Baiduspiderって何してるの?—292件のログで見えた通常版とrender版の動き

サーバーログに「Baiduspider」や「Baiduspider-render」という名前が並んでいると、不正アクセスなのか、ブロックすべきなのか、気になります。日本語で調べると、「Baiduspiderは行儀が悪い」「大量クロールで迷惑」といった古い情報も目立ちます。
では、2026年現在のBaiduspiderは実際にどう動いているのか。AI観測ラボのサーバーログには、通常版82件、render版210件、合計292件のBaiduspiderによるアクセスが記録されていました。
少なくとも今回のログでは、暴走型には見えませんでした。通常版がURLやタグページを取得し、render版が画像やJavaScriptを回収する、2段構成の整理された巡回として見えました。
292件の実測データをもとに、Baiduspiderの役割と動き方を整理します。
この記事でわかること|📖:約8分
- Baiduspiderが2026年の実測ログでどう動いていたのか
- 通常版82件とrender版210件から見えた2段構成の役割分担
- 記事ページだけでなく、タグページも巡回対象になっていた記録
- Baiduspiderが本物かどうかの確認方法とrobots.txtでの制御方法
BaiduspiderはBaiduの検索クローラー
Baiduspider(バイドゥスパイダー)は、中国の検索エンジン「Baidu(百度)」が使っているクローラーです。クローラーとは、インターネット上のWebサイトを自動的に巡回し、ページの内容を収集するプログラムのことです。Googleで言えばGooglebotに近い存在で、Baiduspiderが集めた情報はBaiduの検索結果に使われます。
Baidu公式の説明では、BaiduspiderはWebページを巡回してインデックスを作成し、Baidu検索結果に反映するための自動収集プログラムとされています。役割はGooglebotに近いですが、主にBaidu検索のインデックス作成を目的としている点が異なります。
「行儀が悪い」と言われた過去
Baiduspiderには、「大量にアクセスしてくる迷惑なクローラー」というイメージが長く残っています。実際、2007年3月にはBaidu日本法人が公式にお詫びを出しています。当時のBaiduspiderは非常に短い間隔でリクエストを繰り返し、サーバーに大きな負荷をかけていました。
Baidu側はお詫びと同時に、クロール頻度の制御、Crawl-delay(巡回間隔の指定)への対応、重複URLの削減などの改善策を発表しています。約20年前の出来事ですが、日本語で「Baiduspider」と検索すると、今でもこの時期の情報が多く見つかります。
では、2026年現在のBaiduspiderはまだ暴走型なのか。AI観測ラボのサーバーログでは、合計292件のアクセスが記録されていました。次のセクションで、通常版とrender版の2種類に分かれて動いていた実際の様子を見ていきます。
通常版とrender版の2段構成—実測ログで見えた役割分担
