ClaudeBotのサーバーログ539件を解析—見えてきた4つの行動パターンと3つの対策

この記事は、ClaudeBotの基本解説ではありません。
AI観測ラボのサーバーログに残ったClaudeBotのアクセスを解析し、どの順番でサイトを確認し、どのURLで止まり、どのタイミングで記事本文へ進んだのかを記録した実測レポートです。
解析したログは539件。観測期間は2026年3月から6月にかけてで、その中には通常の10倍を超える358件のスパイクが1日で発生した日も含まれています。
ClaudeBotが「来ている」だけではなく、サイト内でどう動いているのかを知りたい運営者向けに、ログから見えた5つの行動パターンと、すぐ確認できる3つの対策を整理します。
この記事でわかること|📖 約7分
- 539件のサーバーログ解析で見えたClaudeBotの5つの行動パターン
- 6月13日に通常日の10倍超・358件のアクセスが集中した記録
- 大規模再クロール後にrobots.txt・sitemap確認へ戻った実測データ
- ClaudeBotに正しく巡回してもらうために確認したい3つの対策
この記事で扱うClaudeBotについて
当記事にて扱うClaudeBotは、Anthropicが運用する学習用クローラーのことです。Claude-UserやClaude-SearchBotとの違い、robots.txtでの制御方法、公式仕様の概要については、別記事のClaudeBotとはで整理しています。
この記事では、ClaudeBotの基本解説ではなく、AI観測ラボのサーバーログに残った実際の巡回行動に絞って見ていきます。
「ClaudeBotが何者か」ではなく、「ClaudeBotがサイト内でどう動いたのか」を確認するための実測レポートです。
6月13日に通常の10倍超のアクセススパイクが発生した
今回のログで最も大きな変化は、6月13日に発生したアクセススパイクです。
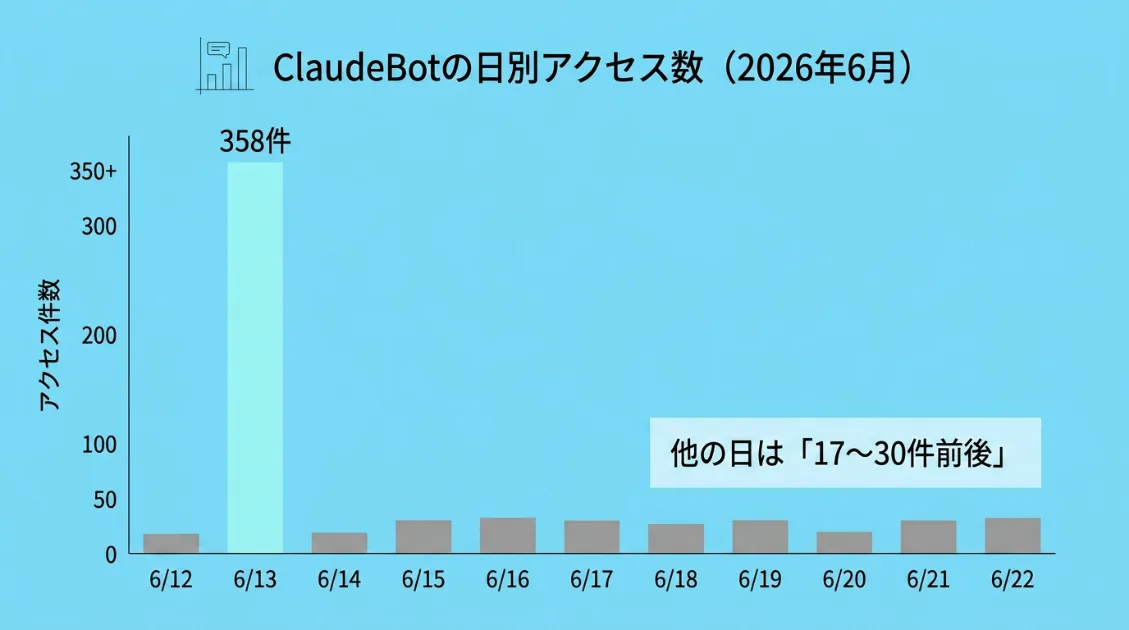
通常日は17〜30件前後で推移していたのに対し、6月13日だけで358件のアクセスが記録されました。単なるrobots.txtやsitemap_index.xmlの確認ではなく、サイト全体を広く見直すような動きです。
時系列で見ると、深夜0時台に始まったクロールが1〜3時台に集中し、約4時間で複数のURL種別を巡回していました。URL種別では、タグページが44%、記事ページが37%、カテゴリページが6%を占めており、普段の「robots.txt+sitemap確認」とは異なる構成になっています。
注目したいのは、スパイク後の変化です。6月14日以降、ClaudeBotの行動はrobots.txtとsitemap_index.xmlの確認に戻り、記事ページへのアクセスは大きく減少しました。
この動きからは、「6月13日にサイト全体を再クロールし、6月14日以降は定期監視に戻った」という読み方ができます。ただし、ClaudeBot側の仕様変更など外部要因があったかどうかは、今回のログだけでは特定できません。
少なくとも今回のデータでは、AIクローラーが常に同じ頻度で巡回しているわけではなく、大規模な再クロールと、robots.txt・sitemap中心の定期確認を切り替えている可能性が見えてきました。
行動パターン①:robots.txtとsitemap_index.xmlをセットで確認する
539件のログを見て最初に気づいたのは、ClaudeBotがrobots.txtとsitemap_index.xmlをセットで取得する傾向です。今回の観測範囲では、同じ動作を1日に複数回繰り返している日もありました。
今回の解析では、robots.txtが100件、sitemap_index.xmlが92件でした。この2つだけで192件となり、全アクセス539件の約35%を占めています。実際のログはこうなっています。
216.73.216.164 [17/Apr/2026:14:04:08] GET /robots.txt → 200
216.73.216.164 [17/Apr/2026:14:04:08] GET /sitemap_index.xml → 200
216.73.216.164 [17/Apr/2026:18:27:08] GET /robots.txt → 200
