YandexBotとは—Yandexのクローラーの役割と大量クロールの実測ログを解説

サーバーログを確認していると、毎朝ほぼ同じ時刻に必ず現れるクローラーがいました。
YandexBotです。ロシアの検索エンジン :contentReference[oaicite:0]{index=0} が運営するクローラーで、robots.txtを確認したあと、記事を1本だけ読んで去っていく——そんな規則的な巡回を毎日のように繰り返していました。日本語サイトであっても、YandexBotは確実に訪問しています。
ところが、ある日だけ挙動が一変します。毎日2〜3件だった巡回が、突然72件まで増加。サイトマップをまとめて取得し、タグページを並列で大量クロールするなど、いつもの定点巡回とは明らかに異なる動きが記録されました。
この記事では、AI観測ラボのサーバーログ実測データをもとに、YandexBotの役割、通常の巡回パターン、大規模クロールが起きた背景まで順番に整理します。
この記事でわかること|📖:約6分
- YandexBotの役割と、YandexのAIアシスタント「Alice」との関係
- 毎朝robots.txtを確認してから記事を1本読む、定点巡回の実測パターン
- 通常2〜3件だった巡回が72件まで急増した大規模クロールの記録と考察
- robots.txtでの設定方法と、日本語サイトにも訪問する理由
YandexBotとは何か
YandexBotは、ロシア最大の検索エンジン「Yandex」が運営するWebクローラーです。Googleに対するGooglebotと同じ関係で、YandexBotはYandexの検索結果にページを表示するためにWebサイトを巡回し、コンテンツを収集します。
Yandexはロシア語圏を中心に広く利用されている検索エンジンで、日本語サイトを含む世界中のWebサイトを継続的にクロールしています。国内向けのサイトを運営していても、YandexBotがサーバーログに現れることは珍しくありません。
AI観測ラボのサーバーログでも、YandexBotの定期的な訪問を継続して確認しています。毎朝ほぼ同じ時刻にrobots.txtを取得し、その後に記事ページを1本だけ巡回して去る——そんな規則的な行動パターンが記録されていました。
User-Agentの文字列は以下のとおりです。
Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots)サーバーログでYandexBotを識別する場合は、User-Agent内の「YandexBot」という文字列で判定する方法が確実です。IPアドレスだけで判定しようとすると、使用レンジが複数あるため取りこぼしが発生する可能性があります。
なお、YandexにはYandexBot以外にも複数のクローラーが存在します。画像専用の「YandexImages」、動画専用の「YandexVideo」などがありますが、この記事ではWebページを巡回するメインクローラーのYandexBotに絞って解説します。
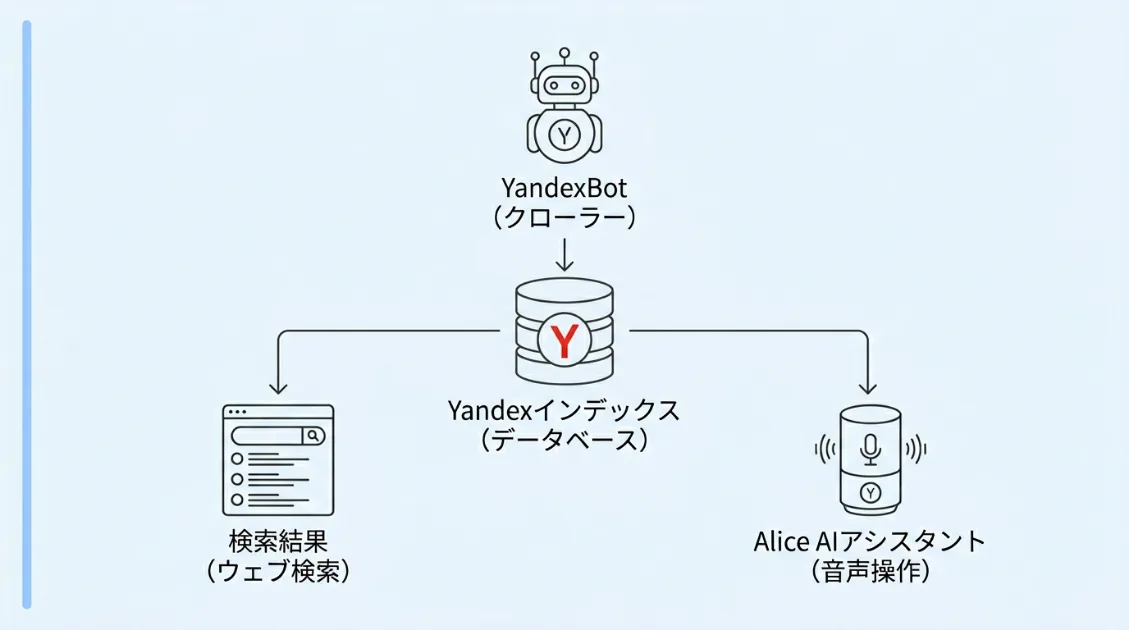
YandexはAliceというAIアシスタントを持っている
YandexBotを理解するうえで、Yandex がどのような会社かを知っておくことも重要です。Yandexは検索エンジンだけでなく、「Alice(アリサ)」というAIアシスタントを開発・運営しています
AliceはGoogle AssistantやSiriに近いサービスで、スマートフォンやスマートスピーカーを通じてロシア語圏で広く利用されています。ユーザーが音声やテキストで質問すると、Yandexの検索インデックスを含む情報基盤を活用して回答を返します。
