PerplexityはWebをどう読んでいるのか—1,194件のログで見えたAI巡回の仕組み

Perplexityに引用されたい。AI検索にどう見られているのか知りたい。
このように考えたとき、多くの人はまずrobots.txtやUser-Agentを確認します。しかし実際に、PerplexityがWebをどのような頻度で巡回し、どんなリズムでページを読んでいるのかを、継続的なサーバーログから観測した情報はほとんどありません。
AI観測ラボでは、約3か月にわたりPerplexityBotのアクセスを継続的に観測しました。
今まで他のAIクローラーとは異なる、均等ではない「波型巡回」とも呼べる特徴的な動きが見えてきました。
この記事でわかること|📖:約8分
- PerplexityBotの役割とGPTBotとの本質的な違い
- 3か月・1,194件の実測ログで見えた「波型巡回」の特徴
- 記事数増加と巡回頻度の関係から見えた傾向
- robots.txtでの制御方法とPerplexity-Userとの違い
PerplexityBotとは何か
PerplexityBotは、AI検索エンジンPerplexityがWebサイトを巡回するための公式クローラーです。収集した情報はAIモデルの学習ではなく、ユーザーの質問に対してリアルタイムで回答を生成するために使われます。
Perplexityは「答えを返すAI検索」として知られています。質問を入力すると、Web上の複数のページを参照しながら回答を生成し、出典リンクを明示します。PerplexityBotはその回答の情報源となるページを収集するために、日々Webを巡回しています。
近年は「検索順位」だけではなく、「AIにどのように読まれているか」が新しい可視性として注目され始めています。PerplexityBotは、その変化を象徴するAIクローラーのひとつです。
User-Agentは以下のとおりです。
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)IPアドレスは公式ドキュメントで公開されており、AI観測ラボの実測では18.97.9.96〜103の連番IPによる並列アクセスも確認できました。これは複数IPを使いながら、短時間でまとめてページを取得している可能性を示しています。
実測ログで見えたPerplexityBotの巡回パターン
AI観測ラボでは2026年2月末から5月17日まで、サーバーログとNeonDBを使いPerplexityBotのアクセスを継続観測しました。観測期間中の総アクセス数は1,194件にのぼります。
月別推移—巡回件数は右肩上がりで増加した
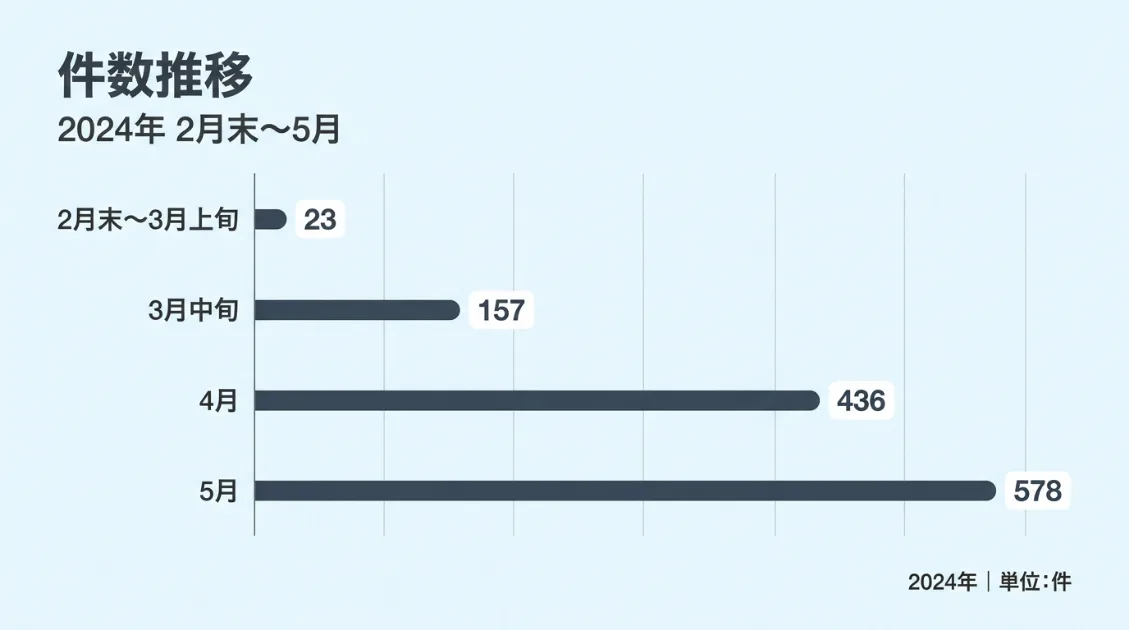
月別の巡回件数を集計したところ、以下のような推移が見えました。
| 期間 | 件数 | 備考 |
|---|---|---|
| 2月末〜3月上旬 | 23件 | サイト開設直後 |
| 3月中旬 | 157件 | 最初の大型巡回 |
| 4月 | 436件 | 本格巡回開始 |
| 5月1〜17日 | 578件 | 巡回頻度が最大化 |
