Perplexityに引用されるサイトの条件—実測ログから見えた5つの設計

「Perplexityの回答に自分のサイトへのリンクが表示されている」と気づいたとき、多くの人は偶然だと感じるかもしれません。ですが、Perplexityに引用されやすいサイトには、いくつか共通した設計があります。
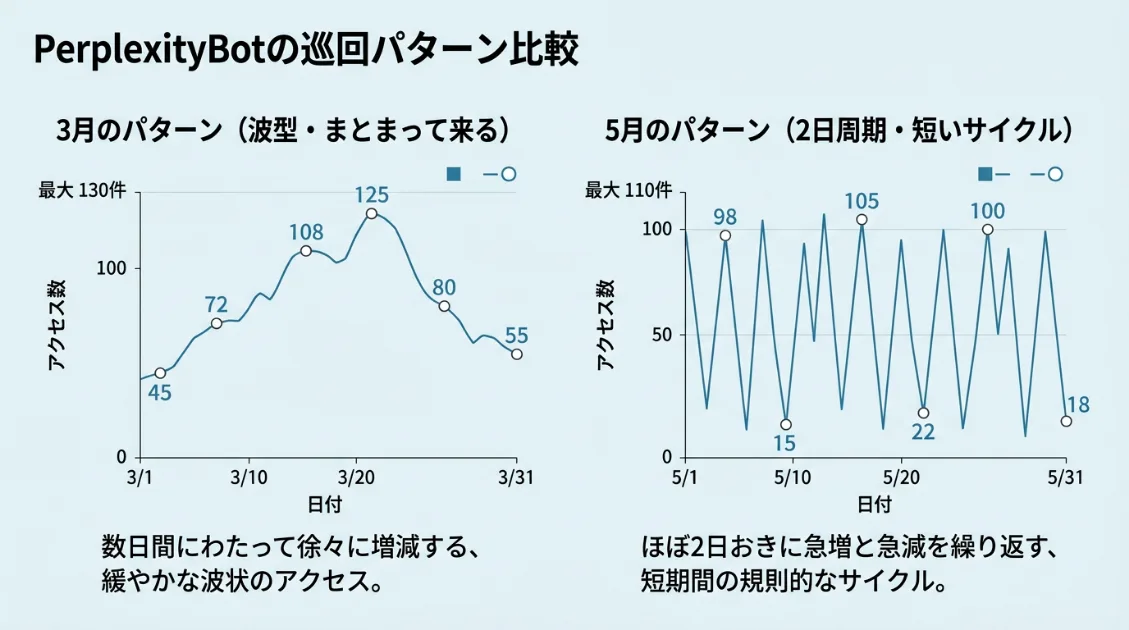
PerplexityBotはAI観測ラボのサーバーログにも継続的に現れます。3月には10分間で130件・8IPの並列クロール、5月には2日周期・最大110件という巡回を実測しました。ログを読み解くと、PerplexityBotが「どんなページを、どのように読んでいるか」が少しずつ見えてきます。
この記事では、実測データをもとに、Perplexityに引用されやすくなる設計を5つに整理します。
この記事でわかること|📖:約8分
- Perplexityが何をもとに引用元を選ぶのか
- PerplexityBotを「来させる」ための入口設計
- 実測ログで見えた「読まれるページ」の共通点
- 引用されやすいHTML構造とllms.txtの関係
Perplexityは何を引用元として使うのか
Perplexityは質問を受け取ると、回答文とあわせて引用元リンクを表示します。その引用元候補を集める経路は、大きく分けて2つあります。
| 経路 | クローラー | タイミング |
|---|---|---|
| 事前インデックス | PerplexityBot | 定期巡回でサイト全体を広く収集 |
| リアルタイム取得 | Perplexity-User | 質問に応じてその場でページを取得 |
大きな流れで見ると、まずPerplexityBotがサイトを巡回して情報を蓄積します。そのうえで、ユーザーの質問に合うページが引用元として選ばれます。
つまり引用されるための入口のひとつが、PerplexityBotに来てもらうことです。継続的な巡回が確認できているサイトほど、引用候補として扱われやすくなる可能性があります。
一方で、Perplexity-Userが質問に応じてリアルタイムにページを取得し、その内容を回答生成に使うケースもあります。Perplexityの引用は「事前巡回」と「リアルタイム取得」の2つの経路で成り立っています。
次のセクションでは、まずPerplexityBotを「来させる」ための入口設計から順番に整理します。
設計①|PerplexityBotを来させる入口をつくる
PerplexityBotは公式ドキュメントに記載されたUser-Agentでサイトを巡回します。巡回の前に必ずrobots.txtを取得する動きが、AI観測ラボの実測ログでも毎回確認できています。
継続的に引用候補として扱われるための最初のステップは、PerplexityBotがサイトに入れる状態をつくることです。
robots.txtでブロックしていないか確認する
robots.txtに以下の記述があると、PerplexityBotはサイトへの巡回を止めます。
User-agent: PerplexityBot
Disallow: /意図せずブロックしているケースも実際にあります。User-agent: *で全クローラーを一括拒否している設定も同様です。まず現状のrobots.txtを確認してください。
許可する場合は何も書かなければデフォルトで許可になります。明示的に許可したい場合は、以下のように記述します。
User-agent: PerplexityBot
Allow: /PerplexityBotは広く均等にサイト全体を巡回する傾向があるため、トップページだけではなく、記事一覧やカテゴリページにも自然にたどり着ける構造が望ましい設計です。
sitemapをrobots.txtに明記する
AI観測ラボの実測ログでは、PerplexityBotが巡回のたびにsitemap_index.xmlを取得する動きが確認できています。sitemapがrobots.txtに記載されていると、巡回の入口として認識されやすくなります。
Sitemap: https://example.com/sitemap_index.xmlWordPressにてYoast SEOを使っている場合、sitemapは自動生成されます。robots.txtへの記載も自動で行われることが多いですが、念のため確認しておくと安心です。
robots.txtの設定方法を詳しく知りたい場合はrobots.txt完全ガイド|AIクローラー制御もあわせてご覧ください。
設計②|読まれるページの構造をつくる
PerplexityBotはサイト全体を広く巡回しますが、引用元として扱われやすいページには、いくつか共通した構造が見られます。AI観測ラボの実測ログと、Perplexityの引用パターンを照らし合わせると、読まれやすいページの条件が少しずつ見えてきます。
冒頭に定義文を置く