つまりYandexBotがWebサイトを巡回して収集したコンテンツは、検索結果の表示だけでなく、Aliceの回答品質を支える情報の一部になる可能性があります。検索用クローラーが集めた情報が、AI体験の土台になるという構造は、多くの大手検索企業に共通しています。
近年はAliceの機能強化も進んでおり、画像・動画・リンクを含む新しい回答形式にも対応しています。Yandex全体でAI機能の拡張が続くなかで、YandexBotのクロール活動もその基盤のひとつとして位置づけられます。
日本語サイトの運営者にとってYandex検索への表示優先度は高くないかもしれません。ただ、AIアシスタントの情報源としてコンテンツが収集される可能性がある、という視点は持っておく価値があります。
実測①:毎朝robots.txtを確認してから記事を1本読む
AI観測ラボのサーバーログを継続して観測した結果、YandexBotは毎朝ほぼ同じ時刻に、決まった手順でサイトを巡回していることがわかりました。
巡回の手順は2ステップです。まずrobots.txtを取得してクロールの許可範囲を確認し、続けて記事ページを1本取得して去っていきます。毎回訪問する記事は異なりますが、この2ステップの構造は毎日変わりません。
| 日付 | 時刻 | 取得URL |
|---|---|---|
| 4月30日 | 05:12 | /robots.txt → /ai-visibility/ |
| 5月1日 | 05:40 | /robots.txt → /wordpress-security-checklist/ |
| 5月2日 | 05:38 | /robots.txt → /ga4-beginner-check/ |
| 5月3日 | 05:15 | /robots.txt → /wordpress-permalink/ |
| 5月4日 | 05:10 | /robots.txt → /wordpress-category-tag-guide/ |
| 5月6日 | 05:55 | /robots.txt → /search-console-ai-crawler/ |
| 5月7日 | 04:02 | /robots.txt → /traffic-advice/ |
訪問時刻は毎日04〜06時台に集中しています。日本時間の早朝に当たるこの時間帯は、Yandexのサーバーがあるロシア・モスクワ時間(UTC+3)の深夜から明け方に相当します。
時差を考えると、Yandex側の運用時間帯が巡回時刻に影響している可能性があります。
また、毎回異なる記事を1本ずつ取得していることから、サイト全体を少しずつ読み進める「分散型巡回」の戦略をとっていると考えられます。GPTBotがサイトマップを起点に記事本文へ到達するパターンとは異なり、YandexBotは記事URLを直接指定して取得する動きが特徴的です。
GPTBotの巡回パターンとの比較についてはGPTBotとはで詳しく解説しています。
実測②:通常2〜3件の巡回が72件まで急増した日
毎日2〜3件の定点巡回が続く中、観測期間中に1日だけ挙動が一変しました。通常の約30倍にあたる72件のアクセスが、約2時間の間に集中して記録されました。
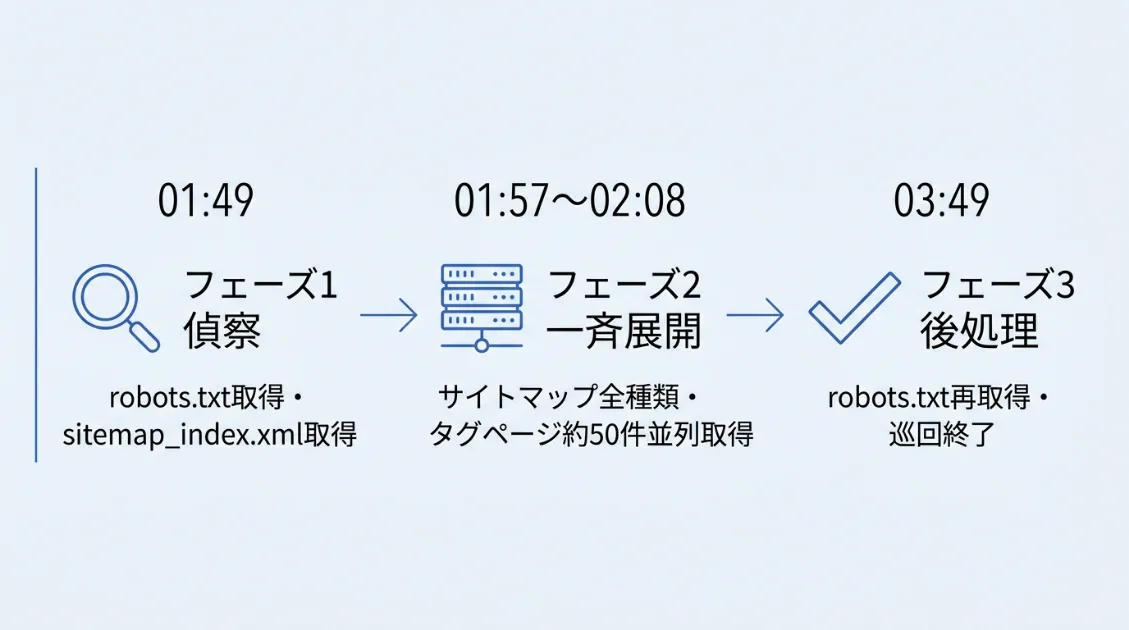
この大規模クロールは、ログを追うと3つのフェーズに分かれていました。
フェーズ1:初動確認(01:49〜約1分以内)
最初に「5.255.231.74」が/robots.txtを取得し、クロールの許可範囲を確認しました。続けて別のIPが記事を1本取得し、さらに/sitemap_index.xmlを取得しています。この動きが、その後の大規模クロールの起点になりました。
フェーズ2:一斉展開(01:57〜02:08・約10分間)
サイトマップを全種類取得したあと、4つのIPレンジが並列でタグページを大量に取得しました。
| 取得URL | 内容 |
|---|---|
