ChatGPTに引用されるサイトの条件|AIに読まれやすいページ設計とは

自分のサイトが、ChatGPTの回答に出てきたことはありますか。
Perplexityで調べたときに、見覚えのあるサイト名が引用欄に並んでいた。
引用欄に掲載される状態は、どうすれば作れるのでしょうか。
結論から言うと、引用される前に、まずAIに「読まれる」状態を作ることが先です。
ChatGPTまわりには、目的の違うBotが複数あります。学習や改善のためにページを読むBotもあれば、ChatGPT検索に関係すると考えられるBotもあります。
AI観測ラボのサーバーログでは、2026年6月だけでGPTBotとOAI-SearchBotのアクセスを合計816件確認しました。
もちろん、Botが来たからといって必ず引用されるわけではありません。ただ、AIがページを取得できない状態では、引用される可能性はかなり低くなります。
この記事では、まずAIに読まれる設計を整えるために必要な4つの条件を、実測データをもとに整理します。
この記事でわかること|📖:約5分
- ChatGPTがサイトを読みに来る3種類のBotの役割の違い
- 実測ログから見えた、OpenAI系Botのページの読み方
- AIに読まれやすいページ設計の4つの条件
- 「GPTBotを許可すれば引用される」は半分正解である理由
ChatGPTに引用される前に、まずAIに読まれる必要がある
「構造化データを入れた」「robots.txtも設定した」「でもChatGPTに引用されない。」
サイト運営者から、よく聞く話です。
しかしながら引用されない理由は、構造化データや設定だけで説明できるとは限りません。
その前段階として、そもそもBotがページを取得できていない、という状態が起きている可能性があります。
ChatGPTに引用されるまでには、大きく2つのステップがあります。
- ①BotがページをHTTPで取得する(読む)
- ②取得した内容が回答に使われる(引用される)
②に悩む前に、まず①が起きているかを確認する必要があります。
AI観測ラボのサーバーログを確認したところ、2026年6月だけでGPTBotが401件、OAI-SearchBotが415件アクセスしていました。合計816件です。
注目したのは、取得ページの内訳です。
GPTBotとOAI-SearchBotという目的が異なる2つのBotが、同じページを109件ずつ取りに来ていました。
これは、OpenAI系Botが特定のページを繰り返し取得していたことを示す実測ログです。
無論、Botが来たからといって必ず引用されるわけではありません。
引用を狙うなら、まずAIに読まれる状態を作ることが先決です。
ChatGPTには3つのBotがある
ChatGPTがサイトを読みに来るとき、実は1種類のBotだけが動いているわけではありません。
OpenAIが公開している情報によると、ChatGPT関連のBotは大きく3種類あります。
| Bot名 | 主な目的 | robots.txtで制御できるか |
|---|---|---|
| GPTBot | AIモデルの学習・改善のためのデータ収集 | できる |
| OAI-SearchBot | ChatGPT検索でWebページを取得・表示するため | できる |
| ChatGPT-User | ユーザー操作に応じたリアルタイム取得 | できない |
3つのBotは、目的がまったく異なります。
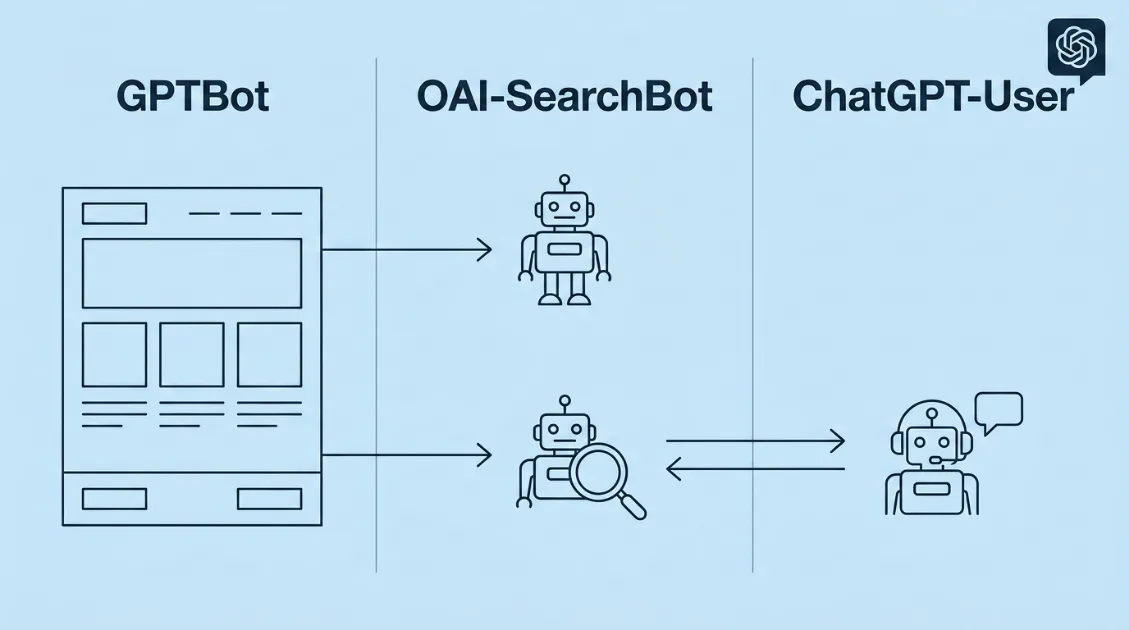
GPTBotは、ChatGPTのモデル自体を改善するためのデータ収集が目的です。
OAI-SearchBotは、ChatGPT検索でWebページを参照・表示するために使われるBotです。
ChatGPT-Userは、ユーザーが会話中にURLを貼り付けたときなどに、その場でページを読みに来るBotです。
ChatGPT検索でサイトが参照・表示されることを考えるなら、特に重要なのはOAI-SearchBotです。
GPTBotを許可するだけでは不十分な理由は、次のセクションで説明します。
BotごとにWebページの読み方が違う
3つのBotは目的が違うだけでなく、サイトへのアクセスの仕方も異なります。
AI観測ラボのサーバーログから、それぞれの動きを確認しました。
