robots.txt完全ガイド【2026年版】156件の実測ログで分かったAIクローラーの正しい制御方法
robots.txtは、サイト運営者がクローラーに対して「ここは見ていい」「ここには来ないでほしい」と伝えるためのファイルです。書き方を調べれば、設置そのものは5分ほどで終わります。
ただし、「書いたから安心」という認識は、実測ログを見ると少し変わってきます。AI観測ラボのサーバーログ156件を調べたところ、robots.txtを確認せずに記事ページへ直接アクセスしたクローラーが確認されました。読み取り件数と来訪件数の比率も、クローラーごとに大きく異なっています。
大切なのは「何を書くか」だけでなく、「どのクローラーがどう動くのか」を理解したうえで設計することです。実測ログを公開しながら、AIクローラー時代のrobots.txt設計を整理します。
この記事でわかること|📖:約8分
- robots.txtの基本的な仕組みと、AIクローラー時代に変わった点
- クローラー別のrobots.txt読み取り頻度と記事ページ来訪数の実測比較
- 「読む・従う・来る頻度」が別問題である理由とクローラー別の特性
- AI観測ラボが実際に使っているrobots.txt設計とコピペ用テンプレート
robots.txtとは何か——クローラーへの「お願い状」
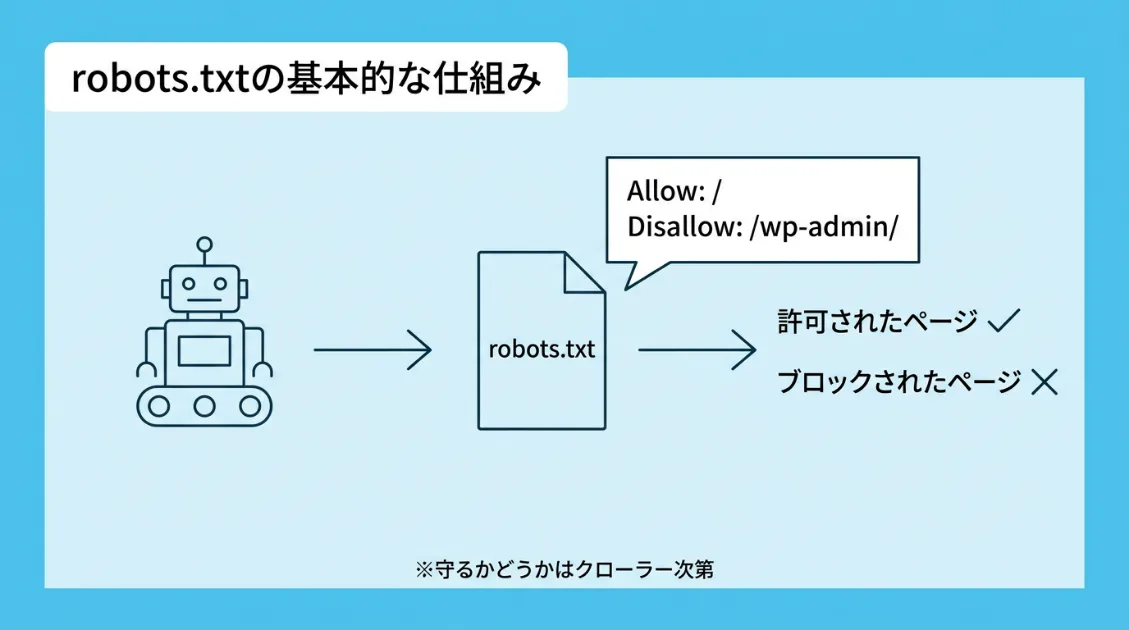
robots.txtは、Webサイトのルートディレクトリに置くテキストファイルです。クローラー(サイトを自動で巡回するプログラム)に対して、「このページは見ていい」「このディレクトリには来ないでほしい」と伝える役割を持ちます。
たとえば、お店の入り口に「関係者以外立入禁止」と書いた紙を貼るイメージに近い存在です。ただし、鍵はかかっていません。紙を読んで守るかどうかは、来た側の判断に委ねられています。
2023年以降、ChatGPTやClaudeといった生成AIの普及によって、robots.txtの役割を見直すサイト運営者が増えました。
従来は主にGooglebotなど検索エンジン向けの設定でしたが、現在はGPTBot・ClaudeBot・PerplexityBotといったAIクローラーへの対応も重要なテーマになっています。robots.txtの歴史的な背景についてはrobots.txt誕生の歴史とAIクローラー時代の現実で詳しく整理しています。
基本的な書き方
robots.txtは以下の3つの命令で構成されます。難しい記法はなく、テキストファイルに数行書くだけです。
- User-agent:どのクローラーへの指示かを指定する。
