AIボットは2種類じゃなかった—サーバーログで見えた3つの役割

「AIクローラー」と聞いて、学習用と検索用の2種類を思い浮かべる人は多い。実際、多くの解説記事はその2分類で止まっています。
しかしサーバーログを実際に掘ると、そのどちらにも当てはまらない役割が存在しました。ユーザーが質問したタイミングで、その場で必要なページだけを取りに来る「人間由来フェッチ」と呼ぶべき動きです。
blog.ai-kansoku.comのサーバーログ(2026年4月14日〜21日)をもとに、GPTBot・ClaudeBot・OAI-SearchBot・ChatGPT-Userなど7種類のボットを3つの役割に分類し、実測データを比較しました。
この記事でわかること|📖:約6分
- AIボットは「学習用・検索用・人間由来フェッチ」の3つの役割に分かれる
- 各User-Agentごとのアクセス件数と挙動の違い
- 時間帯データから見える「自律巡回」と「人間トリガー」の動きの違い
- どのAIボットに対応すべきかという実務判断の基準
AIボットの「2種類」という認識は正しいか
「AIクローラーには学習用と検索用の2種類がある」——この説明は、多くのSEO記事やAI最適化の解説でよく見かけます。間違いではありません。ただ、実際のサーバーログを見ると、その2分類では説明できないアクセスが存在します。
たとえば、深夜ではなく昼間に、特定のページへ1〜3件だけピンポイントでアクセスしてくるボットです。広く巡回するわけでもなく、インデックスを作るようなまとまった取得でもありません。この動きは「学習用」と「検索用」のどちらにも当てはまりません。
サーバーログにはそのヒントが残っています。User-Agentを見ると「ChatGPT-User」「Claude-User」「Perplexity-User」という文字列が確認できます。これらはChatGPTやClaudeを使っている人間が質問を投げたタイミングで、AIが必要なページを取りに来た痕跡です。
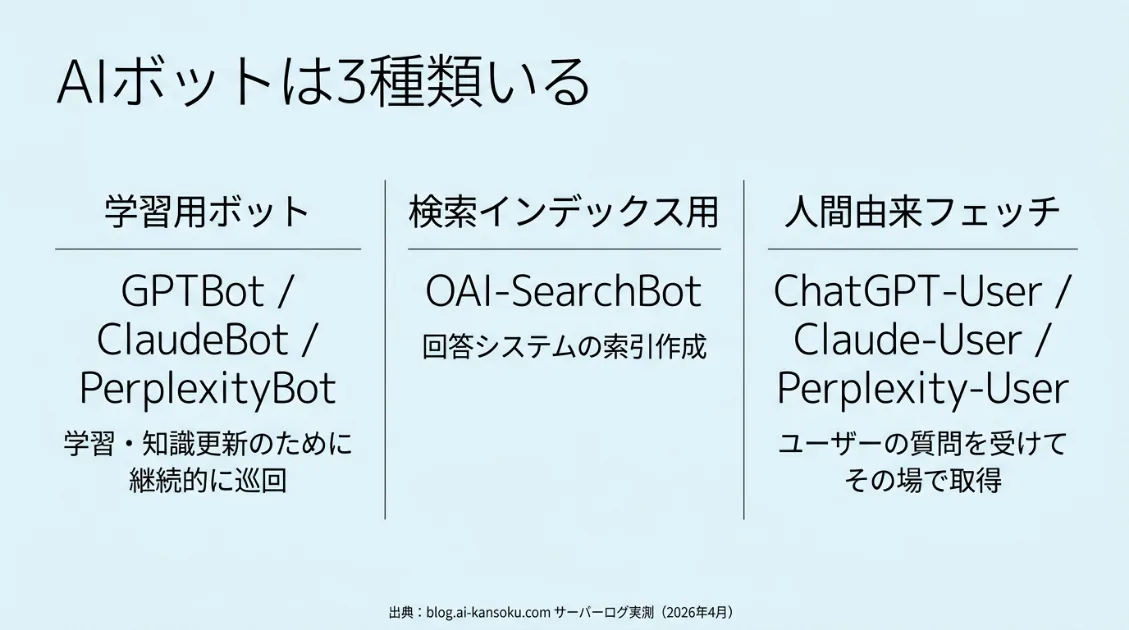
つまりAIボットは、「学習用」と「検索用」だけでは説明できません。サーバーログの実測データから見ると、少なくとも3つの役割に分かれています。
3種類の実測データ—サーバーログで確認した件数と時間帯
blog.ai-kansoku.comのサーバーログ(2026年4月14日〜21日)から、7種類のボットを3つの役割に整理しました。
① 学習用ボット
GPTBot・ClaudeBot・PerplexityBotなど、モデルの学習・知識更新を目的に巡回するボットです。観測期間中の件数はGPTBotが692件、ClaudeBotが234件、PerplexityBotが290件でした。
時間帯の分布を見ると、GPTBotは06時に112件のピークがあり、日中も分散して動いています。ClaudeBotは17〜19時に集中する夕方型、PerplexityBotは15〜20時に約80%が集中しています。3つともピークはバラバラで、人間の活動時間とは連動していません。
② 検索インデックス用ボット