216.73.216.164 [17/Apr/2026:18:27:09] GET /sitemap_index.xml → 200
216.73.216.164 [17/Apr/2026:22:08:34] GET /robots.txt → 200
216.73.216.164 [17/Apr/2026:22:08:35] GET /sitemap_index.xml → 200robots.txtとsitemap_index.xmlへのアクセスは、ほぼ同じ秒に記録されています。ClaudeBotは「まずルールを確認してから、サイトの地図を見る」という手順を踏んでいるように見えます。
サイト運営者にとって重要なのは、ClaudeBotがrobots.txtとsitemapを一度だけ確認して終わるのではなく、繰り返し確認しているという点です。robots.txtでClaudeBotの動きを制御したい場合、設定後もログを見れば、ClaudeBotが再確認しに来ているかを追跡できます。
逆に言えば、ClaudeBotに来てほしいサイトは、robots.txtでClaudeBotをブロックしていないか確認しておく必要があります。設定の書き方はrobots.txtでAIクローラーを制御する記事にまとめています。
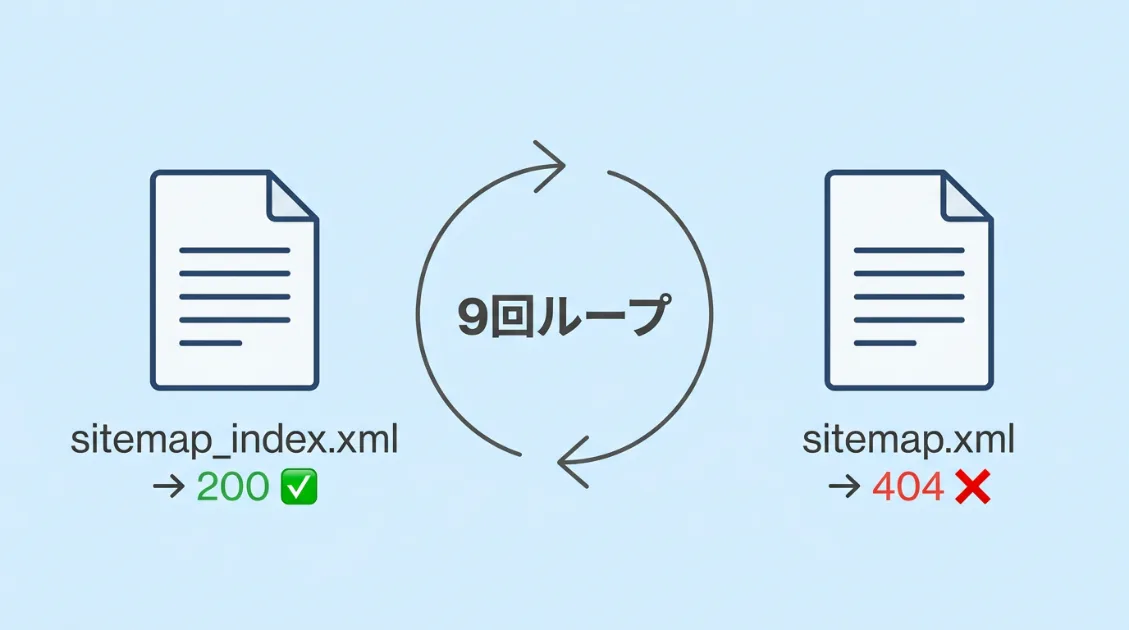
行動パターン②:存在しないsitemap.xmlを確認しに来る
今回のログで気になった動きのひとつが、存在しない/sitemap.xmlへのアクセスです。ClaudeBotは/sitemap_index.xmlを正常に取得しているにもかかわらず、別途/sitemap.xmlも確認しに来ていました。
539件の全アクセスのうち、/sitemap.xmlへのアクセスは5件。そのすべてが404でした。件数としては多くありませんが、サイトマップ確認の流れの中で発生していたため、ClaudeBotのURL探索パターンとして記録しておく価値があります。
216.73.216.220 [15/Apr/2026:12:35:10] GET /sitemap.xml → 404
216.73.216.220 [15/Apr/2026:12:52:36] GET /sitemap_index.xml → 200
216.73.216.220 [15/Apr/2026:14:44:28] GET /sitemap.xml → 404
216.73.216.220 [15/Apr/2026:18:01:25] GET /sitemap.xml → 404
216.73.216.220 [16/Apr/2026:12:48:31] GET /sitemap.xml → 404
・・・(計5回)ここで重要なのは、ClaudeBotが/sitemap_index.xmlを取得できていても、慣例的なURLである/sitemap.xmlを別途探しに来ている点です。
WordPressにYoast SEOを入れている場合、通常のサイトマップURLは/sitemap_index.xmlですが、クローラー側が/sitemap.xmlも確認対象にしている可能性があります。
404を受け取ったからといって、ClaudeBotが記事クロールを止めるわけではありません。今回のログでも、404を踏みながら並行して記事ページを取得していました。ただし、サイトマップURLで404が返り続ける状態は、クローラーにとって余計な確認を増やす要因になります。
対策:sitemap.xmlをsitemap_index.xmlへリダイレクトする
WordPressで/sitemap_index.xmlを使っている場合は、/sitemap.xmlへのアクセスを/sitemap_index.xmlへ301リダイレクトしておくと、404を減らせる可能性があります。
RewriteRule ^sitemap\.xml$ /sitemap_index.xml [R=301,L]設定後はサーバーログで、/sitemap.xmlへのアクセスが404ではなく301で返っているかを確認してください。
行動パターン③:4月ログでは、llms.txt取得後に記事クロールが続いた
初回観測(2026年4月)のログの中で、ClaudeBotが複数の記事ページを連続して取得したタイミングがありました。その直前に記録されていたのが、/llms.txtへのアクセスです。
