Amazonbotとは—Alexaを支える3種類のクローラーと実測ログで見えた行動

サーバーログを確認すると、「Amazonbot」という名前のクローラーが記録されていることがあります。
検索すると「AlexaのためのAmazonのクローラーです」という説明で終わっている記事がほとんどです。ただ、Amazon公式ドキュメントを読むと、Amazonbotは1種類ではありません。目的ごとに役割が異なる3種類のクローラーが存在します。
AI観測ラボのサーバーログでは、Amazonbotがrobots.txtを読まずに記事ページへ直接アクセスしてきた記録や、WordPressのREST API(wp-json)を繰り返し叩いていた記録が残っています。「Alexa向けのクローラー」という一言だけでは説明できない行動です。
この記事では、Amazon公式情報とAI観測ラボの実測ログをもとに、Amazonbotの正体と3種類の違い、そしてrobots.txtでの制御方法まで整理して解説します。
この記事でわかること|📖:約5分
- Amazonbotは「Amazonbot」「Amzn-SearchBot」「Amzn-User」の3種類に分かれており、それぞれ役割が異なること
- AI観測ラボの実測ログで確認できた、robots.txtを読まずに記事ページへ直接アクセスした挙動とREST API取得の記録
- Alexa向けの巡回と、Amazon Rufus向け検索クローラーでは利用目的が異なること
- robots.txtで3種類のクローラーを個別に制御する設定方法
Amazonbotとは
AmazonbotはAmazonが運営するWebクローラーです。Webサイトを自動で巡回してページの内容を取得し、Amazonの製品・サービス改善やAI関連システムの精度向上などに利用されています。
User-Agentには以下の文字列が含まれます。サーバーログで確認するときの目印になります。
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot) Chrome/119.0.6045.214 Safari/537.36IPアドレスの確認は、Amazon公式が公開しているIPレンジ情報と照合する方法が確実です。
ただし、ここで多くの解説記事が見落としているポイントがあります。
実は、「Amazonbot」という名前で語られているクローラーは1種類ではありません。Amazon公式ドキュメントでは、役割が異なる3種類のクローラーが案内されています。
Amazonbotは1種類ではありません
Amazon公式ドキュメントを確認すると、Amazon関連のクローラーには目的ごとに3種類のUser-Agentが存在します。サーバーログに「Amazonbot」と記録されていても、実際には役割が大きく異なる場合があります。
| クローラー名 | 主な目的 | AIモデル学習 | 対象サービス |
|---|---|---|---|
| Amazonbot | 製品・サービス改善/AI関連システム | あり | Amazon全般 |
| Amzn-SearchBot | 検索体験の向上 | なし | Alexa・Rufus |
| Amzn-User | ユーザーアクションのサポート | 記載なし | Alexa(リアルタイム取得) |
特に重要なのは、「Amazonbot」と「Amzn-SearchBot」の違いです。
Amazonbotは、コンテンツ取得を通じてAmazonの製品・サービス改善やAI関連システムに利用されます。一方、Amzn-SearchBotはAlexaやAmazonのAIショッピングアシスタント「Rufus」の検索体験向上を目的としており、生成AIモデルの学習には利用しないと公式に記載されています。
つまり、「AI学習には使われたくないが、AlexaやRufusの検索結果には表示されたい」という場合、robots.txtで制御すべき対象が変わります。
Amazon関連クローラーを一括でブロックすると、将来的にAlexaやRufus経由での可視性へ影響する可能性があります。
