ClaudeBotとは—Anthropicの3つのボットと実測ログで見えた巡回の仕組み

サーバーログに ClaudeBot という文字列が現れた。このAIはAnthropic社が運用するAIクローラーです。
Anthropicのクローラーが1種類ではないという点です。現在は用途の異なる3つのボットが運用されており、それぞれ役割・挙動・robots.txtへの対応が異なります。
AI観測ラボでは、2026年3月〜5月の観測期間中に合計4,072件のClaudeBot系アクセスを記録しました。この記事では、実測ログをもとに3つのボットの違いと巡回の仕組みを整理します。
この記事でわかること|📖:約6分
- ClaudeBotとClawdBotの違い——混同される理由と正しい意味
- Anthropicが運用する3つのボットの役割と違い(ClaudeBot・Claude-User・Claude-SearchBot)
- AI観測ラボの4,072件の実測ログで見えた巡回パターン
- robots.txtでの制御方法と、許可・ブロックの判断基準
ClaudeBotとは——Anthropicが運用するAIクローラー
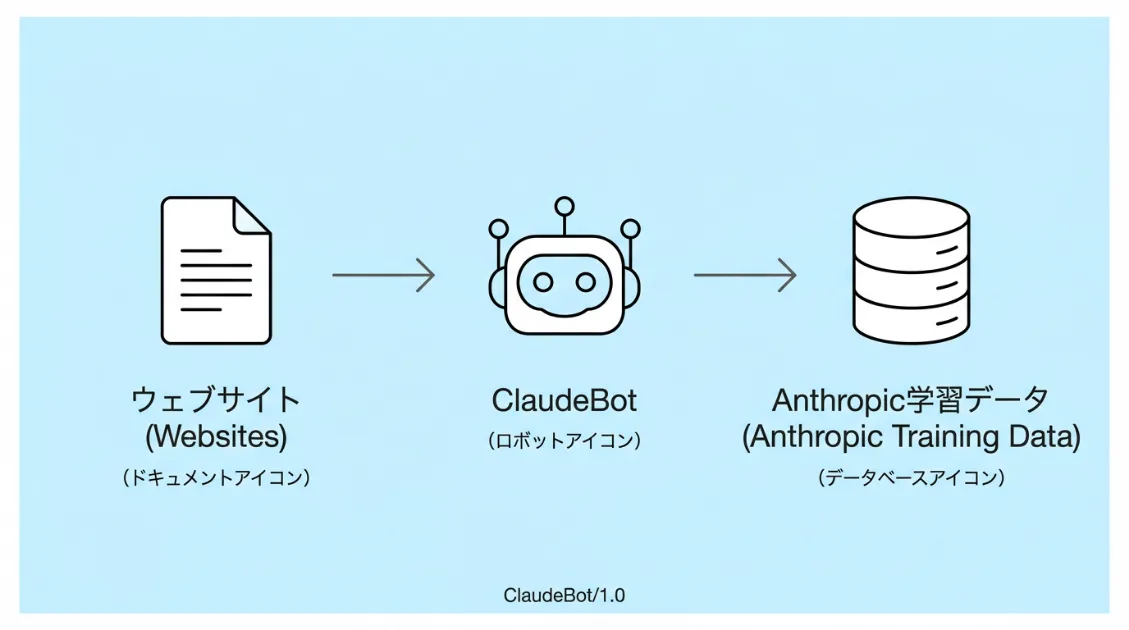
ClaudeBotは、AIアシスタント「Claude」を開発するAnthropic社が運用するウェブクローラーです。公開されたウェブページを自動的に巡回し、ClaudeのAIモデル学習に利用されるデータを収集しています。
仕組みとしてはGooglebotに近く、ウェブサイトを巡回してHTMLを取得します。ただ、ClaudeBotによるクロールはGoogle検索順位には直接影響しません。あくまでClaude系AIの学習や品質改善を目的としたクローラーです。
サーバーログでは、以下のようなUser-Agentで記録されます。
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)なお、2026年3月時点では旧形式のUser-Agentも一部確認されていましたが、現在は上記の新形式へほぼ統一されています。
「ClawdBot」との混同——検索結果で起きている意味の分裂
「ClaudeBot」で検索すると、Anthropicのクローラーとは別のソフトウェアが検索結果に混在しています。
それが「ClawdBot」(後にOpenClawへ改名)というオープンソースのAIエージェントです。名前の由来はカニのはさみを意味する「Claw」で、Anthropicとは無関係のプロジェクトです。
混同が起きやすい理由は主に3つあります。
- 「ClaudeBot」と「ClawdBot」でスペルが非常に近い