*はすべてのクローラーを意味する - Disallow:来てほしくないURLやディレクトリを指定する
- Allow:Disallowの例外として、特定のページを許可する
# すべてのクローラーに対してwp-adminへのアクセスを禁止
User-agent: *
Disallow: /wp-admin/
# GPTBotにはサイト全体を許可
User-agent: GPTBot
Allow: /
# ClaudeBotにもサイト全体を許可
User-agent: ClaudeBot
Allow: /
# sitemapの場所を伝える
Sitemap: https://example.com/sitemap_index.xml
robots.txtの詳しい書き方と、AIクローラー別のコピペ設定例はrobots.txtでAIクローラーにどう見せるかにまとめています。
AIクローラーはrobots.txtを本当に読んでいるのか——156件の実測ログ公開
「robots.txtに書けば制御できる」——多くの解説記事はこのように説明するでしょう。しかしAI観測ラボでは、実際のサーバーログを集計して確認しました。対象はblog.ai-kansoku.comのアクセスログです。
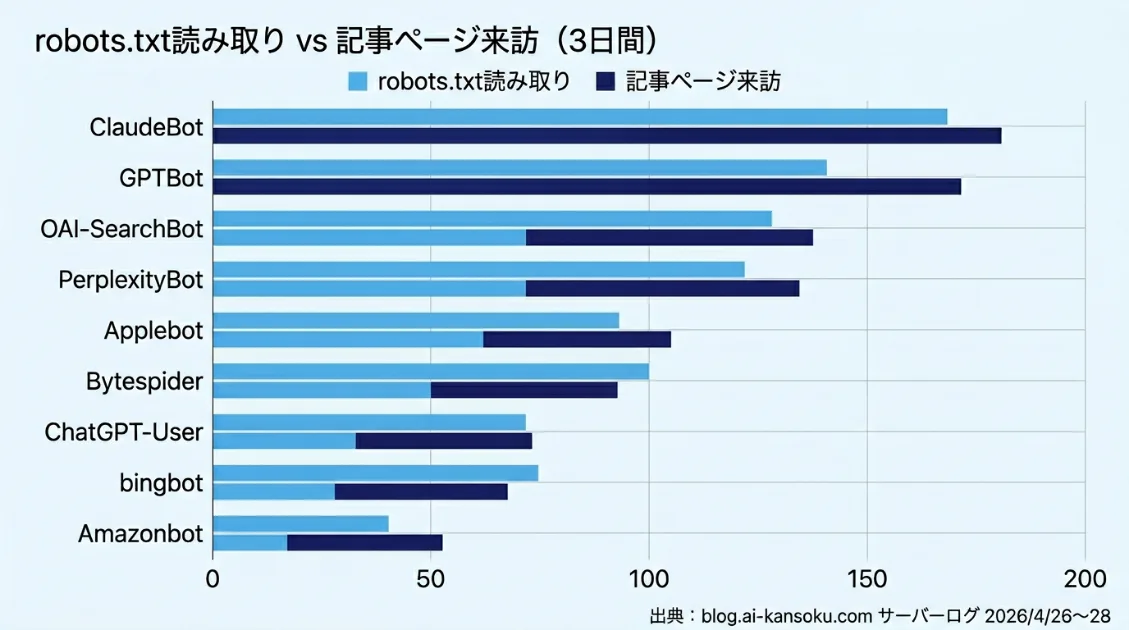
まずrobots.txtへのアクセス数を集計し、次に同じクローラーが記事ページ(静的アセット・管理画面・サイトマップ等を除く)に何件アクセスしたかを比較しました。結果が以下の表です。
| クローラー | robots.txt 読み取り件数 |
記事ページ 来訪件数 |
比率 (記事÷robots.txt) |
観測された特徴 |
|---|---|---|---|---|
| ClaudeBot | 31件 | 51件 | 1.6倍 | robots.txt確認頻度が高い |
| OAI-SearchBot | 11件 | 11件 | 1.0倍 | 読み取り比率が近い |
| GPTBot | 5件 | 58件 | 12倍 | 記事ページ来訪が多い |
| PerplexityBot | 13件 | 134件 | 10倍 | 記事ページ来訪が多い |
| Applebot | 18件 | 29件 | 1.6倍 | 比較的比率が近い |
| Bytespider | 4件 | 8件 | 2倍 | 少量だが来訪あり |
| ChatGPT-User | 6件 | 129件 | 22倍 | 記事ページ来訪が非常に多い |
| bingbot | 4件 | 165件 | 41倍 | robots.txtアクセス比率が低い |
| Amazonbot | 0件 | 21件 | — | 観測期間中はrobots.txtアクセスなし |
