WebMCPとは?AIエージェントがWebサイトを操作する仕組みと運営者の準備

AIエージェントが、ブラウザ上でWebサイトを操作する時代が近づいています。
その流れの中で出てきた新しい仕組みが、WebMCP(Web Model Context Protocol)です。WebMCPは、AIエージェントがWebサイト上のフォーム入力、検索、予約、カート追加などの操作を、より正確に実行できるようにするための仕組みです。
たとえば、宿泊サイトで日付や人数を入力して予約候補を探す。ECサイトで商品を選び、カートに追加する。これまで人間がブラウザ上で行っていた操作を、AIエージェントが代わりに進められるようになる。そのための土台として、GoogleがChromeで実験を進めているのがWebMCPです。
WebMCP自体は2026年2月に早期プレビューとして公開され、2026年5月のGoogle I/O 2026でも「agentic web」の文脈で大きく取り上げられました。その後、2026年6月にはChrome 149のOrigin Trialとして、開発者が実際に試せる段階へ進んでいます。
Expedia、Booking.com、Shopify、Targetなどの大手サービスも実験に参加しており、まだ一般サイトに広く普及している段階ではないものの、サイト運営者にとって無視できない変化の入り口に来ています。
当記事では、WebMCPとは何か、MCPとは何が違うのか、そしてWebサイト運営者は今どこまで準備しておけばよいのかを、サーバーログ観測の視点から整理します。
この記事でわかること|📖:約7分
- WebMCPとは何か——AIエージェントがサイトを操作するための新しい仕組み
- MCPとWebMCPの違い——名前が似た2つの技術の役割の違い
- 従来の操作方法はなぜ不安定なのか——WebMCPが解決する課題
- 今どこまで進んでいるか——Chrome 149での実験と参加企業の現状
- サイト運営者が今準備しておきたいこと——ログ・HTML・robots.txtの観点から
WebMCPとは何か——AIエージェントのための「サイト操作の説明書」
WebMCPとは、AIエージェントがWebサイトを操作しやすくするための新しい仕組みです。正式名称は「Web Model Context Protocol」。
宿泊サイトで予約する場面を思い浮かべてください。人間がブラウザを開き、日付を入力して、空室を確認して、予約ボタンを押す。WebMCPが普及すると、AIエージェントが人間の代わりに、この一連の操作をブラウザ上で進められるようになります。
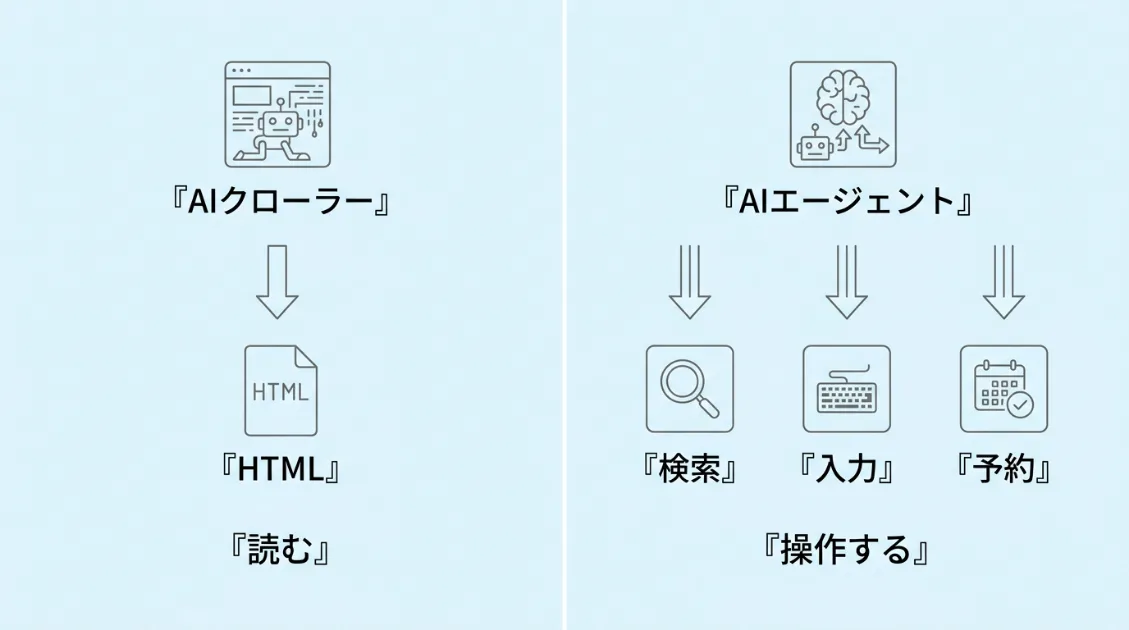
