Metaの新AIクローラーがサイトに来ていた—実測データで正体を暴く

サーバーログに、見慣れないUser-Agentが記録されていました。
meta-externalagent/1.1 (+https://developers.facebook.com/docs/sharing/webmasters/crawler)
FacebookやInstagramを運営するMeta社のクローラーです。ただし、リンクのプレビューを生成する旧来のクローラーとは別物です。AIの学習データを収集するために、2024年7月に静かにリリースされた新しいクローラーです。
調査してみると、このクローラーが2026年2月時点でGPTBotを抜いてAIクローラーシェア世界第2位に急浮上していたことがわかりました。にもかかわらず、日本語で実態を解説した記事はほとんど存在しません。
AI観測ラボのサーバーログにも117件の訪問記録がありました。このクローラーが何をしているのか、実測データをもとに正体を明らかにします。
この記事でわかること|📖:約8分
- Meta-ExternalAgentがどんな目的で作られたクローラーなのか
- facebookexternalhitやMeta-WebIndexerとの違い
- AI観測ラボのサーバーログで観測した実測データ(117件)の詳細
- robots.txtでブロックすべきか・許可すべきかの判断基準
Meta-ExternalAgentとは何か
Meta-ExternalAgentは、Meta社(FacebookやInstagramの親会社)が2024年7月にリリースしたAI学習専用のクローラーです。公式の説明によると、用途は「AIモデルのトレーニング、またはコンテンツを直接インデックスすることによる製品の改善」とされています。
わかりやすく言うと、ChatGPTを支えるGPTBotと同じ役割です。MetaのLlamaモデルや、WhatsApp・Instagram・Facebook上で動くMeta AIアシスタントを賢くするために、Web上の公開コンテンツを収集しています。
登場した背景には、Metaの学習データ不足があります。マーク・ザッカーバーグ氏は以前の決算説明会で「自社のSNSデータはCommon Crawlを超える規模だ」と発言していました。それでもFortuneの報道によると、Llamaの継続的な改善のためには外部Webのクロールが必要になったとされています。
リリース当初は公式発表もなく、ひっそりと開発者向けドキュメントにUser-Agent情報が追加されただけでした。多くのサイト運営者がその存在に気づかないまま、クロールされ続けていたわけです。
User-Agent文字列はこちらです。
meta-externalagent/1.1 (+https://developers.facebook.com/docs/sharing/webmasters/crawler)サーバーログでこの文字列を見かけたら、MetaのAI学習クローラーが訪問しています。
facebookexternalhitと何が違うのか
「Meta社のクローラーならサイトに来たことがある」と思った方もいるかもしれません。ただそれは別のクローラーである可能性が高いです。Meta社のクローラーは目的ごとに3種類あり、それぞれ役割がまったく異なります。
| クローラー名 | 用途 | AI学習との関係 |
|---|---|---|
| meta-externalagent | LlamaモデルのAI学習データ収集 | あり(メイン) |
| meta-webindexer | Meta AI検索での引用・インデックス | あり(引用用) |
| facebookexternalhit | FacebookへのリンクシェアのOGPプレビュー生成 | なし |
AI観測ラボのサーバーログでも今回の調査で3種類すべてを確認しました。facebookexternalhitは直近のログに3件あり、これはどこかのページがFacebook上でシェアされたときに発生したプレビュー取得のアクセスです。AI学習とは無関係です。
一方でmeta-externalagentは過去ログに117件、meta-webindexerは0件という結果でした。Meta AIの検索引用専用クローラーはまだ来ておりません。
robots.txtでブロックしたい場合、3つは別々のUser-Agent名で指定する必要があります。「facebookexternalhitをブロックしていたからMeta対策は済んでいる」は誤りで、AI学習用のmeta-externalagentは別途設定が必要です。
なぜ今Meta-ExternalAgentが重要なのか
Meta-ExternalAgentの存在を知らないサイト運営者は多いです。しかし規模で見ると、すでにGPTBotを大きく超えています。
