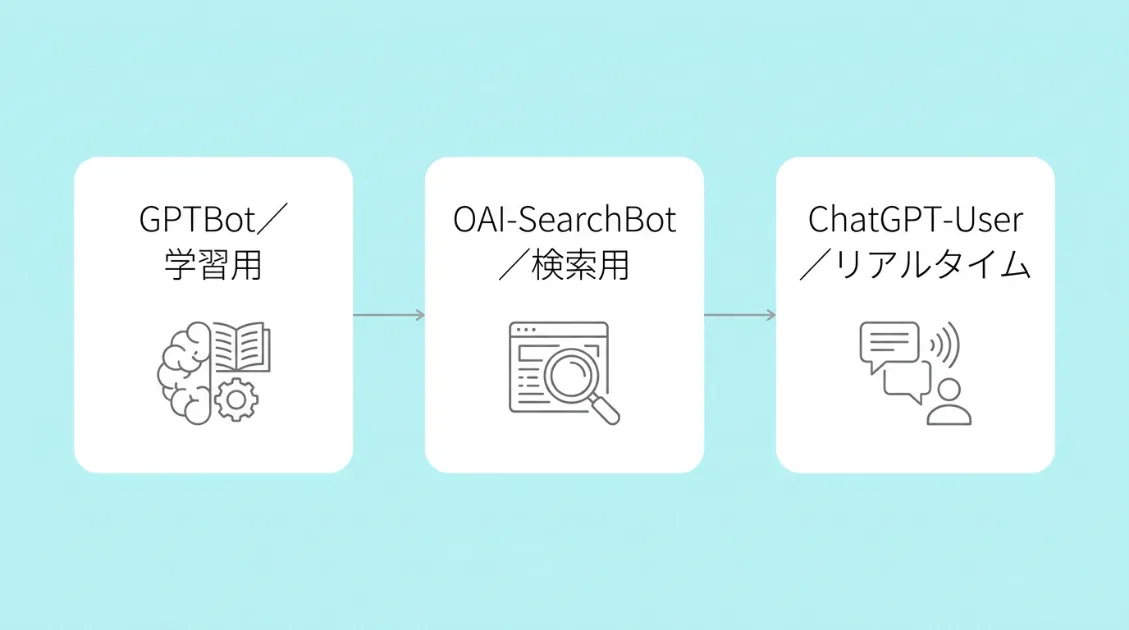
OpenAIのクローラーは3種類ある
「GPTBot=ChatGPTのクローラー」と思っている方が多いですが、OpenAIが運用するクローラーは用途別に3種類あります。
- GPTBot:AIモデルの学習データを収集するクローラー。自動でウェブを巡回して、将来のモデル改善に使うデータを集めます。
- OAI-SearchBot:ChatGPTの検索機能用クローラー。ユーザーが検索したとき、回答の根拠となるページをインデックスします。
- ChatGPT-User:ユーザーがChatGPTの会話中にURLを貼ったり、ChatGPTが検索を必要と判断したときだけ動くリアルタイムフェッチャー。自動巡回はしません。
3つのうち、AIの学習に使われるのはGPTBotだけです。OAI-SearchBotとChatGPT-Userは学習データの収集には使われません。
robots.txtでGPTBotをブロックしても、OAI-SearchBotとChatGPT-Userは動き続けます。逆に言うと、ChatGPT-UserをブロックするとChatGPTがリアルタイムでページを読みに来なくなるため、引用機会を失う可能性があります。
世界のAIクローラー勢力図
Cloudflare Radarが公開している2026年3月のデータによると、AIクローラーのシェアはGooglebotが31.6%でトップを維持しているものの、2025年と比べて大きく下落しています。2位にはMeta-ExternalAgentが16.7%で浮上し、GPTBotが12.0%で3位、ClaudeBotが11.7%で4位という結果になっています。
| クローラー | 運営元 | シェア(2026年3月) | 用途 |
|---|---|---|---|
| Googlebot | 31.6% | 検索インデックス・AI学習 | |
| Meta-ExternalAgent | Meta | 16.7% | 学習用 |
| GPTBot | OpenAI | 12.0% | 学習用 |
| ClaudeBot | Anthropic | 11.7% | 学習用 |
| ChatGPT-User | OpenAI | 集計外(急増中) | リアルタイムフェッチ |
出典:Monthly AI Crawler Report: March 2026 Traffic Trends(websearchapi.ai)
ただしこれは世界平均の数字です。国別に見ると、構成がまったく異なります。SEOmatorがCloudflare Radarの国別データを分析したところ、アメリカやヨーロッパではGooglebotが全AIトラフィックの約40〜50%を占め、学習クローラーが主体です。
ところが日本・ブラジル・オーストラリアでは、ChatGPT-Userがトップクローラーになっていることが判明しました。
出典:AI Bot Traffic by Country(SEOmator)
アメリカのサイトには学習クローラーが多く来て、日本のサイトにはリアルタイムフェッチャーが多く来ている——同じAIクローラーでも、国によって主役がまったく違うのです。
AI観測ラボのサーバーログで確認した実測データ
「日本ではChatGPT-Userが主体」という海外データが本当かどうか、AI観測ラボのサーバーログで確認しました。対象期間は2026年4月3日から4月10日の7日間です。
ChatGPT-Userは7日間で60件以上
ChatGPT-User(UA:Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot)によるアクセスは、7日間で60件以上確認できました。アクセス元はすべてMicrosoft AzureのIPレンジで、毎回異なるIPアドレスから来ています。
特徴的だったのは並列フェッチの動きです。4月8日18時27分には、以下の8ページを数秒以内に同時取得していました。
| 時刻 | 取得されたURL |
|---|---|
| 18:27:15 | /structured-data-guide/ |