ここで押さえておきたいのが、AIクローラーとAIエージェントの違いです。GPTBotやClaudeBotといったAIクローラーは、サイトのHTMLを「読む」存在です。ページの内容を取得して学習データや回答生成に使いますが、ボタンを押したり、フォームを送信したりはしません。
対してAIエージェントは、ブラウザを操作して実際に「行動する」存在です。検索条件を入力する、候補を選ぶ、フォームを送る、といった操作を人間の代わりに進めます。
WebMCPは、サイト側が「ここでは検索できます」「ここでは予約できます」と、AIエージェントに操作の入口をわかりやすく伝えるための仕組みです。AIエージェントが画面を見て手探りで判断するのではなく、サイト側が用意した説明書をもとに、より正確に操作できるようになるイメージです。
WebMCPの詳細は下記Googleの公式ドキュメントで確認できます。
MCPとWebMCPは何が違うのか
WebMCPという名前を見て、「MCPと何が違うのか」と感じた方も多いと思います。名前は似ていますが、役割は異なります。
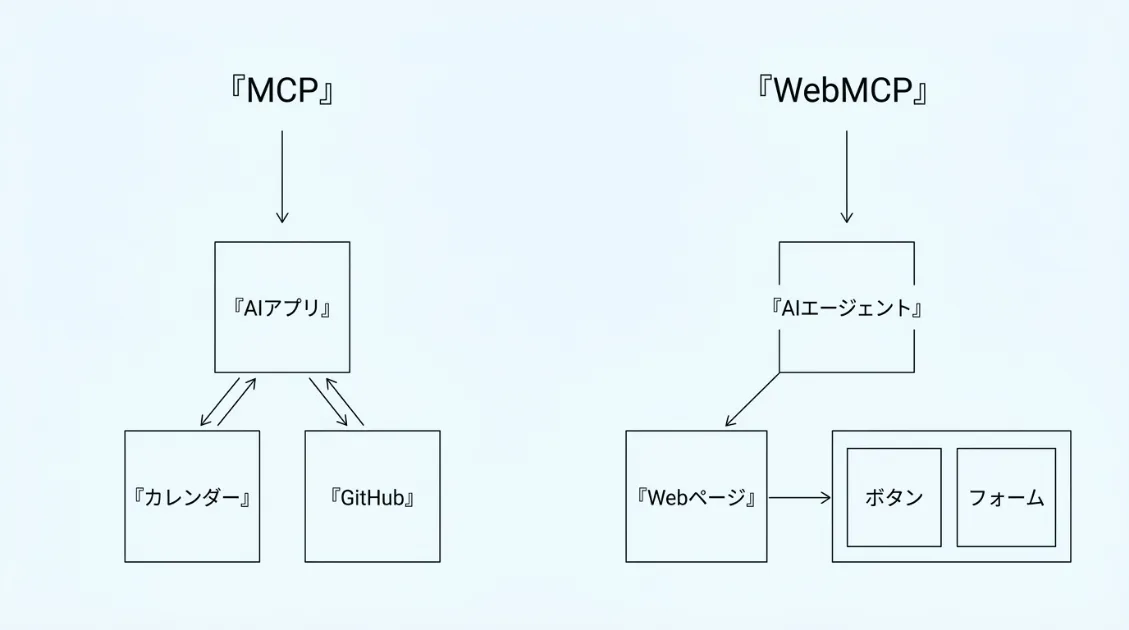
MCP(Model Context Protocol)は、AIと外部アプリケーションをつなぐための仕組みです。たとえば、AIがカレンダーの予定を確認したり、GitHubのコードを読んだり、社内データベースから情報を取得したりするときに使われます。ブラウザ画面を操作するというより、裏側のシステムやデータに接続するイメージです。
一方WebMCPは、ブラウザで開いているWebサイトを、AIエージェントが操作しやすくするための仕組みです。対象は裏側のシステムではなく、人間が普段見ているWebページそのものです。
簡潔にまとめると、MCPは「裏側のシステムとつながる技術」、WebMCPは「表に見えているWebページを操作する技術」と考えるとわかりやすいです。
WebMCPはMCPの上位互換や後継ではありません。用途が違う技術であり、今後はMCPとWebMCPが組み合わさって使われる場面も出てくると考えられます。
従来の操作方法はなぜ不安定なのか——WebMCPが解決する課題
WebMCPが登場した背景を理解するために、これまでAIエージェントがサイトをどのように操作してきたのかを確認します。
1つ目は「画面をそのまま画像として読む」方法です。AIがブラウザの画面をスクリーンショットとして認識し、「ここにボタンがある」「このテキストボックスに入力する」と判断して操作します。人間が目で見て操作するのと近い方法ですが、デザインが変わるたびに判断がずれるという問題があります。
2つ目は「HTMLの構造を直接読む」方法です。HTMLとはWebページの骨格にあたるコードで、見出し・段落・ボタンといった要素が記述されています。AIはそのコードを解析して操作対象を特定しますが、複雑なページでは目的の要素を見つけるのに手間がかかります。