セキュリティ企業Fastlyが2025年9月に発表した「2025年第2四半期の脅威インサイトレポート」によると、2025年4月中旬から7月中旬に観測されたAIクローラートラフィック全体のうち、52%がMeta社によるものでした。Google(23%)とOpenAI(20%)を合わせた数値を上回っています。
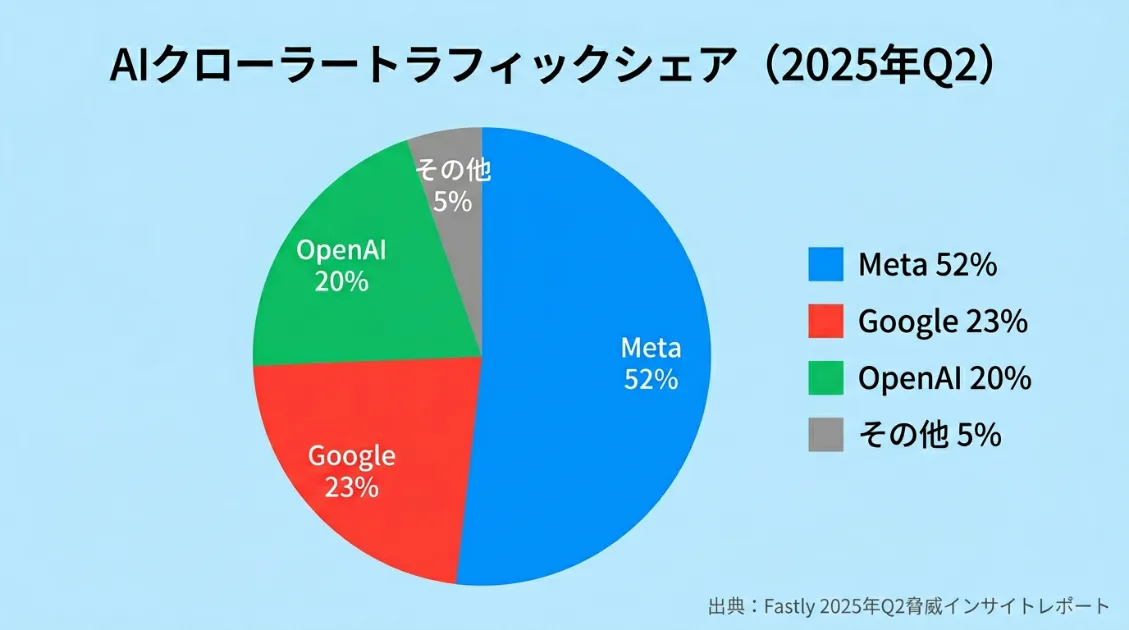
さらに2026年2月のCloudflareデータでは、Meta-ExternalAgentがGPTBotを抜いてAIクローラーシェア世界第2位(15.6%)に急浮上したことが確認されています。GPTBot(12.1%)、ClaudeBot(11.1%)と続き、上位4クローラーだけでAIボットトラフィックの73.5%を占めています。
ところがブロック率はわずか3.26%です。GPTBotのブロック率が5.45%、ClaudeBotが4.62%であることと比べると、Meta-ExternalAgentへの対策は圧倒的に遅れています。存在自体が知られていないことが最大の理由です。
AIクローラーの許可・拒否設定の基本についてはAIクローラーの許可・拒否設定【robots.txt実例付き】で詳しく解説しています。
AI観測ラボのサーバーログで実測した
Meta-ExternalAgentがAI観測ラボ(blog.ai-kansoku.com)に実際に訪問した記録を、サーバーログから抽出しました。観測期間は2026年3月19日から3月24日です。
訪問件数は117件、3月20日に集中
実際のサーバーログにはこのように記録されていました。
| 日付 | 訪問件数 |
|---|---|
| 2026年3月19日 | 22件 |
| 2026年3月20日 | 71件 |
| 2026年3月21日 | 11件 |
| 2026年3月22日 | 12件 |
| 2026年3月24日 | 1件 |
| 合計 | 117件 |
3月19日に初めて訪問し、翌3月20日に71件と爆発的に増加しました。3月18日から20日はゼロクリック3部作を連続公開したタイミングと一致します。新記事の公開がクロールのトリガーになった可能性があります。
複数のIPから同時にクロールする並列処理
サーバーログを見ると、同じ時間帯に異なるIPアドレスから同時にアクセスしていることがわかりました。
57.141.16.0 [19/Mar/2026:11:36:06] /ai-site-settings-checklist/
57.141.16.17 [19/Mar/2026:11:36:06] /tag/ダークトラフィック/
57.141.16.30 [19/Mar/2026:11:36:23] /robots-txt-ai-crawler/
57.141.16.51 [19/Mar/2026:11:36:23] /meta-tag-ai-crawler/
57.141.16.34 [19/Mar/2026:11:36:28] /zero-click-search-guide/同じ11時36分台に、57.141.16.xという同一レンジの異なるIPが複数の記事ページを同時に取得しています。並列クロールによってサイト全体を短時間で収集する設計になっています。
記事だけでなくタグ・※wp-json・画像まで取得
訪問先のURLを分類すると、記事本文だけでなくサイト構造全体を収集していることがわかりました。
※wp-jsonはWordPressが標準で持つREST APIのエンドポイントです。記事本文だけでなく、タグIDや投稿IDなどのメタデータをJSON形式で取得できるため、構造化されたデータを効率よく収集できます。
| 取得対象 | 例 |
|---|---|
| 記事ページ | /ai-crawler-timing-analysis/(4回)、/structured-data-guide/ など |
| タグページ | /tag/robots-txt/、/tag/サーバーログ/ など |
| WordPress REST API | /wp-json/wp/v2/tags/81、/wp-json/wp/v2/posts/585 など |
| 画像ファイル | /wp-content/uploads/2026/02/ai-visibility-score-research-02_hero-768×428.webp など |
| その他 | /xmlrpc.php、/glossary/ など |
特に注目したいのが2点あります。
1点目はwp-jsonへのアクセスです。WordPressのREST APIを直接叩いて、タグや投稿のメタデータを構造化された形で取得しています。AmazonbotがREST APIを叩いていた事例と同じ動きです。詳しくはAmazonbotがREST APIを叩いていた——サーバーログで見えた新事実【AI実験室 #05】で解説しています。
2点目は画像ファイルの取得です。「AIクローラーはHTMLしか読まない」という認識が一般的ですが、Meta-ExternalAgentは画像ファイル(.webp)まで取得していました。画像のaltテキストやファイル名も収集対象になっている可能性があります。