GPTBot—サイトマップから記事へ入る
GPTBotは、サイトマップを確認してから個別の記事を取得する動きをしていました。
今回の計測期間中、GPTBotはsitemap_index.xmlを8件確認していました。
なので、サイトマップに重要なページが載っていない状態は、GPTBotにページを見つけてもらううえで不利になる可能性があります。
OAI-SearchBot—robots.txtを確認してから記事と画像まで取得する
OAI-SearchBotはrobots.txtを39件確認していました。GPTBotのサイトマップ確認(8件)と比べると、設定ファイルへのアクセス頻度が高い動きです。
さらに注目したのは、画像の取得です。
OAI-SearchBotは記事本文だけでなく、webp形式の画像ファイルも複数回取得していました。
このログからは、OAI-SearchBotが本文だけでなく、ページ内の画像情報まで見に来ている可能性があると考えられます。
ChatGPT-User—ユーザーの操作に合わせてその場で取得する
ChatGPT-Userは、ユーザーがChatGPTの会話中にURLを貼り付けたときなどに、その場でページを読みに来るBot。
定期巡回ではなく、ユーザー操作に近いリアルタイム取得のため、robots.txtでは制御できません。
ページが表示できない、読み込みが遅い、ログインが必要、といった状態だと、ChatGPT-Userに正しく読まれない可能性があります。
3つのBotの動きをまとめると
| Bot名 | 確認していたもの | 取得対象 | 巡回タイプ |
|---|---|---|---|
| GPTBot | サイトマップ | 記事本文 | 定期巡回 |
| OAI-SearchBot | robots.txt | 記事本文+画像 | 定期巡回 |
| ChatGPT-User | 指定URL | 指定ページ | リアルタイム取得 |
ChatGPT検索での参照・表示を考えるなら、特にOAI-SearchBotに正しく読まれる状態を作ることが重要です。
AIに読まれやすいページ設計の4つの条件
AIに読まれやすい状態を作るために、今日から整えられる条件が4つあります。
識者の多くは「構造化データを入れましょう」「E-E-A-Tを意識しましょう」という話で終わっています。
ですが実際のログを見ると、OpenAI系Botが繰り返し取得していたページには、いくつか共通した設計がありました。
条件1:AIクローラーを拒否していない
当たり前に聞こえますが、見落としが起きやすい条件です。
確認が必要なのは3つです。
- robots.txtでOAI-SearchBotをDisallowしていないか
- WordPressのnoindex設定が、重要な記事ページに誤って適用されていないか
- WAFやセキュリティ設定でOpenAI系Botのアクセスをブロックしていないか
robots.txtの設定例はこちらです。
User-agent: GPTBot
Allow: /
User-agent: OAI-SearchBot
Allow: /GPTBotとOAI-SearchBotは独立して設定できます。学習は拒否しつつ、ChatGPT検索には表示されたい場合は以下のように分けて書けます。
User-agent: GPTBot
Disallow: /
User-agent: OAI-SearchBot
Allow: /詳しい設定方法はChatGPT検索に出たいなら、止めるBotを間違えないで解説しています。
条件2:ページの主題がすぐわかる
AIがページを取得したあと、その内容を回答材料として使えるかどうかを判断しやすくするには、ページの主題が明確であることが重要です。
特に大事なのは、ページの冒頭です。
- タイトルとH1の主題がズレていない
- 冒頭の100〜200字以内に結論または定義が書かれている
- 何についてのページかが最初の段落で明確になっている
「前置きが長い記事」「結論が最後にしか出てこない記事」は、AIに主題を判断してもらいにくい構造です。
結論を先に書く。シンプルですが、AIに読まれやすいページ設計の基本です。
条件3:切り出して使いやすい構造になっている
ChatGPTが回答を作るとき、取得したページの内容をそのまま全文で使うわけではありません。
