DuckAssistBotとは?DuckDuckGoのAI回答クローラーが実際に読んでいたページを調べてみた

2026年5月28日、AI観測ラボのサーバーログに見慣れない名前が現れました。
「DuckAssistBot」。
DuckDuckGoが運営するAI回答用のクローラーです。
来訪は5月28日と6月1日の2日間だけでした。しかし取得していたページが少し興味深いものでした。
読んでいたのはAmazonbotやBytespiderといった、他のクローラーを解説した記事です。
DuckAssistBotは公式に「AI学習には使用しない」と説明されているクローラーです。では何のためにサイトへ来るのでしょうか。
今回は実際のサーバーログをもとに、DuckAssistBotの役割と動きを調べてみます。
この記事でわかること|📖:約5分
- DuckAssistBotがどんな目的で動いているクローラーなのか
- AI学習に使われないのにサイトへ来る理由
- AI観測ラボで実際に観測されたアクセスログと取得ページ
- robots.txtで制御すべきかどうかの判断基準
DuckAssistBotとは
DuckAssistBotは、検索エンジンDuckDuckGoが運営するAI回答生成のためのクローラーです。
DuckDuckGoには「DuckAssist」というAI回答機能があります。ユーザーが検索したとき、検索結果の上部に短い回答を表示する機能です。DuckAssistBotは、その回答を作るためにリアルタイムでWebページを取得します。
公式ページには次のように記載されています。
DuckDuckGo SearchのWebクローラーで、AI支援による回答のためにページをリアルタイムでクロールして情報を取得します。このデータはAIモデルの訓練に使われることはありません。
(出典:DuckDuckGo公式ヘルプページ)
重要なポイントは次の2つです。
- ユーザーの検索に応じてリアルタイムでページを取得する
- 取得したデータはAIモデルの学習には利用しない
DuckAssistBotは、GPTBotやClaudeBotのような「AI学習用クローラー」ではありません。
AIが回答を作るために、その場で必要な情報を取得する「リアルタイムフェッチャー」に近い役割を持っています。
OpenAIのChatGPT-Userとよく似た性格を持つクローラーと考えることができます。
💡 ChatGPT-Userの動きについてはこちらの記事で詳しく解説しています。
なぜAI学習しないのにサイトへ来るのか
「AI学習に使わないなら、なぜクロールするのか」と思う方は多いと思います。
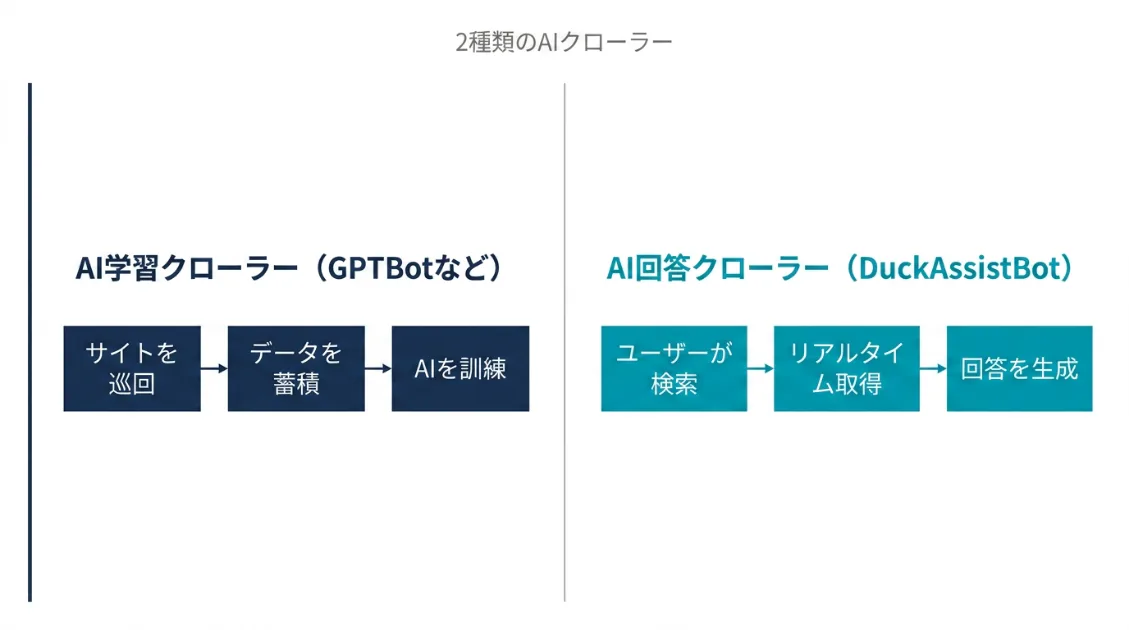
理由はシンプルです。AIクローラーには、目的がまったく異なる2種類が存在するからです。
AI学習のためのクロール
GPTBotやClaudeBotなどは、AIを訓練するためにコンテンツを事前に収集します。サイトに来るのはユーザーの検索とは無関係で、定期的に自動巡回します。収集したデータはAIモデルの学習に利用されます。
AI回答のためのクロール
DuckAssistBotは動き方が異なります。DuckDuckGoのユーザーが何かを検索したとき、その質問に答えるためにリアルタイムでページを取得しに来ます。取得したデータはその場の回答生成に利用され、AIモデルの学習には使用されません。
つまりDuckAssistBotのアクセスは、DuckDuckGo上で関連する検索や回答生成が発生したタイミングと関係している可能性があります。
| 目的 | 代表的なクローラー | 取得タイミング | 学習利用 |
|---|---|---|---|
| AI学習 | GPTBot・ClaudeBot など | 定期的に自動巡回 | あり |