どちらの方法も、サイト側が「ここで検索できます」「ここで予約できます」と、操作できる機能を明示しているわけではありません。AIが画面やコードを手がかりに自力で判断しているため、ミスが起きやすく、処理も不安定になりやすいのです。
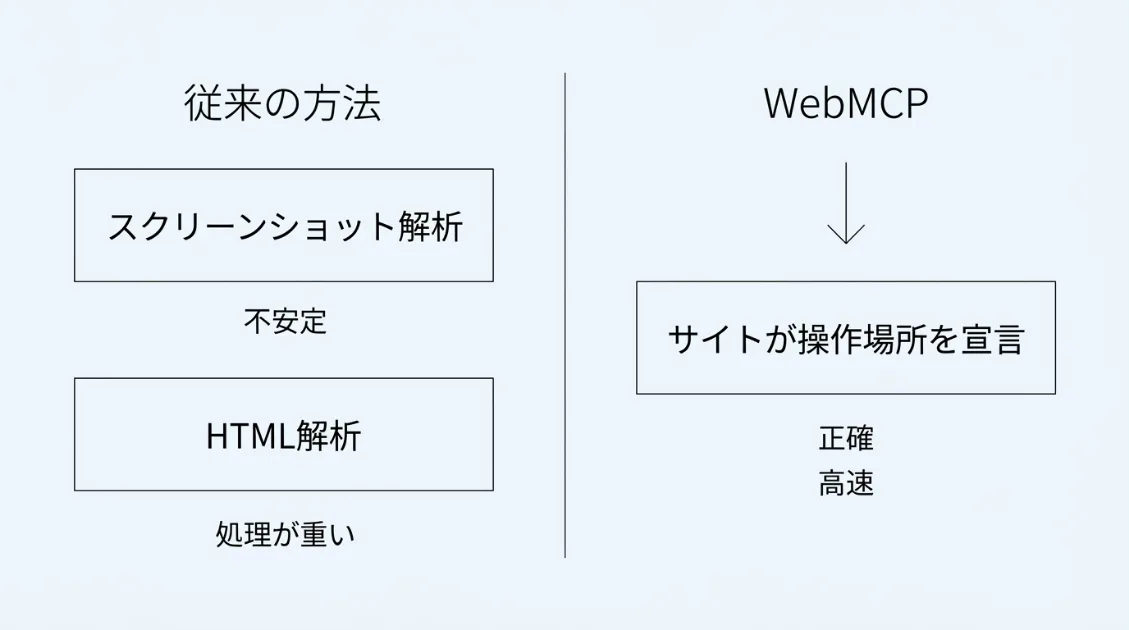
WebMCPは、この課題を解決するアプローチです。サイト側が「検索はここ」「予約はここ」と操作できる機能をあらかじめ伝えておくことで、AIエージェントが画面を手探りで読むのではなく、サイト側が用意した情報をもとに操作できるようになります。
今どこまで進んでいるか——Chrome 149での実験と参加企業の現状
WebMCPは、2026年2月に早期プレビューとして公開されました。最初はChromeの設定画面からフラグを手動で有効にする必要がある、開発者向けの試験段階でした。
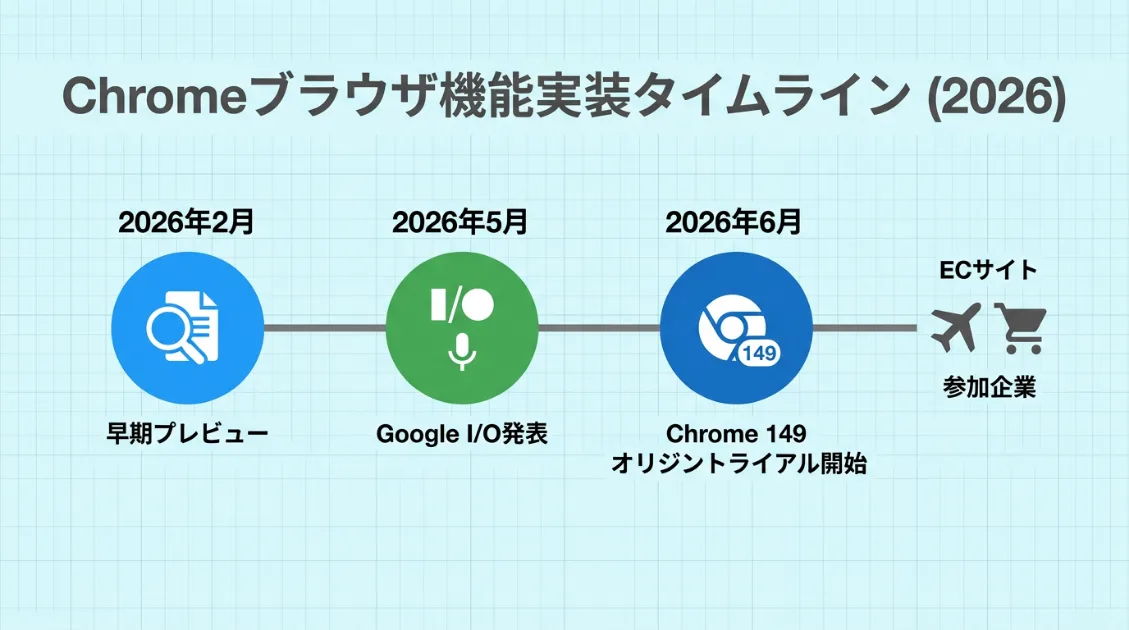
2026年5月のGoogle I/O 2026では、WebMCPが「エージェントが使えるWeb」という文脈で取り上げられました。同時に、Chrome 149でオリジントライアルを開始する方針も示されています。オリジントライアルとは、実験的な機能を本番に近いWebサイトで試せるようにする、期間限定の仕組みです。
2026年6月には、Chrome 149向けにWebMCPのオリジントライアルが案内されました。サイト運営者は専用のトークンを発行し、ページに設置することで、対応ブラウザ上でWebMCPを試せるようになります。フラグを手動で有効にして検証する段階から、実際のサイト上でフィードバックを集める段階へ進んだと見てよさそうです。
実験に関わる企業名も見えてきました。Google I/O 2026のChrome関連発表では、Expedia、Booking.com、Shopify、Credit Karma、TurboTax、Redfin、Etsy、Instacart、Targetといったブランドが、WebMCPを試している企業として紹介されています。旅行予約、EC、金融、不動産、配送など、フォーム入力・検索・予約・購入手続きのような「人が繰り返し行う操作」が多い領域に集中している点が特徴です。
標準化の面でも動きがあります。WebMCPはChromeだけの独自機能として閉じるのではなく、W3C Web Machine Learning Community Groupの場で仕様の議論が進められています。将来的に複数のブラウザやAIエージェントが対応する可能性はありますが、現時点ではまだ提案・実験段階の技術と見ておくのが安全です。
一方で、一般のサイト運営者が今すぐ対応を迫られている状況ではありません。公式には、Gemini in ChromeがWebMCP APIをサポート予定とされていますが、ChatGPT、Claude、Perplexityなどの主要AIアシスタントが、本番環境でWebMCPを広く利用している段階ではまだありません。