| /sitemap_index.xml | サイトマップの親ファイル |
| /post-sitemap.xml | 記事一覧 |
| /category-sitemap.xml | カテゴリー一覧 |
| /post_tag-sitemap.xml | タグ一覧 |
| /page-sitemap.xml | 固定ページ一覧 |
| /author-sitemap.xml | 著者一覧 |
タグページだけでも約50件のアクセスが記録されました。使用されたIPレンジは以下の4種類です。
- 213.180.203.x
- 95.108.213.x
- 87.250.224.x
- 5.255.231.x
4つのIPレンジが同時並列で動いていることから、YandexBotは分散した複数のサーバーから協調的にクロールしている可能性があります。
フェーズ3:後処理(03:30〜03:49・約2時間後)
フェーズ2から約2時間後、/robots.txtを再取得して巡回を終えました。巡回終了前の再確認としてrobots.txtを取得した可能性があります。
なぜ大規模クロールが起きたのか——3つの仮説
大規模クロールが発生した理由は、YandexBot側のアルゴリズムなのでログだけでは断定できません。しかしながら、実測データから可能性の高い仮説を3つ挙げられます。
仮説①:サイトマップを起点にした全体取得への切り替え
大規模クロールが発生した前日の深夜、通常の定点巡回とは別に/sitemap_index.xmlを取得するアクセスが記録されていました。
サイトマップの親ファイルを確認したYandexBotが、サブサイトマップの存在を把握し、翌日に全種類を取得しにきた可能性があります。3つの仮説の中では、実測ログとの整合性が最も高い仮説です。
仮説②:記事本数や更新頻度の変化を検知した
毎日の定点巡回の中で「このサイトは継続的に更新されている」と判断し、ある時点でサイト全体の再確認が必要と判定した可能性もあります。他のクローラーでも、サイト構造や更新頻度の変化をきっかけに巡回パターンが変わる例が見られます。
巡回パターンの変化事例については、ClaudeBotはどう動いてサイトを読むのかでも詳しく解説しています。
仮説③:Yandexの定期的なフルクロールサイクル
検索エンジンは、一定の周期でサイト全体を再評価するための大規模クロールを行うことがあります。毎日の定点巡回とは別に、定期的な全体取得サイクルがたまたまこの日に重なった可能性も考えられます。
フルスクロールサイクルに関しては今後も周期的に発生するかどうかが大きな観測ポイントになります。
現時点では仮説①が最も有力ですが、複数の要因が重なって発生した可能性もあります。AI観測ラボでは、今後もYandexBotの巡回ログを継続して観測していきます。
robots.txtでYandexBotを制御できるか
YandexBotはrobots.txtの記述を尊重します。実測ログでも、毎回の巡回でrobots.txtを最初に取得してからページへアクセスする動きが確認できています。robots.txtに適切な記述をすることで、クロールを許可・拒否・制限することができます。
すべてのクロールを拒否する場合
“`html
User-agent: YandexBot
Disallow: /
“`
特定のディレクトリだけ拒否する場合
“`html
User-agent: YandexBot
Disallow: /wp-admin/
Disallow: /tag/
“`
すべてのYandex系クローラーをまとめて拒否する場合
“`html
User-agent: Yandex
Disallow: /
“`
「YandexBot」と指定するとメインのWebクローラーだけに適用されます。「Yandex」と指定するとYandexImages・YandexVideoなど、Yandex系のクローラー全体に適用されます。目的に応じて使い分けてください。