サイト開設直後の2月末は23件にとどまっていた巡回が、4月には436件、5月上旬だけで578件まで増加しています。観測期間中に記事数が増えるにつれて、PerplexityBotの巡回頻度も比例して高まっていく傾向が見えました。
AI検索の文脈では「良質なコンテンツを作ればAIに引用される」という話はよく聞きます。しかし実測ログから見えたのは、それ以前の段階として「記事数や情報量の増加に伴い、PerplexityBotの巡回頻度そのものが高まっていく傾向」でした。
もちろん巡回頻度だけで引用可否が決まるわけではありません。ただ少なくともPerplexityBotは、更新や情報蓄積が続いているサイトを継続的に観測している可能性があります。
PerplexityBotの巡回には「波」がある
月別推移で巡回件数の増加が見えました。しかし日別データをさらに細かく見ると、もう一つの特徴が浮かび上がってきました。PerplexityBotは毎日均等に来るのではなく、「まとめて来る日」と「ほとんど来ない日」が交互に現れる波型の巡回パターンを持っています。
50件超えの大型巡回日が繰り返し発生した
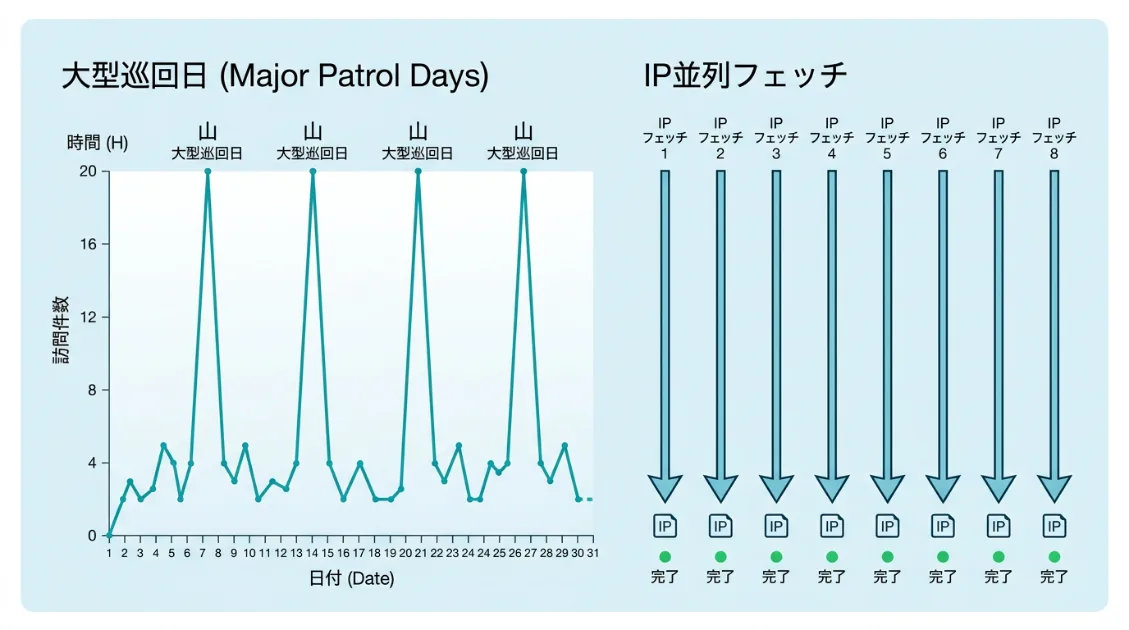
4月以降のNeonDBデータで、1日あたり50件を超えた大型巡回日を抽出したところ、以下の8日が確認できました。
| 日付 | 件数 |
|---|---|
| 2026-04-22 | 64件 |
| 2026-04-26 | 85件 |
| 2026-04-27 | 66件 |
| 2026-04-30 | 81件 |
| 2026-05-01 | 52件 |
| 2026-05-04 | 96件 |
| 2026-05-06 | 106件 |
| 2026-05-09 | 63件 |
大型巡回日の間隔を見ると、2〜4日おきに集中アクセスが発生しているパターンが繰り返されています。毎日少しずつ来るのではなく、「まとめて読んで、しばらく間を置いて、またまとめて読む」というリズムです。
これは従来の検索エンジン型クローラーとは少し異なる、「必要時にまとめて取得するAI検索型」の特徴を示している可能性があります。
8つのIPが同時並走する並列フェッチ
サーバーログでIPアドレスを確認したところ、18.97.9.96〜103の連番8IPが同じタイミングで並列アクセスしていました。1つのIPが順番にページを読むのではなく、複数のIPが同時に異なるページを取得していく動き方です。
大型巡回日にアクセス件数が跳ね上がる背景には、この並列フェッチによって短時間で大量のページを取得できる仕組みがあると考えられます。
PerplexityBotとGPTBotは「まったく違う巡回」をしていた
AI観測ラボでは、PerplexityBotと同時期にGPTBotの巡回も観測しています。両者を比較すると、巡回スタイルに明確な違いが見えてきました。
| 項目 | PerplexityBot | GPTBot |
|---|---|---|
| 巡回スタイル | サイト全体を広く巡回 | 特定ページに集中 |
| 巡回リズム | 波型(2〜4日おき) | 不定期・一気読み型 |
| IP構成 | 8IP並列フェッチ | 単一〜少数IP |