回答に使いやすい部分を見つけやすい構造になっていることが重要です。
切り出しやすい構造とは、下記のような設計です。
- 1つの見出しに1つのトピックだけ書かれている
- 箇条書きや表で情報が整理されている
- Q&A形式で質問と答えがセットになっている
逆に切り出しにくいのは、1つの見出しの中に複数のトピックが混在しているページです。
AIは「この見出しの中に、回答に使える情報があるか」を見ます。トピックが混在していると、どこを使えばよいか判断しにくくなります。
条件4:他にはない一次情報がある
あらゆるメディアと同じ内容をまとめただけのページは、引用候補として選ばれにくくなります。
AIにとっても価値が高いのは、他では手に入らない情報です。
- 実測データ・サーバーログ・検証結果
- 自社調査・アンケート結果
- 専門家や運営者自身の一次体験
AI観測ラボでOAI-SearchBotが109件集中取得していたページは、GPTBotの実測ログとrobots.txtの設定方法を組み合わせた記事でした。
「実際に計測した」「実際に確認した」という一次情報は、AIにとってもページの独自性を判断しやすい材料になっている可能性があります。
よくある誤解
誤解1:GPTBotを許可すればChatGPT検索に出る
半分正解、半分間違いです。
GPTBotはAIモデルの学習・改善のために使われるBotです。GPTBotを許可したからといって、ChatGPT検索にそのまま表示されるわけではありません。
ChatGPT検索でサイトが参照・表示されることを考えるなら、特に確認したいのはOAI-SearchBotの許可状況です。
誤解2:構造化データを入れれば引用される
構造化データは、ページの情報を整理して伝えるための補助になります。
ですが、構造化データを入れる前に、そもそもBotがページを取得できているかが前提です。
Botに取得されていない状態で構造化データだけ整えても、引用につながるとは限りません。
設定の優先順位は「クローラーを拒否していない」が最初で、「構造化データ」はその次です。
誤解3:Googleで上位表示されていればChatGPTにも引用される
Googleで上位表示されていることは、もちろん大きな強みです。
がしかし、ChatGPT検索で参照されるかどうかは、Google検索の順位だけでは決まりません。
OpenAIのヘルプでは、ChatGPT検索が有効な場合、検索クエリなどがBingに送られる場合があると説明されています。そのため、GoogleだけでなくBing側でページが発見・インデックスされているかも確認しておきたいポイントです。
Googleで1位でも、Bing側でページが見つかりにくい状態だと、ChatGPT検索でも参照されにくくなる可能性があります。
Bing Webmaster Toolsへの登録とサイトマップ送信は、ChatGPT検索対策として確認しておきたい基本項目です。
登録手順はBing Webmaster ToolsのAI Performanceとはで確認できます。
まとめ:ChatGPTに引用されるには、まず取得される状態を作る
ChatGPTに引用されるサイトの条件を、実測ログをもとに整理しました。
| 条件 | 確認ポイント |
|---|---|
| AIクローラーを拒否していない | robots.txt・noindex・WAFの設定 |
| ページの主題がすぐわかる | 冒頭100〜200字以内に結論・定義がある |
| 切り出して使いやすい構造 | 1見出し1トピック・箇条書き・表 |
| 他にはない一次情報がある | 実測データ・検証結果・一次体験 |
AI観測ラボのログでは、OAI-SearchBotが同じページを繰り返し取りに来ていました。
該当ページには、AIクローラーの許可設定、主題の明確さ、切り出しやすい構造、実測ログという一次情報が含まれていました。
もちろん、Botが来たからといって必ず引用されるわけではありません。
が、AIに取得されない状態のままでは、ChatGPT検索で参照される可能性も高まりません。
引用を狙う前に、まず今日、robots.txtとnoindexの設定を確認してみてください。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。