- ClawdBotが2026年初頭にAnthropicから商標に関する指摘を受け、OpenClawへ改名した経緯がある
- 「Claude系AI全般」をまとめて「ClaudeBot」と表現している記事が存在する
サーバーログに ClaudeBot/1.0 と記録されていた場合、Anthropicのクローラーです。
ClawdBot(OpenClaw)はユーザーのローカル環境で動作するAIエージェントであり、ウェブクローラーではありません。そのため通常、サーバーログに現れることはありません。
Anthropicのボットは3種類——役割がまったく異なる
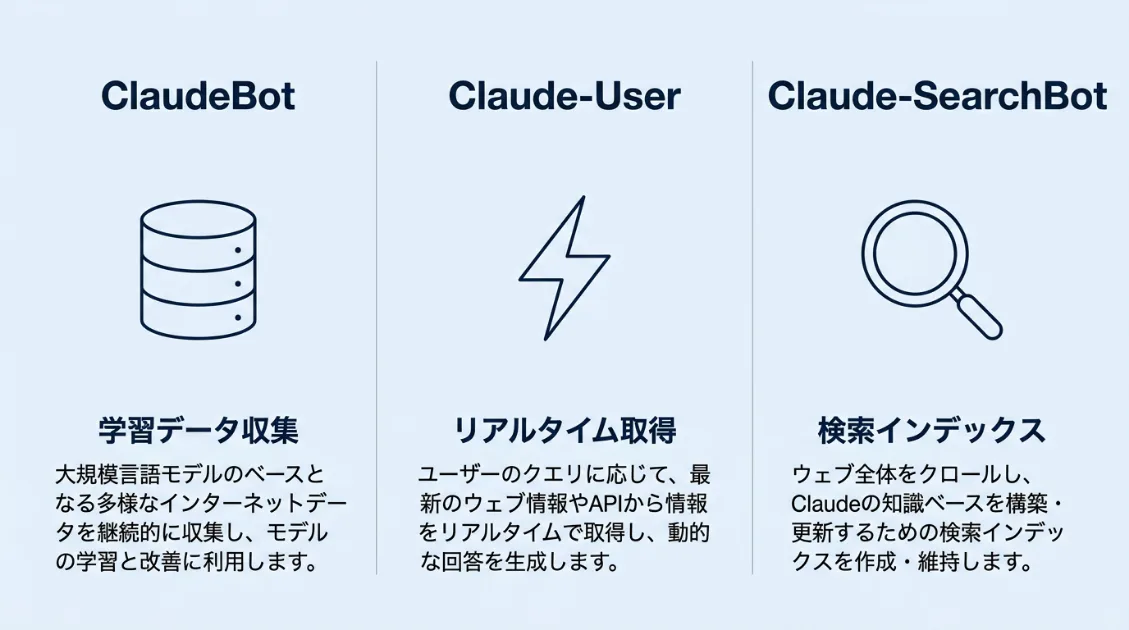
Anthropicのクローラーを理解するうえで重要なのは、「ClaudeBot」が単一のボット名ではないという点です。現在は用途の異なる3つのボットが運用されており、各bot役割・巡回パターン・robots.txtへの対応が異なります。
| ボット名 | 主な役割 | 来訪の特徴 | robots.txt対応 |
|---|---|---|---|
ClaudeBot |
AIモデルの学習データ収集 | sitemap・robots.txt中心。24時間巡回 | 準拠する |
Claude-User |
ユーザーの質問に連動したリアルタイム取得 | 特定記事にピンポイントアクセス。不定期 | ユーザー操作時は例外あり |
Claude-SearchBot |
Claude検索機能向けのインデックス収集 | AI観測ラボの観測期間中は来訪ゼロ | 準拠する |
3つのボットはUser-Agentで識別できます。
# ClaudeBot(学習用)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
# Claude-User(リアルタイム取得)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Claude-User/1.0; +claude-user@anthropic.com)
# Claude-SearchBot(検索インデックス)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Claude-SearchBot/1.0; +claude-searchbot@anthropic.com)AI観測ラボの2026年3月〜5月の観測では、ClaudeBotが4,226件、Claude-Userが55件を記録しました。一方、Claude-SearchBotは観測期間中にログへの記録を確認できませんでした。
つまり現時点では、Anthropic系アクセスの大半は学習用のClaudeBotで構成されていることになります。