実際のログは下記の通り。
216.73.216.164 [17/Apr/2026:18:27:09] GET /sitemap_index.xml → 200
216.73.216.164 [17/Apr/2026:18:33:20] GET /llms.txt → 200
216.73.216.164 [17/Apr/2026:18:33:21] GET /why-competitor-cited-by-ai/ → 200
216.73.216.164 [17/Apr/2026:18:35:47] GET /ai-kansoku-tool/ → 200
216.73.216.164 [17/Apr/2026:18:36:55] GET /index.md → 200
216.73.216.164 [17/Apr/2026:18:38:38] GET /ai-crawler-japan-chatgpt-user/ → 200
216.73.216.164 [17/Apr/2026:18:39:06] GET /ai-citation-boundary/ → 200/llms.txtを取得した1秒後に記事ページへアクセスし、その後約6分のあいだに記事ページ4本と/index.mdを取得していました。それまで/sitemap_index.xmlの確認が中心だったClaudeBotが、このタイミングで本文ページの取得に進んだように見えます。
llms.txtは、サイトの内容や重要なページをAI向けに整理して伝えるためのファイルです。サイトの目的や主要記事を簡潔にまとめておくことで、AIクローラーがページ構成を理解しやすくなる可能性があります。
ですが、今回のログだけで「llms.txtが記事クロールの直接的なトリガーになった」と断定することはできません。確認できるのは、llms.txt取得後に記事ページとindex.mdへのアクセスが続いたという時系列上の事実です。
6月の観測では/llms.txtへの直接アクセスは確認できませんでした。4月時点で見られたこの動きが継続しているかどうかは、引き続き観測していきます。
とはいえ、ClaudeBotが/llms.txtを取得した直後に本文ページへ進んだ記録は、サイト運営者にとって注目すべきデータです。まだllms.txtを設置していないサイトは、設置を検討する価値があります。設置方法はllms.txtの書き方・設置手順の記事でまとめています。
行動パターン④:タグページを繰り返し巡回する
記事クロールと並行して目立ったのが、タグページへのアクセスです。今回の539件のログでは、タグページが137件(25%)と記事ページ(120件)を上回り、全URL種別の中で最も多く記録されました。
実際のログは下記の通り。
216.73.216.164 [17/Apr/2026:19:55:05] GET /tag/国別/ → 200
216.73.216.164 [17/Apr/2026:20:01:41] GET /tag/診断ツール/ → 200
216.73.216.164 [17/Apr/2026:20:01:49] GET /tag/競合サイト/ → 200
216.73.216.164 [17/Apr/2026:21:10:31] GET /tag/国別/ → 200
216.73.216.164 [17/Apr/2026:22:40:08] GET /tag/国別/ → 200
216.73.216.164 [17/Apr/2026:22:42:47] GET /tag/競合サイト/ → 200
216.73.216.164 [17/Apr/2026:22:55:00] GET /tag/AI可視性スコア/ → 200
216.73.216.164 [17/Apr/2026:22:58:07] GET /tag/AI検索トレンド/ → 200「国別」「競合サイト」「診断ツール」といったタグページにアクセスしており、一部のタグページには同じ巡回内で複数回アクセスしていました。タグページには関連する複数の記事がリスト表示されるため、ClaudeBotがタグページを「関連記事をまとめて発見する入口」として使っている可能性があります。