Perplexityはユーザーの質問に対して「直接答えられる文章」を引用元として扱いやすい傾向があります。記事の冒頭に「〇〇とは、△△です」という形式の定義文があると、質問への回答として切り取りやすくなります。
PerplexityBotは記事全体を巡回しますが、ページ冒頭の定義文は、そのページが何を扱っているかを理解する手がかりになりやすいと考えられます。冒頭でテーマを明示することが、引用候補として認識される入口になります。
見出しを質問形式にする
Perplexityはユーザーの質問に対して回答を生成します。H2・H3の見出しが「〇〇とは何か」「〇〇の方法は」のような質問形式になっていると、記事のどのセクションがどの疑問に答えているのかを整理しやすくなります。
「〇〇について」「〇〇の解説」といった曖昧な見出しよりも、答えの方向性が見える見出しの方が、引用元として扱いやすい構造になります。
数値・事実を段落ごとに入れる
AI観測ラボの実測では、PerplexityBotが記事ページだけではなく、固定ページ・タグページ・カテゴリページもまんべんなく取得していました。一方で引用元として表示されるページには、具体的な数値や事実が含まれているケースが多く見られます。
たとえば「約10分間で130件・8IPの並列クロール」のような具体的な数値は、回答の根拠として扱いやすい情報です。抽象的な説明だけのページよりも、数値や事実が含まれるページの方が引用候補として扱われやすくなります。
比較表や一覧表を置く
Perplexityの回答では、比較・整理された情報が引用元として扱われるケースが多く見られます。項目を表形式でまとめておくと、特徴の違いや要点を抽出しやすくなります。
仕様比較、種類の違い、時系列の変化などは、文章だけで説明するよりも表に整理した方が、引用候補として扱いやすい構造になります。
設計③|AIが読みやすいHTML構造にする
PerplexityBotは、まずサーバーから返ってくるHTMLをもとにページ内容を理解すると考えられます。HTML構造が整っているほど、ページの意味や情報のまとまりを把握しやすくなります。
セマンティックなHTML要素を使う

divタグで囲っただけのテキストより、適切なHTML要素を使った文章の方が、AIクローラーに内容が伝わりやすくなります。
| 要素 | 使いどころ |
|---|---|
<article> |
記事本文全体を囲む |
<h2><h3> |
セクションの見出し(階層を守る) |
<p> |
段落ごとのテキスト |
<ul><ol> |
箇条書き・手順 |
<table> |
比較・一覧データ |
<blockquote> |
引用・公式ドキュメントの抜粋 |
セマンティックHTMLとAIクローラーの関係についてはAIはdivが苦手?セマンティックHTMLがAI引用の土台になる理由で詳しく解説しています。
比較表とリストを積極的に使う
Perplexityが回答を生成するとき、構造化された情報は根拠として扱いやすい形式になります。散文で書かれた説明より、箇条書きや表形式で整理された情報の方が要点を抽出しやすいためです。
手順・条件・比較を説明するセクションは、文章だけで書くより箇条書きや表にまとめる方が、引用候補として扱われやすい構造になります。
画像のalt属性とキャプションも整える
図解やスクリーンショットを使う場合は、alt属性とfigcaptionをセットで入れておくと、画像が何を示しているかを理解しやすくなります。
「image1.webp」のような機械的なaltではなく、「PerplexityBotが8IPで同時並列クロールしている図解」のように内容を説明する文にすると、ページ理解の補助になります。
JSON-LDで構造化データを設定する
FAQ形式のコンテンツはJSON-LDで構造化データを設定すると、質問と回答のセットを機械的に理解しやすくなります。人間向けの見た目とは別に、ページ構造を明確に伝えられる点がメリットです。
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [
{
"@type": "Question",
"name": "PerplexityBotとは何ですか?",
"acceptedAnswer": {
"@type": "Answer",
"text": "PerplexityBotはAI検索サービスPerplexityが運営するWebクローラーです。ユーザーの質問に対する回答生成の参照情報を収集するために動いています。"
}
}
]
}JSON-LDの設定方法についてはJSON-LDはAIクローラーに効くのか—構造化データの種類と実装方法もあわせてご覧ください。
設計④|Perplexity-Userへの対応を分けて考える
Perplexityからのアクセスは、PerplexityBotだけではありません。ユーザーが質問を入力したタイミングで動く「Perplexity-User」という別の取得経路があります。