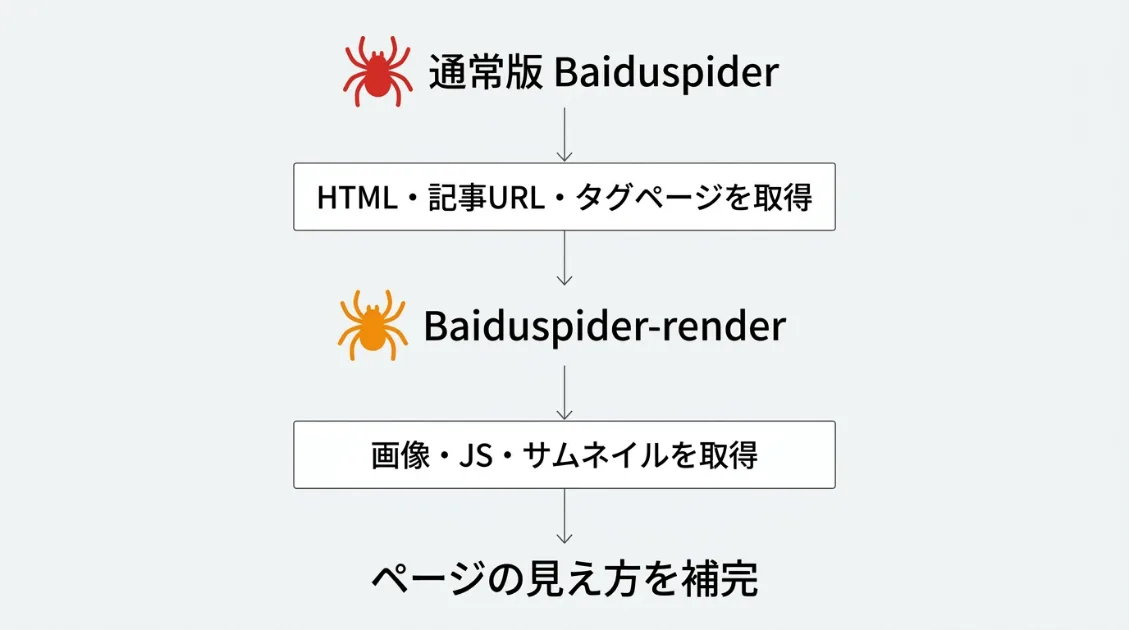
AI観測ラボのサーバーログを見ると、Baiduspiderには2種類のUser-Agentが確認できました。「Baiduspider/2.0」と「Baiduspider-render/2.0」です。名前は似ていますが、ログ上では取得している対象が分かれていました。
通常版のBaiduspiderは、記事ページやタグページなど、サイト内のURLを取得していました。一方、render版のBaiduspider-renderは、画像ファイルやJavaScript、サムネイル画像など、ページを画面に表示するために必要なリソースを回収していました。
実測の件数で比べると、以下のようになっていました。
| 種類 | User-Agent | アクセス件数 | 主な取得対象 |
|---|---|---|---|
| 通常版 | Baiduspider/2.0 | 82件 | 記事ページ・タグページなどのURL |
| render版 | Baiduspider-render/2.0 | 210件 | 画像・JavaScript・サムネイルなどの描画リソース |
render版の方が件数が多いのは、1つのページを表示するために画像やJSファイルなど複数のリソースが必要になるためだと考えられます。通常版が「どのページがあるか」を見に来て、render版が「そのページはどう見えるか」を補完しに来ている。今回のログでは、2段階の動きとして確認できました。
Googlebotのレンダリング処理に近い考え方で理解するとわかりやすいです。Googleも、クロールしたページをレンダリングキューに入れ、必要に応じてJavaScriptなどを処理してページの内容を確認します。Baiduspiderの通常版とrender版も、今回のログではGppgleに近い2段階の動きとして見えました。
Cloudflare Radarでも、Baiduspiderは検証済みボットとして掲載されており、User-Agent例に Baiduspider-render/2.0 が確認できます。少なくとも、Baiduspider-render という名前だけで不正なクローラーと判断する必要はありません。
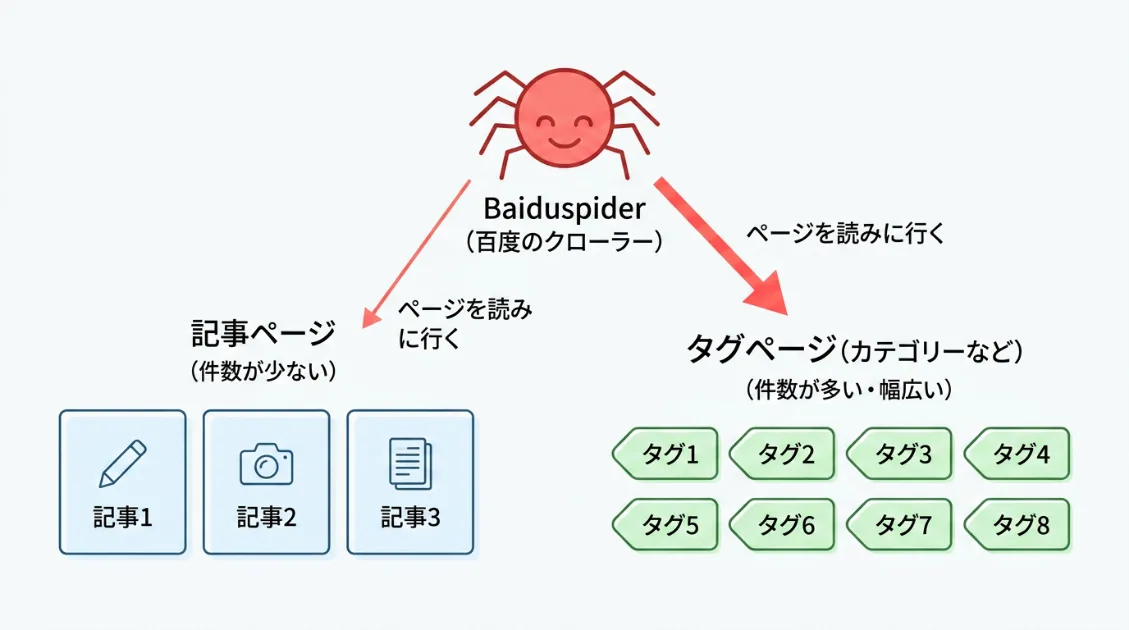
Baiduspiderは記事だけでなくタグページも見ていた
通常版Baiduspiderがどのページにアクセスしていたかを確認すると、興味深い傾向がありました。記事ページだけでなく、タグページへのアクセスが目立っていました。
実測ログに記録されていたアクセス先の一部を紹介します。
| ページの種類 | アクセス先の例 |
|---|---|
| 記事ページ | /wwdc26/(3件)、/chatgpt-referenced/(2件) |
| タグページ | /tag/x/、/tag/wwdc/、/tag/siri/、/tag/meta/、/tag/markdown/、/tag/google/ など多数 |