OBSERVATION CHECK – あなたのサイトでは?
GA4では見えないAIクローラー、あなたのサイトには来てますか?
この表は、サーバーログを手作業で集計したものです。
AI Kansoku Lab Trackerを使えば、GPTBot / ClaudeBot / PerplexityBotがいつ・どのページに来たかが、WordPress管理画面で自動で見えるようになります。
156件のような数字を、あなたのサイトでも毎朝確認できます。
WordPress管理画面 → プラグイン → 新規追加 → 「Kansoku Lab」で検索
表から見えることを整理します。
ClaudeBotとOAI-SearchBotは、robots.txtを読む頻度と記事ページへの来訪頻度が比較的近い値でした。一方でGPTBot・PerplexityBot・ChatGPT-User・bingbotは、robots.txtを読む回数よりも記事ページへの来訪回数が大幅に多くなっています。
最も注目したいのはAmazonbotです。観測期間中、robots.txtへのアクセスは確認できませんでした。にもかかわらず記事ページには21件のアクセスが記録されています。
Amazonbotが実際にどのページへアクセスしていたかについてはAmazonbotがREST APIを叩いていた——サーバーログで見えた新事実で詳しく解説しています。
ただし、この数字だけで「robots.txtを無視している」と断言することはできません。比率が大きくなる理由として考えられるのは、下記の3点です。
- キャッシュ済み:以前に読んだrobots.txtを保持しており、毎回アクセスしていない
- 設計上の別動線:ChatGPT-Userのように、ユーザー操作を起点とするアクセス経路を持っている
- 参照頻度が低い:robots.txtの確認間隔が長く、観測期間中に現れなかった
AI観測ラボのrobots.txtは全クローラーにAllowを設定しているため、「Disallowを書いても来るか」の検証は今回のデータでは行えていません。「読む頻度」と「来る頻度」がクローラーによって大きく異なることは、実測ログから確認できました。
重要なのは、robots.txtを設置すること自体ではなく「どのクローラーが、どの頻度で、どの入口から来るのか」を観測しながら設計を更新していくことです。
「読む・従う・来る頻度」は全部別問題
robots.txtについて調べると、「書けば制御できる」という説明をよく見かけます。
実測ログを見ると、robots.txtに関わる動作は少なくとも3つの段階に分かれていることがわかります。この3つを混同すると、設計の判断を誤ります。