OAI-SearchBotなど、検索・回答システムに載せるための索引を作成するボットです。観測期間中は102件のアクセスを記録しました。
時間帯は深夜〜早朝に集中しており、00時に33件、04時に20件、06時に17件を確認しています。アクセス先はタグページや個別記事に分散しており、広く浅くインデックスを拾う動きが特徴です。
③ 人間由来フェッチ
ChatGPT-User・Claude-User・Perplexity-Userなど、ユーザーの質問を受けてその場で必要なページを取得するボットです。観測期間中の件数はChatGPT-Userが233件、Claude-Userが21件、Perplexity-Userが23件でした。
時間帯を見ると、11時に50件、14〜16時に80件超と、昼〜夕方に集中しています。学習用ボットが自律的に巡回しているのに対し、このボットは人間の活動時間と明確に連動しています。
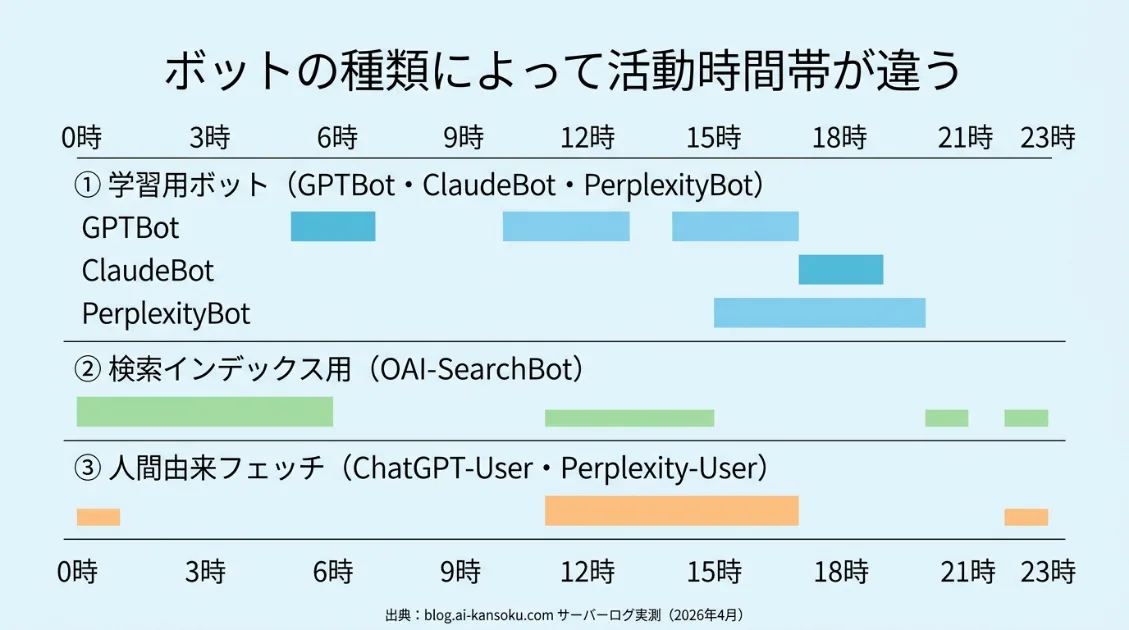
このように、AIボットは同じ「クローラー」でも、役割によって動き方がまったく異なります。
3種類は何が違うのか—動き方を比較する
件数や時間帯だけでなく、アクセスの「動き方」にも明確な差があります。サーバーログから読み取れた3種類の違いを整理します。

学習用ボットは「広く・継続的」に動く
GPTBotのアクセス先を見ると、記事ページ・タグページ・トップページと幅広く巡回しています。1日に複数回、同じページに戻ってくる動きも確認できます。robots.txtを確認してから本文に入るケースが多く、サイト全体を横断的に取得しています。
ClaudeBotはllms.txtを読んでから記事へ進む動きが観測されており、サイト側の案内に沿ってアクセスしています。PerplexityBotは15〜20時の特定時間帯に集中して大量アクセスする点が特徴的です。
検索インデックス用ボットは「広く・一度ずつ」動く
OAI-SearchBotのアクセス先はタグページや個別記事が1件ずつ散らばっており、深夜に集中しています。同じページに繰り返しアクセスすることはほとんどなく、インデックスに必要なURLを一通り取得する動きです。
人間由来フェッチは「ピンポイント」に動く
ChatGPT-Userのアクセス先を見ると、トップページが78件でダントツ1位、次いで/ai-crawler-pattern-comparison/が35件、/structured-data-guide/が30件と、特定のページに集中しています。サイト全体を巡回するのではなく、ユーザーの質問に関連するページだけを取得しています。
時間帯も昼〜夕方に集中しており、人間がAIを使うタイミングと一致しています。深夜にほとんどアクセスがない点は、学習用ボットとは対照的です。
このように、学習用は「広く・繰り返し」、検索用は「広く・一度ずつ」、人間由来フェッチは「狭く・ピンポイント」と、動き方が明確に分かれています。
サイト運営者として3種類のどれに対応すべきか
3種類のボットが存在するとわかったとして、サイト運営者は何を優先すべきでしょうか。結論から言うと、「短期・中期・長期」で対応が分かれます。