日本向けサイトでYandex経由の流入がほぼない場合、大きな影響は出にくいと考えられます。
日本語サイトがYandexの検索結果に表示されなくなりますが、日本国内のユーザーへの影響はほぼゼロです。Yandexの検索流入を必要としないサイトであれば、拒否設定にしておくことも選択肢の1つとして考えていくべきです。
robots.txtの書き方全般についてはrobots.txtでAIクローラーにどう見せるかで詳しく解説しています。
日本語サイトにYandexBotが来る意味はあるか
日本語サイトを運営している場合、YandexBotの訪問を見て「ロシアの検索エンジンに意味はあるのか」と感じる方は多いと思います。
結論から言うと、Yandexの検索流入という観点では日本語サイトへの恩恵はほぼありません。Yandexはロシア語圏に特化した検索エンジンで、日本語コンテンツの検索ユーザーは少ないからです。
ただし、以下の2点は考慮する価値があります。
AliceのAIデータソースになる可能性
YandexBotが収集したコンテンツは、AIアシスタントAliceの回答生成に使われる可能性があります。ロシア語圏のユーザーが日本のサービスや製品について質問した場合、日本語サイトのコンテンツが参照されるケースがゼロではありません。グローバルなブランド認知を意識するサイトであれば、YandexBotのクロールを許可しておくことに意味があります。
クローラー挙動の観測対象として価値がある
AI観測ラボとしての視点では、YandexBotは非常に興味深い観測対象です。
毎日robots.txtを確認してから記事を1本取得する定点巡回、そして条件が揃ったときに一斉展開する大規模クロールという2段階の挙動は、他のクローラーにはない特徴的なパターンです。クローラーの動きを理解することは、サイト設計やrobots.txt設定の最適化につながります。
日本語サイトへのYandexBotの訪問は、積極的に活用する必要はありませんが、拒否する積極的な理由もありません。サーバー負荷が問題にならない限り、デフォルトで許可のまま観測を続けるのが現実的な対応です。
まとめ
YandexBotは、ロシア最大の検索エンジンYandexが運営するWebクローラーです。AIアシスタントAliceのデータソースとしても機能しており、収集したコンテンツは検索結果とAI回答の両方に活用されます。
AI観測ラボのサーバーログで確認できたYandexBotの特徴を整理します。
- 毎朝04〜06時台に「robots.txt → 記事1本」の2ステップ定点巡回を繰り返す
- 毎回異なる記事を1本ずつ取得する分散型巡回で、サイト全体を少しずつ読み進める
- 条件が揃うと通常の約30倍にあたる大規模クロールに切り替わる
- 大規模クロール時は4つのIPレンジが並列で動き、サイトマップ全種類とタグページを一気に取得する
- robots.txtの記述を尊重するため、User-agent: YandexBotで制御できる
日本語サイトへの検索流入という観点では、YandexBotの恩恵はほぼありません。ただし定点巡回と大規模クロールを使い分ける独特の挙動は、クローラー設計を理解するうえで参考になるパターンです。
サーバーログでYandexBotの動きを確認したい場合は、User-Agent内の「YandexBot」という文字列でフィルタリングしてください。IPアドレスは4つのレンジが使われるため、User-Agentによる識別が確実です。
AIクローラー全体の挙動パターンを比較したい場合はAIクローラーは全員違う動きをしていたも参考にしてください。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。