つまりはWebMCPは、すでに大手企業が実験を始めている一方で、一般サイトに広く普及した段階ではありません。今は「実装するかどうか」を急ぐよりも、どのようなサイト操作がAIエージェントに置き換わりそうかを観測するフェーズだと考えています。
サイト運営者が今準備しておきたいこと——ログ・HTML・robots.txtの観点から
WebMCPはまだ実験段階です。Chrome 149ではオリジントライアルとして提供されており、開発者が実際のサイトで検証できる段階に進んでいます。 とはいえ、一般のサイト運営者が今すぐ実装を迫られている状況ではありません。
しかし、Expedia、Booking.com、Shopify、Targetといった大手サービスが実験に参加している以上、「まったく関係ない」と見てしまうのも勿体ない話。今の段階では、WebMCPを実装するより先に、AIエージェント時代に向けた基本の土台を確認しておくのが現実的です。
① robots.txtの方針を決めておく
WebMCPそのものはrobots.txtで制御する仕組みではありません。ですが、AIクローラーやAIエージェントに対して、自サイトの情報取得をどこまで許可するのか、方針を決めておくことは重要です。
AIクローラー向けの設定がまだ済んでいないサイトは、まずrobots.txtの基本設定から確認しておくとよいでしょう。
→ AIクローラーの許可・拒否設定【robots.txt実例付き】
② セマンティックHTMLを整備する
AIエージェントがサイトを正確に理解するには、HTMLの構造が整っていることが土台になります。divタグだらけのHTMLより、header・main・article・button・formといった意味のある要素が使われている方が、ページ上の役割を判断しやすくなります。
WebMCPに直接対応する前でも、セマンティックHTMLの整備はAIエージェント対応の下地になります。検索フォーム、予約導線、商品ページ、問い合わせフォームなど、ユーザーの操作が発生する箇所から見直すのがおすすめです。
→ AIはdivが読めない——セマンティックHTMLがAI引用の土台になる理由
③ サーバーログを定期的に確認する習慣をつける
WebMCP自体は、サイト側がJavaScriptで構造化ツールを公開する仕組みです。そのため、WebMCPという名前が訪問者のUser-Agentにそのまま現れるとは限りません。この点、GPTBotやClaudeBotのようにUser-Agentで判定しやすいAIクローラーとは性質が異なります。