人間由来フェッチは今この瞬間の回答に使われます。検索インデックス用ボットは数日〜数週間後の引用に影響します。学習用ボットは長期的なモデルの知識として蓄積されます。
この時間軸を踏まえると、どこに何を優先すべきかが見えてきます。
AIに学習してもらいたいなら—学習用ボット対応(長期)
GPTBot・ClaudeBot・PerplexityBotに正しく巡回してもらうためには、robots.txtでブロックしていないことを確認するのが最初のステップです。次にsitemap.xmlを整備して、サイト全体の構造をボットに伝えます。
ClaudeBotはllms.txtを読んでから記事へ進む動きが観測されています。llms.txtを設置しておくと、サイトの案内として機能する可能性があります。
→ robots.txtでAIクローラーを制御する
→ llms.txtの書き方
AI検索に引用されたいなら—検索インデックス用ボット対応(中期)
OAI-SearchBotはタグページや個別記事を広く浅く収集します。各記事のタイトル・メタディスクリプション・構造化データを整備することで、インデックスに載りやすくなります。
→ JSON-LDとは?AIに読まれる構造化データの実装方法
人間由来フェッチに対応するなら—即時応答できるページ設計(短期)
ChatGPT-UserやClaude-Userはユーザーの質問を受けてその場で取りに来ます。ページの読み込み速度が遅いと、取得に失敗する可能性があります。また、質問に対して明確に答えている記事ほど取得対象になりやすい傾向があります。
→ AI時代のページ速度の現実
→ セマンティックHTMLがAI引用の土台になる理由
このように、AI対応は1つではありません。どのボットに向けた対策かによって、やるべきことと効果が出るタイミングが変わります。
まとめ—AIボットの3種類を把握することが対策の出発点になる
サーバーログを実測した結果、AIボットは「学習用・検索インデックス用・人間由来フェッチ」の3種類に分類できることがわかりました。
学習用ボット(GPTBot・ClaudeBot・PerplexityBot)は自律的に広範囲を巡回し、時間帯は各社でバラバラです。検索インデックス用ボット(OAI-SearchBot)は深夜に集中して広く浅く動きます。人間由来フェッチ(ChatGPT-User・Claude-User・Perplexity-User)は昼〜夕方、人間がAIを使う時間帯と連動してピンポイントで動きます。
「AIクローラーは学習用と検索用の2種類」という認識は、人間由来フェッチの存在を見落としています。ユーザーがChatGPTに質問するたびにサイトへのアクセスが発生しているという構造は、サーバーログを見なければ気づきにくいものです。
3種類のボットそれぞれに対して何をすべきかは、目的によって変わります。まず自分のサイトにどの種類のボットが来ているかを把握することが、AI時代の対策の出発点になります。
AIは「学習するもの」だけではありません。ユーザーの質問に応じて、その場でサイトを読みに来る存在でもあります。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。