AI観測ラボの実測ログで見えたClaudeBotの巡回パターン
AI観測ラボでは2026年3月〜5月にかけてサーバーログとNeonDBの記録を照合し、ClaudeBot系のアクセスを継続的に観測しました。観測期間中の総アクセス数は4,226件です。
パターン1:robots.txt → sitemap_index.xml の順番で必ず確認する
ClaudeBotは巡回を始める前に、必ずrobots.txtを取得します。そしてrobots.txt直後にsitemap_index.xmlを取得するパターンが一貫して確認できました。
3月のログでは、robots.txtが69件、sitemap_index.xmlが75件記録されており、記事本文より先にサイト構造の把握を優先していることがわかります。

パターン2:記事本文よりタグページを優先して巡回する
3月のログを確認すると、ClaudeBotは個別記事よりもタグページへのアクセスが目立ちます。/tag/claudebot/や/tag/aiクローラー-拒否/といったタグページを複数巡回しており、記事単体ではなく、タグ単位でトピックのまとまりを把握しようとしているような巡回パターンが見られました。
パターン3:24時間止まらず巡回する
時間帯別の分布を見ると、深夜0時台・早朝5時台・午前10時台・夜18時台・21時台にやや集中しているものの、全時間帯でアクセスが確認できました。
「AIクローラーは深夜に動く」とよく言われますが、ClaudeBotに限っては特定の時間帯に偏らず24時間巡回しています。
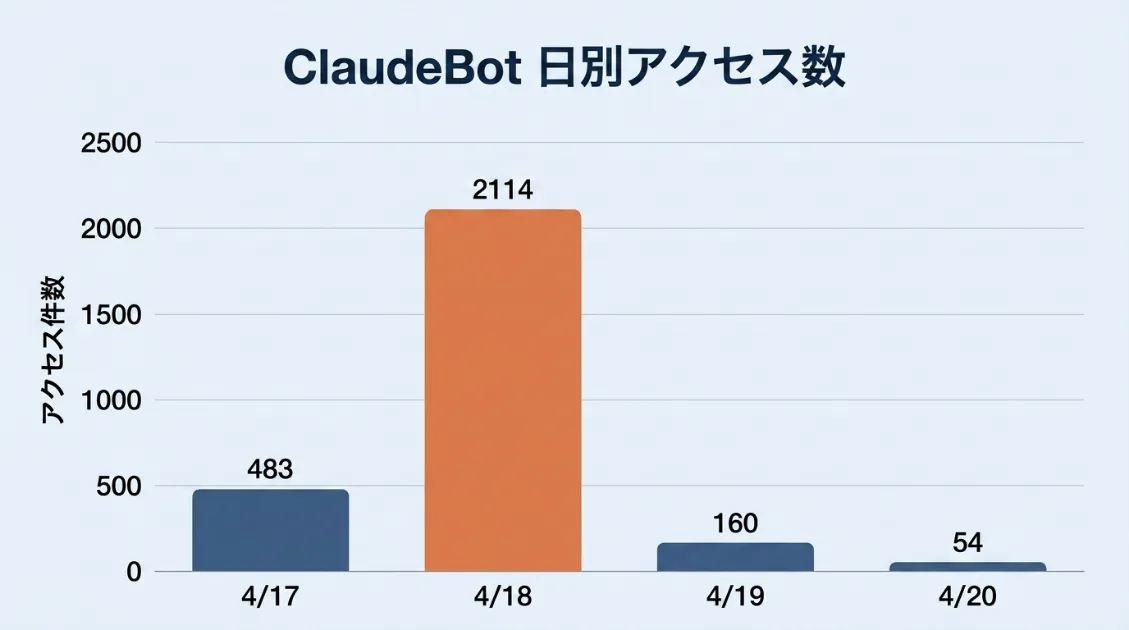
パターン4:4/18に通常の約26倍のアクセスが発生した
NeonDBのデータでは、2026年4月18日に2,114件という突出したアクセスを記録しました。前後の日は30〜80件程度で推移しており、特定のタイミングで大量巡回が発生したことになります。
原因は特定できていません。Anthropic側のモデル更新や再学習タイミングと重なっていた可能性はあります。
Claude-Userはまったく別の動きをする
Claude-Userの55件は、ClaudeBotとは性質が異なります。ユーザーがClaudeに質問したタイミングで、回答の根拠となるページをリアルタイムで取得しに来ます。
AI観測ラボでは/claude-citation-guide/や/chatgpt-ads-organic-citation/といった特定の記事に絞ってアクセスしてくる動きを確認しています。