ただ、対応ブラウザからのアクセス、AIエージェント経由と思われる操作、フォーム送信や検索実行の変化などは、サーバーログやイベントログから観測できる可能性があります。GA4だけではAIエージェント由来の操作を見落とす可能性があるため、サーバーログを見る習慣は、WebMCPに限らず重要です。
→ GA4だけではAI流入は計測できない——サーバーログで補完する方法
④ 様子見でいいのか、温度感をアップデートする
WebMCPは、まだ一般サイトが急いで実装する段階ではありません。Chrome 149のオリジントライアルが始まり、大手企業による実験も進んでいます。Google I/O 2026のChrome発表でも、複数の大手ブランドがWebMCPを試している事例として紹介されています。
なので、今は「実装するかどうか」を決める段階というより、AIエージェントに置き換わりやすい操作が自サイトにあるかを確認する段階です。検索、予約、見積もり、カート追加、問い合わせなど、人間が繰り返し行う操作があるサイトほど、今後の影響を受けやすくなる可能性があります。
まずは、自分のサイトにどのようなAIクローラーやAI関連アクセスが来ているのかを把握しておくことが出発点になります。WordPressサイトであれば、AI観測ラボの無料プラグインでも、AIクローラーのUser-Agentやアクセス傾向を確認できます。
→ AI観測ラボ Tracker|WordPress公式プラグイン
まとめ
WebMCPは、AIエージェントがWebサイトを操作するための新しい仕組みです。2026年2月に早期プレビューとして公開され、2026年5月のGoogle I/O 2026では「エージェントが使えるWeb」の文脈で大きく取り上げられました。その後、Chrome 149ではオリジントライアルとして、実際のサイトで検証できる段階へ進んでいます。
Expedia、Booking.com、Shopify、Targetといった大手企業も、WebMCPを試している事例として紹介されています。一方、一般サイトに広く普及している段階ではありません。Gemini in Chromeでの対応が予定されているものの、ChatGPTやPerplexity、Claudeなどの主要AIアシスタントが本番環境でWebMCPを広く利用している状況は、まだ確認されていません。
今すぐ実装に動く必要はありませんが、robots.txtの方針を決めること、セマンティックHTMLを整えること、サーバーログを定期的に確認する習慣をつけることは、WebMCPに限らずAI対応全般に役立ちます。波が本格的に来る前に、土台だけ整えておくのが、今できる現実的な準備です。
AI観測ラボでは、今後もChrome 149オリジントライアルの広がりや、サーバーログから読み取れる間接的な指標を継続して確認していきます。動きがあり次第、続報として記事にする予定です。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。