| 18:27:15 | /about/ |
| 18:27:15 | /ai-crawler-crawl-depth/ |
| 18:27:15 | /llms-txt-guide/ |
| 18:27:15 | /semantic-html-ai-guide/ |
| 18:27:15 | /metatag-ai-crawler-guide/ |
| 18:27:15 | /articles/ |
| 18:27:15 | /(トップページ) |
GPTBotのようにタグページから順番に辿る動きとは異なり、ChatGPT-Userは複数のページを一気に並列で取得します。誰かがChatGPTの会話でAI観測ラボについて質問したとき、ChatGPTがサイト全体を把握しようとして複数ページを同時にフェッチしたと考えられます。
同じ7日間でGPTBotはゼロ件
一方、GPTBotのアクセスは同じ7日間でゼロ件でした。学習クローラーは来ていないのに、リアルタイムフェッチャーは毎日来ているという状況です。
| クローラー | 7日間のアクセス数 | 用途 |
|---|---|---|
| ChatGPT-User | 60件以上 | リアルタイムフェッチ |
| GPTBot | 0件 | 学習用 |
| ClaudeBot | 2件 | 学習用 |
海外データの「日本ではChatGPT-Userが主体」という傾向が、AI観測ラボの一次データでも確認できました。
ChatGPT-Userの挙動についての詳細な解説は、以下の記事にまとめています。
誰かがChatGPTにURLを貼った——サーバーログで見えた正体【AI実験室 #11】
GPTBotをブロックすると何が起きるか
「AIに学習されたくないからGPTBotをブロックしたい」という判断は理解できます。ただブロックする前に、3種類のクローラーがそれぞれ独立して動いていることを確認しておく必要があります。
GPTBotをブロックしても引用はされる
GPTBotは学習データの収集専用クローラーです。ブロックしても、ChatGPTの検索機能やリアルタイムフェッチには影響しません。OAI-SearchBotとChatGPT-Userは引き続き動きます。
つまりGPTBotをブロックしても、ChatGPTに引用される機会は残ります。「GPTBotをブロックした=ChatGPTから見えなくなった」は誤りです。
ChatGPT-Userをブロックすると引用機会を失う
逆に注意が必要なのはChatGPT-Userです。ユーザーがChatGPTで質問したとき、ChatGPTがリアルタイムでページを読みに来るのがChatGPT-Userです。robots.txtでChatGPT-Userをブロックすると、ChatGPTが会話中にページを参照できなくなります。
AI観測ラボのサーバーログでも、ChatGPT-Userが7日間で60件以上来ていました。毎日複数回、並列でページを取得している状況でChatGPT-Userをブロックすれば、引用の機会がそのままゼロになります。
なお、2026年3月時点のAI観測ラボのサーバーログ(AI実験室 #11)では、ChatGPT-Userは1週間で17件・単発フェッチが中心でした。4月の計測では7日間で60件以上・並列フェッチが目立つ形に変化しています。約2週間で件数が約3.5倍になり、挙動も変わっています。
OpenAIが仕様を変更したのか、ChatGPT自体の利用者増加によってリクエストが増えたのかは、サーバーログからは判断できません。ただ「ChatGPT-Userはたまに来る程度」という認識は、少なくともAI観測ラボのログでは当てはまらない状況になっています。
3種類のクローラーと、ブロックの影響
| クローラー | 用途 | ブロックした場合の影響 |
|---|---|---|
| GPTBot | 学習用 | 学習に使われなくなる。引用への影響は限定的 |
| OAI-SearchBot | 検索用 | ChatGPTの検索結果に出にくくなる可能性がある |
| ChatGPT-User | リアルタイムフェッチ | 会話中の引用機会がなくなる。影響が大きい |