記事ページでは同じURLに複数回アクセスしていた一方で、タグページは1件ずつでも複数のタグに広く分散していました。特定の記事だけを深く見るというより、サイト内にどんなテーマの記事があるのかを広く確認しているように見えます。
タグページには、同じタグがついた記事のタイトル・抜粋・日付がまとめて表示されています。1回のアクセスで複数記事の手がかりをまとめて取得できるため、サイト全体のテーマを効率よく把握する入口として使われている可能性があります。
一方、render版のBaiduspider-renderが取得していたのは、記事やタグページの本文ではなく、ページの表示に必要なリソースでした。
| 取得対象 | 具体例 |
|---|---|
| テーマのJavaScript | GeneratePressのmenu.min.js(4件) |
| サムネイル画像 | 各記事の768×429サイズのwebp画像 |
| 運営者アイコン | ailab_tomishima.webp(2件) |
今回確認できたrender版のアクセスは、記事本文そのものというより、ページ表示に必要なリソースが中心でした。サムネイル画像だけでなく、運営者のアイコン画像まで取得していた点は、サイトの見た目や運営者情報もレンダリング対象に含めているように見えます。
AIクローラーがタグページを巡回する動きは、PerplexityBotでも確認されています。詳しくはAIは記事だけを読んでいなかった—27秒・10URLで見えた「広く→狭く」の読み方で整理しています。
時間帯とIPアドレスから見えた動き方
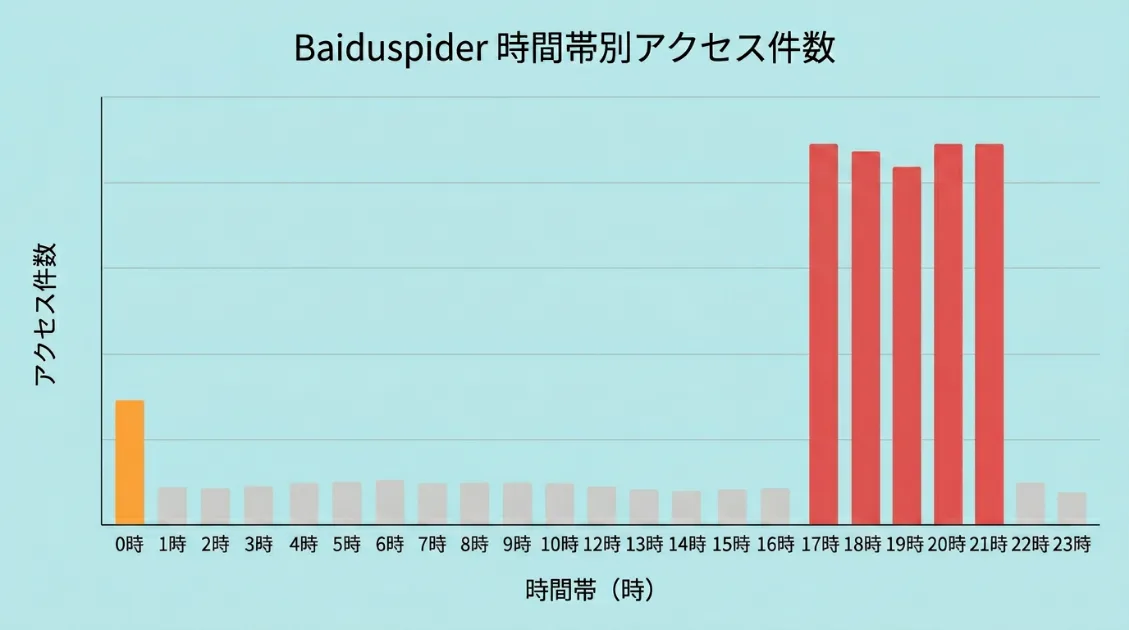
Baiduspiderがいつ来ているのかを時間帯別に集計すると、アクセスが集中する時間帯が見えてきました。
| 時間帯(日本時間) | 件数 | 備考 |
|---|---|---|
| 0時台 | 36件 | 日付が変わるタイミングでまとまったアクセス |
| 1〜3時台 | 3件 | ほぼ停止 |
| 4〜9時台 | 67件 | 朝の時間帯にも一定数のアクセス |
| 10〜13時台 | 11件 | 昼間は少なめ |
| 14〜16時台 | 16件 | 午後も少なめ |
| 17〜22時台 | 159件 | 夕方から夜にかけて最も集中 |
| 23時台 | 4件 | 深夜前に減少 |
全292件のうち、日本時間の17〜22時台だけで159件、全体の約54%を占めています。中国標準時に換算すると16〜21時にあたります。Baiduspiderの運用スケジュールを断定することはできませんが、今回のログでは夕方から夜にかけてまとまって動く傾向が見えました。
0時台の36件も特徴的です。日付が切り替わるタイミングでまとまってアクセスが来ており、日次の処理に近い動きにも見えます。ですが、今回のログだけでBaiduspider全体の巡回スケジュールを断定することはできません。
IPアドレスは116.179.32.xに集中していた
Baiduspiderのアクセス元IPアドレスを確認したところ、今回のログではすべて116.179.32.xのレンジに集中していました。ipinfo.ioで確認すると、Baidu系のASNに紐づくIPアドレスでした。