それぞれのUser-Agent文字列は以下のとおりです。
// Amazonbot(AI関連システム向け)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot) Chrome/119.0.6045.214 Safari/537.36
// Amzn-SearchBot(Alexa / Rufus向け)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amzn-SearchBot/0.1) Chrome/119.0.6045.214 Safari/537.36
// Amzn-User(ユーザーアクション用)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amzn-User/0.1) Chrome/119.0.6045.214 Safari/537.36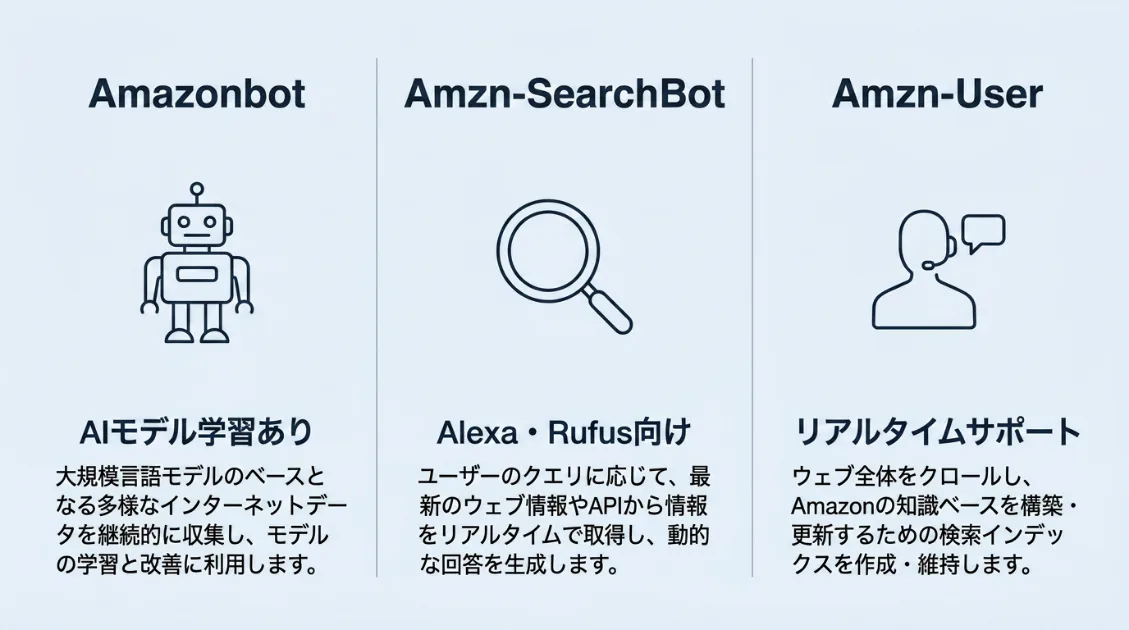
AI観測ラボの実測ログで見えた行動
公式ドキュメントだけではわからない、実際の巡回パターンをサーバーログで確認しました。AI観測ラボ(blog.ai-kansoku.com)の2026年5月11日〜18日の7日間のログから、Amazonbotの特徴的な行動を紹介します。
特徴1:タグページを優先して巡回していた
観測期間中のAmazonbotのアクセス総数は167件でした。アクセス先の内訳を見ると、タグページへの集中が際立っています。
| アクセス先の種別 | 件数 | 割合 |
|---|---|---|
| タグページ(/tag/〇〇/) | 88件 | 53% |
| 記事ページ | 33件 | 20% |
| 月別アーカイブ | 12件 | 7% |
| 著者ページ | 6件 | 4% |
| その他(リダイレクト・404等) | 28件 | 16% |
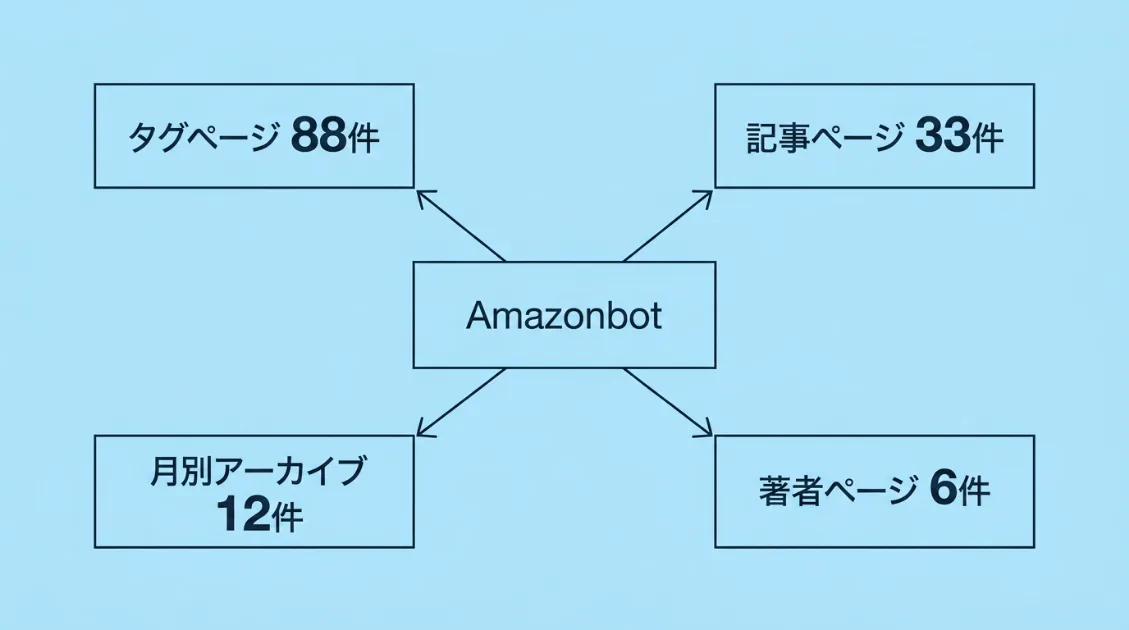
記事本文より先にタグページを巡回しており、サイト構造や関連テーマを把握しようとしている可能性があります。
実際にアクセスしていたタグは「llms-txt」「applebot」「claudebot」「rufus」「agentic-commerce」など、AI・クローラー関連キーワードへ集中していました。
特徴2:著者ページをpage/7〜page/11まで連続取得していた
著者ページ(/author/admin/)に対して、複数のページネーションを連続取得する行動も記録されました。
3.89.176.255 [13/May/2026] GET /author/admin/ 200
54.89.90.224 [13/May/2026] GET /author/admin/page/11/ 200
18.204.152.114 [15/May/2026] GET /author/admin/page/10/ 200
34.196.114.170 [16/May/2026] GET /author/admin/page/9/ 200
34.231.156.59 [17/May/2026] GET /author/admin/page/8/ 200
23.23.213.182 [17/May/2026] GET /author/admin/page/7/ 200著者ページは記事一覧としても機能するため、サイト全体の投稿量や更新頻度を把握しようとしている可能性があります。
運営者情報ページへのアクセスはBingbotでも確認されており、AIクローラーがサイト信頼性の確認に利用している可能性があります。
特徴3:robots.txtを今回も確認しなかった
7日間167件のアクセス中、robots.txtへのアクセスは確認できませんでした。2026年3月の観測時も同様に0件でした。
| クローラー | robots.txt確認 | 記事・ページへのアクセス |
|---|---|---|
| ClaudeBot | あり | あり |
| GPTBot | あり | あり |