| ページ偏り | ほぼなし(最大4件/ページ) | あり(1ページに109件の例) |
| robots.txt確認 | 毎セッションの起点で確認 | 巡回前に確認 |
| 主な目的 | 検索結果への引用 | 学習データ収集 |
GPTBotは特定の記事ページに集中してアクセスする傾向があります。AI観測ラボの実測では、/oai-searchbot-guide/に109件のアクセスが集中していました。
一方PerplexityBotは、観測期間中にアクセスした記事ページのほぼすべてが最大4件以内にとどまっていました。特定ページへの集中は見られず、サイト全体を広く巡回していく動き方です。
この違いは、AIごとの役割の違いとも関係している可能性があります。GPTBotはモデル学習用のデータ収集を重視し、PerplexityBotはリアルタイム回答のためにサイト全体の情報を広く把握しようとしているように見えました。
robots.txtでの制御方法
PerplexityBotはrobots.txtの指示を確認してから巡回を開始します。AI観測ラボの実測でも、巡回開始時にrobots.txtへのアクセスが繰り返し記録されていました。
許可する場合
robots.txtに記述がない場合、PerplexityBotはデフォルトで巡回を許可されたと判断します。PerplexityのAI検索で参照される可能性を残したい場合、明示的な許可設定は不要です。
ブロックする場合
PerplexityBotの巡回を止めたい場合は、robots.txtに以下を追記します。
User-agent: PerplexityBot
Disallow: /特定ページだけ許可する場合
サイト全体は許可しつつ、特定ディレクトリだけ除外したい場合は以下のように記述します。
User-agent: PerplexityBot
Allow: /
Disallow: /private/
Disallow: /member/ブロックしても巡回が続く場合がある
2025年8月、CloudflareはPerplexity関連のアクセスについて「robots.txtの制限を回避している可能性がある」とする調査結果を公開しました。
PerplexityBotをブロックしてもアクセスが続く場合、別User-Agentやブラウザ経由の取得が行われている可能性もあります。完全な遮断が必要な場合は、WAFやASN単位での制御を組み合わせるケースもあります。
AI検索時代では、robots.txtだけでなく「どのAIに・どの範囲まで・どのように読ませるか」という設計自体が重要になり始めています。
PerplexityBotとPerplexity-Userは別物
Perplexityには複数のクローラーが存在します。混同されやすいため、役割の違いを整理しておきます。
| 項目 | PerplexityBot | Perplexity-User |
|---|---|---|
| 役割 | 定期的なインデックス巡回 | ユーザー質問に応じたリアルタイム取得 |
| 発生タイミング | 自律的・定期的 | ユーザーが質問したとき |