サイト運営者への示唆としては、タグページがAIクローラーの巡回経路になり得るということです。関連性の高い記事を同じタグでまとめておくと、ClaudeBotが関連記事をたどりやすくなる可能性があります。
対して、タグが細かく分かれすぎていたり、関連性の低い記事が同じタグに混在していたりすると、ClaudeBotがタグページを巡回しても、サイトのテーマや記事同士の関係をつかみにくくなるかもしれません。
ClaudeBotの巡回を確認・改善するためにやるべき3つのこと
539件のログから見えたClaudeBotの行動パターンをもとに、サイト運営者がすぐに確認できる対策を3つにまとめます。
① robots.txtでClaudeBotをブロックしていないか確認する
Anthropic公式では、ClaudeBotのクロール制御にはrobots.txtを使うと説明されています。ClaudeBotは今回のログでもrobots.txtを繰り返し確認していたため、まずブロック設定が入っていないか確認しておく必要があります。
# これがあるとClaudeBotをブロックする
User-agent: ClaudeBot
Disallow: /ClaudeBotの巡回を許可したい場合は、上記のようなブロック設定を入れないことが基本です。robots.txtの設定方法はrobots.txtでAIクローラーを制御する記事で詳しくまとめています。
② llms.txtを設置する
今回の4月ログでは、ClaudeBotが/llms.txtを取得した直後に、記事ページと/index.mdへのアクセスが続いていました。ただし、この時系列だけでllms.txtが直接のトリガーになったと断定することはできません。
llms.txtは、サイトの内容や重要なページをAI向けに整理して伝えるためのファイルです。公式のクロール制御手段ではありませんが、サイト構造や主要コンテンツを整理して示す補助ファイルとして、設置を検討する価値があります。設置方法はllms.txtの書き方・設置手順の記事でまとめています。
③ sitemap.xmlへのリダイレクトを設定する
WordPressでYoast SEOを使っている場合、サイトマップURLは通常/sitemap_index.xmlです。今回のログでは、ClaudeBotが/sitemap_index.xmlを取得できている一方で、存在しない/sitemap.xmlにもアクセスし、404を受け取っていました。
/sitemap.xmlへのアクセスを/sitemap_index.xmlへ301リダイレクトしておくと、ClaudeBotが404を踏む回数を減らせる可能性があります。
RewriteRule ^sitemap\.xml$ /sitemap_index.xml [R=301,L]設定後はサーバーログで、/sitemap.xmlへのアクセスが404ではなく301で返っているか確認してください。
まとめ
539件のログから見えたのは、ClaudeBotが一度だけサイトを見に来るのではなく、継続的に状態を確認しているということです。
今回のログでは、robots.txtでクロールルールを確認し、sitemap_index.xmlでサイト構造を確認し、さらに一部のタイミングではllms.txt取得後に記事ページやindex.mdへのアクセスが続いていました。ClaudeBotは単にトップページを読むだけではなく、サイト全体の構造を見ながら巡回しているように見えます。
また、6月13日には通常日の10倍超となる358件のアクセスが1日で記録されました。この動きからは、大規模な再クロールと、robots.txt・sitemap中心の定期確認を切り替えている可能性が見えてきました。
サイト運営者がまず確認したいのは、ClaudeBotがサイト構造を正しくたどれる状態になっているかです。robots.txtでブロックしていないか、llms.txtで主要ページを整理できているか、存在しないsitemap.xmlで404を返し続けていないか。この3つは、すぐに確認できるポイントです。
ClaudeやAI検索で引用されやすいサイト設計については、Claudeに引用されるサイトの作り方の記事もあわせて参考にしてください。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。