Baidu公式は、Baiduspiderをrobots.txtで制御する方法を案内しており、Baiduspiderだけをブロックする例も掲載しています。また、過去の日本法人のお詫びページでも、Baiduspiderのクロール頻度制御やCrawl-delay対応などの改善策が説明されています。
今回のログに記録されていたIPは、User-AgentだけでなくIPアドレスの面でもBaidu由来と見てよさそうなアクセスでした。少なくとも、User-Agentを偽装しただけの不審なクローラーとは見えませんでした。
サーバーログに見慣れない名前が出てきたときにIPアドレスで確認する方法については、AIクローラーはIPで判定するな—User-Agentを使うべき理由も参考にしてください。
robots.txtでBaiduspiderを制御する方法
Baiduspiderの正体がわかったところで、最後に「許可するのか、ブロックするのか」を考えます。結論から言うと、サイトの目的によって判断が変わります。
Baiduspiderをブロックしたい場合
中国語圏からの検索流入が不要で、サーバー負荷が気になる場合は、robots.txtでブロックできます。Baidu公式は、Baiduspiderがrobots.txtを遵守しており、Baiduspiderのアクセスを禁止するとBaiduの検索結果に表示されなくなると説明しています。
User-agent: Baiduspider
Disallow: /上記の設定で、Baiduspiderによるサイト全体の巡回を禁止できます。Baidu公式でも、Baiduspider全体のクロールを禁止する設定例として紹介されています。
画像だけブロックしたい場合は、以下のように画像ファイルの拡張子を指定する方法もBaidu公式で紹介されています。
User-agent: Baiduspider
Disallow: /*.jpg$
Disallow: /*.jpeg$
Disallow: /*.gif$
Disallow: /*.png$
Disallow: /*.bmp$AI観測ラボでは画像にwebp形式も使っているため、自サイトの実態に合わせるなら、以下のようにwebpを追加して考えることもできます。
User-agent: Baiduspider
Disallow: /*.webp$Baiduspider-renderもブロックすべきか
render版(Baiduspider-render)は、通常版が取得したURLをもとに、画像やJavaScriptなどの描画リソースを回収しに来ているように見えました。Cloudflare Radarでも、BaiduspiderのUser-Agent例として Baiduspider-render/2.0 が確認できます。
通常版のBaiduspiderをブロックすれば、render版が取得すべきページも減るため、結果的にrender版のアクセスも減る可能性があります。まずは公式に案内されている User-agent: Baiduspider での制御を基本に考えるのが安全です。