robots.txtを巡回するClaudeBotとは異なり、Claude-Userは目的のページへ直接アクセスする点が特徴です。
robots.txtでの制御方法——3つのボットを個別に設定する
ClaudeBot・Claude-User・Claude-SearchBotはそれぞれ独立したUser-Agentを持っています。robots.txtでは3つを個別に設定できます。目的に応じて以下の3パターンから選んでください。
パターン1:すべて許可する(現在の標準状態)
robots.txtに何も書かなければ、すべてのボットのアクセスを許可した状態になります。Claudeの学習データへの提供と、Claude-Userによるリアルタイム引用の両方を受け入れる設定です。
# 何も書かなければ全許可
# ClaudeBot・Claude-User・Claude-SearchBot すべてアクセス可パターン2:学習データ収集だけをブロックする
ClaudeBotによる学習データ収集は拒否しつつ、Claude-Userによるリアルタイム引用は許可したい場合の設定です。
「Claudeの回答には引用されたいが、学習データとしては利用されたくない」という場合に使われる設定です。
User-agent: ClaudeBot
Disallow: /パターン3:Anthropic系をすべてブロックする
3つのボットすべてのアクセスを拒否する場合は、それぞれ個別に記述が必要です。1つだけ書いても残りのボットは止まりません。
User-agent: ClaudeBot
Disallow: /
User-agent: Claude-User
Disallow: /
User-agent: Claude-SearchBot
Disallow: /Anthropicの公式ヘルプページによると、ClaudeBotはrobots.txtの記述を尊重します。CAPTCHAをバイパスしようとしない点も明記されています。
また、クロール頻度を下げたい場合はCrawl-delayの設定にも対応しています。
User-agent: ClaudeBot
Crawl-delay: 10注意点が1つあってCrawl-delayはすべてのクローラーが厳密に対応しているわけではなく、実際の動作は各ボット側の実装に依存します。
robots.txt全体の考え方や、GPTBot・PerplexityBotを含めたAIクローラー制御については、以下の記事でも詳しく整理しています。
内部リンク:robots.txt完全ガイド|AIクローラー制御—実測ログで見えた設計の正解
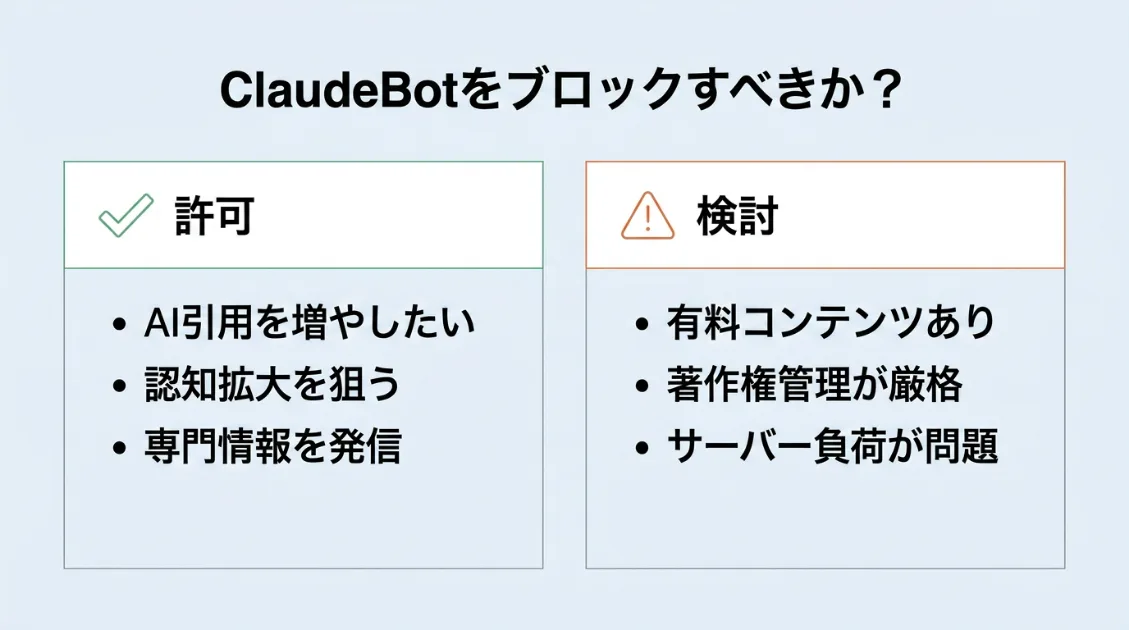