| AI回答生成 | DuckAssistBot・ChatGPT-User | ユーザーの検索に応じてその場で取得 | なし |
前者はAIを育てるためのクロール、後者はユーザーの質問に答えるためのクロールです。
DuckAssistBotは後者に分類されるため、「AI学習されるのでは?」と心配するタイプのクローラーとは性格が大きく異なります。
AI観測ラボで実際に観測されたDuckAssistBot
AI観測ラボのサーバーログで、DuckAssistBotが確認できたのは2日間でした。
観測の概要
| 項目 | 内容 |
|---|---|
| 観測日 | 2026年5月28日・6月1日 |
| IPの所在 | Azure(Microsoft) |
| 取得の動き | HTMLだけでなくJavaScriptまで取得 |
| アクセスしたページ | /amazonbot/・/bytespider-crawler-guide/ |
読んでいたのは「他のクローラーの解説記事」だった
DuckAssistBotがアクセスしたのは、AmazonbotとBytespiderというAIクローラーを解説した記事でした。
DuckAssistBotはAI回答生成のためにリアルタイムでページを取得するクローラーです。そのため、DuckDuckGo上で関連する検索や回答生成が発生したタイミングでアクセスした可能性があります。
少なくとも今回の観測では、「AIクローラーを解説する記事」が優先的に取得されていました。
AI観測ラボが「クローラーを調べるときに参照されるサイト」として機能し始めている、と解釈することもできそうです。
IPがAzureだったことの意味
今回観測したDuckAssistBotのアクセス元IPは、Microsoft Azureに属していました。
DuckAssistBotがAzure上のインフラを利用している可能性があることが確認できました。
なお公式ページでは、DuckAssistBotのIPアドレス一覧をJSONファイルで公開しています。
(参照:duckduckgo.com/duckassistbot.json)
JavaScriptまで取得していた
一般的なクローラーはHTMLだけを取得します。今回の観測では、DuckAssistBotがJavaScriptファイルまで取得している動きが確認できました。
JavaScriptファイルまで取得していたことから、HTMLのみを収集するシンプルなクローラーとは異なる動きをしていることが分かります。
実際にレンダリングを行っているかは今回のログだけでは断定できませんが、Applebotのようなレンダリング寄りの設計を採用している可能性も考えられます。
💡 Applebotのレンダリング動作についてはこちらの記事で詳しく解説しています。
ChatGPT-Userと比較してみる
DuckAssistBotと似た動きをするクローラーに、OpenAIのChatGPT-Userがあります。どちらも「ユーザーの操作をきっかけにリアルタイムでページを取得する」点が共通しています。
| 項目 | DuckAssistBot | ChatGPT-User |
|---|---|---|
| 運営 | DuckDuckGo | OpenAI |
| 目的 | AI回答生成 | ユーザーリクエストへの応答 |
| 取得タイミング | ユーザーが検索したとき | ユーザーがURLを貼ったとき |
| AI学習への利用 | なし | なし |
| リアルタイム取得 | ○ | ○ |
| インフラ | Azure(Microsoft) | OpenAI管理インフラ |