どうしてもrender版だけを個別に制御したい場合は、ログ上のUser-Agentに合わせて以下のように指定する方法も考えられます。ただし、Baidu公式がrender版だけの個別制御を明示しているわけではないため、まずは実際のログ変化を確認しながら判断してください。
User-agent: Baiduspider-render
Disallow: /AI観測ラボではブロックしていない
AI観測ラボでは、現時点ではBaiduspiderをブロックしていません。理由は、今回のログで確認した範囲では異常な高頻度アクセスではなく、通常版とrender版に分かれた整理された巡回として動いているように見えたためです。
ただ、中国向けの検索流入が不要で、サーバー負荷が明確に出ている場合は、robots.txtで制御する選択肢があります。ブロックするかどうかは、サイトの目的とサーバーの状況に合わせて判断してください。
robots.txtでのAIクローラー制御全般については、robots.txt完全ガイド|AIクローラー制御—実測ログで見えた設計の正解で詳しく解説しています。
まとめ
AI観測ラボのサーバーログに記録された292件のデータをもとに、Baiduspiderの動き方を整理しました。
- Baiduspiderは中国の検索エンジンBaiduのクローラーで、2007年には大量クロールの問題があったが、今回のログでは暴走型には見えなかった
- 通常版(82件)が記事ページやタグページを取得し、render版(210件)が画像やJavaScriptを回収する2段構成の動きとして確認できた
- 通常版は記事ページだけでなくタグページも幅広く巡回しており、サイト内のテーマ構造を確認している可能性がある
- アクセスは日本時間17〜22時台に集中し、0時台にもまとまったアクセスが見られた
- IPアドレスは116.179.32.xに集中し、Baidu系ASNに紐づくIPとして確認できた
「Baiduspiderは行儀が悪い」という評判は、約20年前の大量クロール問題から残っているものです。少なくとも今回の観測期間中は、通常版とrender版に分かれた整理された巡回として動いているように見えました。
サーバーログにBaiduspiderの名前が出てきたときは、すぐにブロックするのではなく、まずアクセス件数・アクセス先・IPアドレスを確認してから判断するのが現実的です。中国向けの検索流入が不要で、サーバー負荷が明確に出ている場合は、robots.txtで制御できます。
Baiduspiderと同じく中国系クローラーとして知られるBytespiderについてはByteSpiderとは?世界最多リクエストのAIクローラーをログで調べた、AIクローラー全体のタグページ巡回パターンについてはAIは記事だけを読んでいなかった—27秒・10URLで見えた「広く→狭く」の読み方も参考にしてください。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。