| PerplexityBot | あり | あり |
| Amazonbot | 0件(2回の観測期間とも) | あり |
ただ、Amazon公式ドキュメントには「robots.txtを尊重する」と明記されています。
そのため、過去30日以内のキャッシュを参照している可能性や、観測期間外で取得していた可能性も考えられます。現時点では「robots.txtアクセスを確認できなかった」という実測事実として継続観察しています。
特徴4:REST APIへのアクセスは今回確認されなかった
2026年3月の観測では、WordPressのREST API(/wp-json/wp/v2/)を繰り返し取得する行動が記録されていました。
一方、今回の7日間ではwp-jsonへのアクセスは0件でした。REST API取得は常時発生する挙動ではなく、特定条件やタイミングで発生している可能性があります。
3月に確認されたREST API取得の詳細については、
「AmazonbotがREST APIを叩いていた—サーバーログで見えた新事実【AI実験室 #05】」
で詳しく整理しています。
robots.txtでの制御方法
Amazon関連クローラーは3種類存在するため、目的に応じて制御対象を分けることが重要です。
「とりあえず全部ブロック」にしてしまうと、AlexaやRufus経由での可視性へ影響する可能性があります。
パターン1:AI関連システム向け取得だけ止めたい
AmazonbotによるAI関連システム向け取得を制限しつつ、AlexaやRufus向け検索には引き続き対応したい場合の設定です。
User-agent: Amazonbot
Disallow: /パターン2:Amazon関連クローラーをすべて止めたい
AmazonbotとAmzn-SearchBotの両方をブロックする設定です。AlexaやRufus関連の取得にも影響する可能性があります。
User-agent: Amazonbot
Disallow: /
User-agent: Amzn-SearchBot
Disallow: /パターン3:特定ディレクトリのみ制限したい
会員ページや管理画面など、特定パスのみクロールを制限したい場合の設定です。
User-agent: Amazonbot
Disallow: /members/
Disallow: /wp-admin/robots.txt変更後は、実際にサーバーログでアクセス状況を継続確認することをおすすめします。
AIクローラー全体のrobots.txt設計については、以下の記事でも詳しく整理しています。
robots.txt完全ガイド|AIクローラー制御—実測ログで見えた設計の正解
まとめ
最後にAmazonbotについて、公式情報とAI観測ラボの実測ログから見えたポイントを整理していきましょう。
- Amazon関連クローラーには「Amazonbot」「Amzn-SearchBot」「Amzn-User」の3種類が存在し、それぞれ役割が異なる
- Amazonbotは製品・サービス改善やAI関連システム向け、Amazno-SearchBotはAlexa・Rufus向け検索体験の改善を目的としている
- AI観測ラボの実測では、観測期間中にrobots.txtアクセスを確認できないまま記事ページへ直接アクセスしていた
- WordPressのREST API(wp-json)を繰り返し取得しており、HTMLではなくJSONデータを直接取得しようとしていた可能性がある
- robots.txtで制御する際は、目的に応じてクローラー名を個別に使い分ける必要がある
「Amazonbotをブロックする」という判断をする前に、AlexaやRufus経由での可視性を維持したいかどうかを確認したうえで設定することをおすすめします。
AmazonbotによるREST API取得の詳細な挙動については、
「AmazonbotがREST APIを叩いていた—サーバーログで見えた新事実【AI実験室 #05】」
でも詳しく解説しています。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。