大きな違いはトリガーです。ChatGPT-UserはユーザーがChatGPTにURLを直接貼ったときにアクセスします。一方、DuckAssistBotはDuckDuckGo上で発生した検索や回答生成に関連してページを取得します。
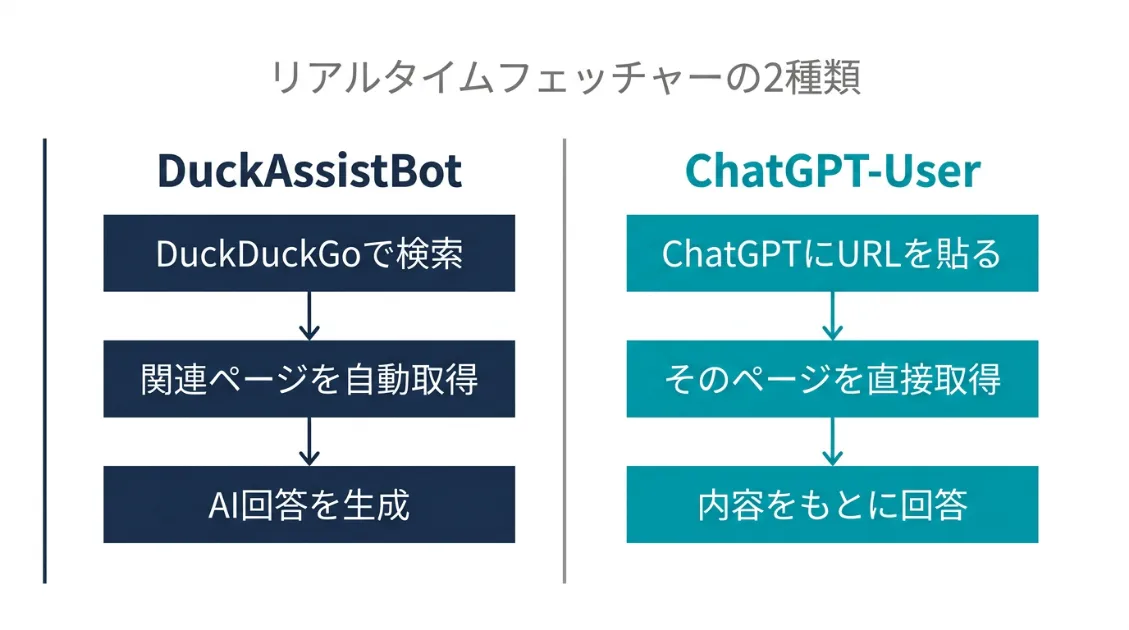
つまりは両者ともリアルタイムフェッチャーですが、ChatGPT-Userは「URL起点」、DuckAssistBotは「検索起点」で動くクローラーと考えると分かりやすいでしょう。
robots.txtで制御できるのか
DuckAssistBotはrobots.txtのDisallowを尊重します。公式によると、拒否設定を行った場合は72時間以内にクロールを停止するとされています。
制御するときの記述方法
# DuckAssistBotを拒否する場合
User-agent: DuckAssistBot
Disallow: /
# DuckAssistBotを許可する場合(デフォルト)
User-agent: DuckAssistBot
Allow: /拒否すべきかどうかの判断基準
DuckAssistBotを拒否するかどうかは、サイトの方針によって変わります。以下を参考にしてください。
| 状況 | 判断 | 理由 |
|---|---|---|
| 一般公開のブログ・メディア | 許可でよい | AI回答で参照される機会が増える可能性がある |
| 有料会員向けコンテンツ | 拒否を検討 | 会員限定コンテンツをAI回答の参照対象にしたくない場合がある |
| ECサイト・商品ページ | 許可でよい | 商品情報がAI回答で参照される可能性がある |
重要なのは、DuckAssistBotを拒否してもDuckDuckGoの通常検索順位には影響しないと公式が説明している点です。
この設定は検索結果への掲載を制御するものではなく、AI回答生成のためのアクセスを制御するための設定と考えると分かりやすいでしょう。
プライバシーを尊重することで有名なDuckDuckGoならではの設定ですよね、クローラーの挙動も然り。
また、DuckDuckGoは問い合わせ窓口として crawling@duckgo.com を公開しています。
💡 AIクローラーのrobots.txt設定全般についてはこちらの記事でまとめています。
まとめ
DuckAssistBotについて整理します。
| 項目 | 内容 |
|---|---|
| 運営 | DuckDuckGo |
| 目的 | AI回答生成のためのリアルタイム取得 |
| AI学習への利用 | なし(公式明記) |
| 取得タイミング | ユーザーの検索や回答生成に関連して発生 |
| インフラ | Azure(Microsoft)を利用している可能性 |
| robots.txt | 尊重する・拒否後72時間以内に停止 |
DuckAssistBotは「AI学習クローラー」ではなく、「AI回答クローラー」に近い存在です。
GPTBotやClaudeBotがAIを育てるためにコンテンツを収集するのに対し、DuckAssistBotは回答生成のために必要なページをリアルタイムで取得します。両者は目的が大きく異なります。
AI観測ラボの実測では、DuckAssistBotはAmazonbotやBytespiderといったクローラー解説記事を取得していました。
なので、DuckDuckGo上で関連する検索や回答生成が発生したタイミングでアクセスした可能性があります。
今後DuckAssistBotを観測した際は、「AI学習のための巡回」ではなく、「リアルタイムの回答生成に関連するアクセスかもしれない」という視点でログを見てみると面白いでしょう。
📌 関連記事
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。