引用の仕組みを正しく理解するには、2つの経路を分けて考えることが大切です。
| 種類 | 動くタイミング | robots.txt | ログへの出方 |
|---|---|---|---|
| PerplexityBot | 定期的な自動巡回 | 遵守する | まとまって複数ページ |
| Perplexity-User | ユーザーの質問に応じて動く | ユーザーリクエストを優先 | 単発・特定ページ中心 |
Perplexity-Userは、ユーザーの質問に対して回答に必要なページをリアルタイムで取得します。AI観測ラボのログでは現時点でPerplexity-Userの訪問は確認できていませんが、特定ページの取得が必要になった場面で動く設計です。
robots.txtだけでは制御しきれない
Perplexity-Userは、ユーザーのリクエストを優先して取得する性質があります。限定公開のコンテンツを守りたい場合は、robots.txtだけに頼らず、パスワード保護やアクセス制限と組み合わせる方が確実です。
引用には2つの入口がある
PerplexityBotが事前に巡回して蓄積したページが引用候補になる経路と、ユーザーの質問に応じてPerplexity-Userがリアルタイムで取得したページが引用元になる経路、その2つが存在します。
つまり、PerplexityBot向けには「巡回しやすい設計」、Perplexity-User向けには「質問の答えとして使いやすい内容」が重要になります。入口は2つありますが、どちらも「わかりやすく整理された情報」が共通の土台になります。
設計⑤|llms.txtとrobots.txtを整備する
AI観測ラボの実測ログでは、PerplexityBotがllms.txtを直接取得した記録は確認できていません。PerplexityBotはrobots.txtを確認してから数秒以内に記事本文へ直行するパターンが実測で見えています。
ただしllms.txtは、PerplexityBot以外のAIクローラーも含めて「このサイトが何を扱っているか」を伝えるファイルとして機能する可能性があります。robots.txtとあわせて整備しておく価値はあります。
robots.txtとllms.txtの役割の違い
| ファイル | 役割 | PerplexityBotの実測 |
|---|---|---|
| robots.txt | クロールの許可・拒否を指示する | 毎回必ず取得を確認 |
| llms.txt | サイトの内容・構造をAIに伝える | 取得の実測なし |
実測の観点では、PerplexityBotへの引用設計として優先度が高いのは、robots.txtとsitemapの整備です。llms.txtは、他のAIクローラーへの情報整理として位置づける方が実態に合っています。
llms.txtの書き方と設置手順についてはllms.txtの書き方【テンプレコピペOK】もあわせてご覧ください。
まとめ——引用される設計は5つの積み重ね
Perplexityに引用されやすいサイトには、いくつか共通した設計が見られます。AI観測ラボの実測ログから逆算した5つの設計を整理します。
| 設計 | 内容 | 優先度 |
|---|---|---|
| ①入口をつくる | robots.txtでブロックしない・sitemapを明記する | 最優先 |
| ②読まれるページをつくる | 冒頭に定義文・見出しを質問形式・数値を入れる | 高 |
| ③HTML構造を整える | セマンティックHTML・比較表・JSON-LD | 高 |
| ④Perplexity-Userを理解する | robots.txtだけでは制御しきれない別経路として把握する | 中 |
| ⑤llms.txtの位置づけを理解する | llms.txtは補助的に整備し、まずrobots.txtとsitemapを優先する | 中 |
実測ログで確認できた最重要の事実は、PerplexityBotが毎回robots.txtを取得してからクロールを開始している点です。引用される前提として、まずPerplexityBotがサイトに入れる状態をつくることが出発点になります。
PerplexityBotがどんな仕組みで動いているかを知りたい場合はPerplexityBotとは—役割・巡回パターン・robots.txt設定をあわせてご覧ください。
AIクローラー全体の引用の仕組みを横断的に比較したい場合はAIクローラーは全員違う動きをしていたも参考になります。
Perplexityへの引用は、特別な裏技ではなく「入りやすく、読みやすく、意味が伝わりやすい」サイト設計の積み重ねです。AIクローラーの動きを観測しながら整えていくことが、これからのWeb運営の新しい基本になっていきそうです。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。