| robots.txt | 基本的に尊重 | 挙動が異なる場合がある |
| User-Agent | PerplexityBot/1.0 | Perplexity-User |
PerplexityBotは、定期的にWebを巡回してインデックスを更新するクローラーです。一方Perplexity-Userは、実際のユーザーがPerplexityへ質問を送信したタイミングで、回答生成のために該当ページをリアルタイムで取得しにくるアクセスです。
大きな違いのひとつがrobots.txtへの挙動です。PerplexityBotはrobots.txtを確認してから巡回する傾向がありますが、Perplexity-Userはユーザーリクエスト起点で動作するため、異なる取得パターンが見られるケースがあります。
なので、PerplexityBotをrobots.txtでブロックしても、Perplexity-User由来と思われるアクセスが継続する場合があります。2種類を個別に制御したい場合は、それぞれのUser-Agentを分けて記述する必要があります。
User-agent: PerplexityBot
Disallow: /
User-agent: Perplexity-User
Disallow: /AI検索時代では、「どのAIサービスが来ているか」だけではなく、「どの役割のクローラーなのか」を区別して考えることが重要になり始めています。
まとめ
PerplexityがWebをどう読んでいるのか。3か月・1,194件のサーバーログから、これまで見えにくかったAI検索クローラーの動きが少しずつ見えてきました。
- PerplexityBotはAI検索の回答生成のためにWebを巡回するクローラーで、学習目的のGPTBotとは役割が異なります
- 巡回件数は記事数の増加に伴って右肩上がりで増加していました
- 毎日均等に来るのではなく、2〜4日おきに大型巡回が発生する「波型巡回」の特徴が見えました
- 8つの連番IPによる並列フェッチで、短時間にサイト全体を広く巡回していました
- GPTBotが特定ページへ集中するのに対し、PerplexityBotはページ偏りがほとんど見られませんでした
- PerplexityBotとPerplexity-Userは別の役割を持ち、robots.txtへの挙動も異なります
AI検索時代では、「検索順位」だけがサイトの可視性を決める時代が少しずつ変わり始めています。どのAIが、どのくらいの頻度で、どんなページを読みに来ているのか。AIから見た可視性自体が、新しい観測対象になりつつあります。
PerplexityBotの巡回パターンは、従来の検索エンジンクローラーとも、GPTBotのような学習系クローラーとも異なる特徴を持っていました。AI検索は単に「検索結果の形」が変わっただけではなく、Webの読み方そのものを変え始めているのかもしれません。
AI観測ラボでは、引き続きPerplexityBotや各種AIクローラーの巡回パターンを継続観測していきます。新しい傾向が確認でき次第、続報として追記・公開予定です。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。