robots.txtに「ChatGPT-User Disallow: /」と書いてしまうと、学習をブロックしたつもりが引用もブロックする結果になります。3種類を混同したまま設定するのが、最もよくある間違いです。
AIクローラーのブロック判断については、以下の記事も参考になります。
robots.txtの現実的な設定方針
3種類のクローラーの役割を理解した上で、robots.txtをどう書くかを整理します。目的別に3パターンを紹介します。
パターン① 学習だけ拒否・引用は許可する(おすすめ)
コンテンツをAIの学習データに使われたくないけれど、ChatGPTに引用はされたいという場合の設定です。GPTBotだけをブロックし、ChatGPT-UserとOAI-SearchBotは許可します。
User-agent: GPTBot
Disallow: /
User-agent: ChatGPT-User
Allow: /
User-agent: OAI-SearchBot
Allow: /AI観測ラボでもこの方針で運用しています。GPTBotのアクセスはゼロですが、ChatGPT-Userは毎日来ています。
パターン② 全部許可する
AIクローラーすべてに許可を出す設定です。学習データとして使われる可能性はありますが、引用機会を最大化できます。独自データや一次情報を持つサイトが学習に貢献することで、AIの回答精度が上がるという考え方もあります。
User-agent: GPTBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: OAI-SearchBot
Allow: /パターン③ 全部拒否する
有料コンテンツや独自調査データなど、AI学習に使われたくない情報を持つサイト向けの設定です。ただしChatGPT-UserもブロックするためChatGPTからの引用機会もなくなります。引用よりもコンテンツ保護を優先する場合に選ぶ設定です。
User-agent: GPTBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: OAI-SearchBot
Disallow: /どのパターンを選ぶかは、サイトの目的によって変わります。「学習には使われたくないが引用はされたい」という場合はパターン①、「とにかく守りたい」という場合はパターン③が現実的な選択です。
robots.txtの詳しい書き方については、以下の記事で解説しています。
AIクローラーの許可・拒否設定【robots.txt実例付き】
まとめ
「GPTBotをブロックすればAIへの対策は完了」という認識は、半分正解半分誤りです。OpenAIのクローラーは学習・検索・リアルタイムフェッチの3種類があり、それぞれ動き方も影響もまったく異なります。
AI観測ラボのサーバーログ(2026年4月3日〜10日)では、ChatGPT-Userが7日間で60件以上アクセスしていたのに対し、GPTBotのアクセスはゼロでした。Cloudflare Radarの国別データでも、日本はChatGPT-Userが主体のリアルタイムフェッチ型という傾向が出ています。
- GPTBotは学習専用クローラー。ブロックしても引用機会への影響は限定的
- ChatGPT-Userはリアルタイムフェッチ専用。ブロックすると引用機会がなくなる
- 日本のサイトにはGPTBotよりChatGPT-Userの方が多く来ている傾向がある
- 3種類を混同したままrobots.txtを書くと、意図と逆の結果になる場合がある
- 「学習は拒否・引用は許可」を実現するにはGPTBotだけをDisallowにするのが現実的
robots.txtの設定を見直す前に、まず自分のサイトにどのクローラーが来ているかをサーバーログで確認してみてください。GPTBotをブロックすべきか悩む前に、ChatGPT-Userがすでに来ているかどうかの方が、日本のサイト運営者には重要な問いかもしれません。
AI観測ラボでは引き続きサーバーログでAIクローラーの動きを実測していきます。新しいデータが取れたら続報としてお伝えします。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。