ClaudeBotは許可すべきか・ブロックすべきか
結論から言うと、一般的な情報サイトではClaudeBotを積極的にブロックする理由はそれほど多くありません。サイトの目的や公開範囲によって判断は変わります。以下の基準を参考にしてください。
許可した方がよいケース
- Claudeの回答に自サイトのコンテンツが引用される機会を増やしたい
- AI検索経由での認知拡大を狙っている
- 一次情報・専門情報を発信しており、AI検索経由での参照を増やしたい
ブロックを検討するケース
- 有料コンテンツ・会員限定コンテンツが公開URLでアクセスできる状態になっている
- コンテンツの著作権管理を厳格に行っている
- サーバー負荷が問題になっている(Crawl-delayで対応する選択肢もある)
注意したいのは、ClaudeBotをブロックしてもClaude-Userは別のUser-Agentとして動作する点です。
「Claudeに引用されたくない」という目的でClaudeBotだけを拒否しても、Claude-User経由のリアルタイム取得は継続する可能性があります。
重要なのは、「Anthropic系を止めたい」のか、「学習だけ止めたい」のかを分けて考えることです。
AIクローラー全体の考え方については、以下の記事でも整理しています。
内部リンク:AIクローラーを拒否する前に知っておくべきこと
まとめ——ClaudeBotは「3種類ある」を起点に理解する
ClaudeBotは単なる「AIクローラー」ではなく、役割の異なる3つのボット群として理解する必要があります。AI観測ラボの実測ログをもとに、その違いと巡回パターンを整理しました。
- ClaudeBotはAnthropicが運用するAIクローラーで、OSSの「ClawdBot」とはまったくの別物
- Anthropicのボットは3種類あり、ClaudeBot・Claude-User・Claude-SearchBotで役割が異なる
- ClaudeBotは必ずrobots.txt→sitemap_index.xmlの順番で確認してから巡回する
- 2026年4月18日には通常の約26倍にあたる2,114件のアクセス急増が発生した
- Claude-Userは学習目的ではなく、ユーザーの質問に連動した特定記事へのリアルタイム取得
- robots.txtでは3つのボットを個別に設定する必要がある
ClaudeBotの巡回行動パターンや、Claude系AIへの引用構造については、以下の関連記事でも詳しく解説しています。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。