最多訪問ページは/ai-crawler-timing-analysis/
記事ページの中で最も多く訪問されたのはAIクローラーは何時にクロールする?——ChatGPT・Claude・Googlebotの時間帯を実測比較で、4回のアクセスがありました。AIクローラーそのものを解説した専門性の高いページが優先的に収集されたと考えられます。
robots.txtでブロックすべきか、許可すべきか
Meta-ExternalAgentの存在を知ったとき、多くのサイト運営者が「ブロックすべきか、許可すべきか」と迷います。答えはサイトの目的によって変わります。
ブロックを検討したほうがいいケース
独自の調査データや有料コンテンツ、オリジナルのクリエイティブ作品など、競合に真似されたくない一次情報を持つサイトは、ブロックを検討する価値があります。Meta-ExternalAgentはAI学習専用クローラーなので、収集したコンテンツはLlamaモデルの学習データになります。自社コンテンツがAI学習に使われることを避けたい場合はブロックが有効です。
許可したほうがいいケース
ブランドや商品・サービスの認知拡大を目的とするサイトは、許可したほうがメリットがあります。Meta-ExternalAgentを許可することで、WhatsApp・Instagram・Facebook上のMeta AIアシスタントが自社の情報を正確に把握しやすくなります。
Meta AIは世界で数十億人が使うプラットフォーム上で動いています。Meta AIに正しく認識されることは、ブランドの露出につながる可能性があります。
robots.txtの設定例
完全にブロックする場合はこちらです。
# Meta AIクローラーをブロック
User-agent: meta-externalagent
Disallow: /
# Meta AI検索インデックスもブロック
User-agent: meta-webindexer
Disallow: /特定のディレクトリだけ許可する場合はこちらです。
# 記事ページは許可、管理系は拒否
User-agent: meta-externalagent
Disallow: /wp-json/
Disallow: /wp-admin/
Disallow: /tag/
Allow: /注意点が1つあります。robots.txtはあくまで任意のルールであり、法的拘束力はありません。
一部のサイト運営者からはMeta-ExternalAgentがrobots.txtを無視してクロールを続けたという報告もあります。確実にブロックしたい場合は、サーバー側でUser-Agentを見てアクセスを拒否する設定も合わせて検討してください。
AIクローラー全般のrobots.txt設定についてはAIクローラーの許可・拒否設定【robots.txt実例付き】で詳しく解説しています。
まとめ
Meta-ExternalAgentについて、実測データをもとに整理しました。
- 2024年7月にMetaが公式発表なしでリリースしたAI学習専用クローラー
- LlamaモデルやMeta AIの学習データ収集が目的で、facebookexternalhitとは別物
- 2025年Q2時点でAIクローラートラフィックの52%をMetaが占め、Google・OpenAIを上回る
- 2026年2月にGPTBotを抜いてAIクローラーシェア世界第2位(15.6%)に急浮上
- AI観測ラボには3月19日に初訪問、翌20日に71件と爆発的に増加、合計117件を記録
- 並列クロールで短時間にサイト全体を収集、wp-json・タグ・画像ファイルまで取得
- ブロック率はわずか3.26%で、存在自体が知られていないのが現状
「Facebookのクローラーは知っている」というサイト運営者でも、Meta-ExternalAgentの存在は見落としているケースがほとんどです。AIクローラーへの対応を検討する際は、GPTBotやClaudeBotと並んでMeta-ExternalAgentも忘れずに確認してください。
AIクローラー全体の種類とシェアについてはAIクローラーの種類と最新シェアを比べてみた——GPTBot急増・ClaudeBot減少の実態と設定方法で詳しく解説しています。
自分のサーバーログに Meta-ExternalAgent が来ているか確認したい場合は、SSHでサーバーにアクセスして以下のコマンドを試してみてください。
grep -i "meta-externalagent" /path/to/access_logサーバーログの確認方法についてはGA4に出ないAI流入はこう拾う——サーバーログで可視化する見えないトラフィックの正体で詳しく解説しています。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。