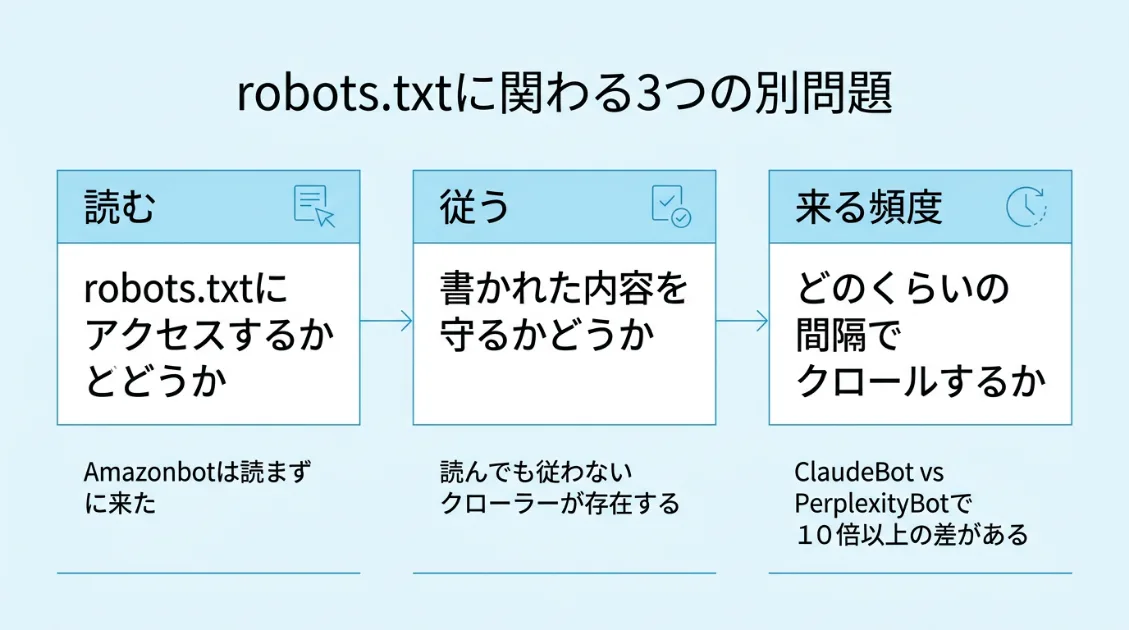
① 読む——robots.txtにアクセスするかどうか
クローラーがサイトに来る前に、まずrobots.txtを確認する——これが理想的な動作です。ただし実測では、観測期間中にrobots.txtへのアクセスを確認できないまま記事ページへ来訪したクローラーも確認されています。
bingbotやChatGPT-Userも、robots.txt読み取り件数に対して記事ページ来訪件数が極端に多い結果でした。bingbotについてはrobots.txtをキャッシュしている可能性があり、ChatGPT-Userについては、都度robots.txtを確認しない動きが実測ログから観測されています。
ChatGPT-Userの動作については誰かがChatGPTにURLを貼った——サーバーログで見えた正体で実測データをまとめています。
② 従う——書かれた内容を守るかどうか
robots.txtを読んだとしても、内容に従うかどうかはクローラー側の判断です。主要なAIクローラーの多くは、公式ドキュメント上でrobots.txtを尊重する方針を示しています。
強制力のあるルールではなく、各社が示している運用方針です。
競合記事の中には「Bytespiderはrobots.txtを無視する」と説明しているものもあります。
実際に無視しているかどうかをサーバーログで検証した一次データはほとんど見当たりません。AI観測ラボのrobots.txtは全クローラーにAllowを設定しているため、「Disallowを書いても来るか」の検証は現時点では行えていません。この点は今後の観測課題です。
またrobots.txtはあくまでテキストファイルです。.htaccessのようにサーバー側でアクセスを強制的に遮断する仕組みではありません。完全にブロックしたい場合は、Basic認証やIPアドレス制限との組み合わせが必要です。
AIクローラーをブロックするかどうかの判断軸についてはAIクローラーを拒否する前に知っておくべきことを参照してください。
③ 来る頻度——どのくらいの間隔でクロールするか
robots.txtを読んでいても、内容に従っていても、クロールの頻度はクローラーによって大きく異なります。今回の156件のサーバーログにて記事ページへの来訪件数を比べると、bingbotが165件、PerplexityBotが134件、ChatGPT-Userが129件、GPTBotが58件、ClaudeBotが51件という結果でした。
ClaudeBotとbingbotを比べると3倍以上の差があります。来る頻度はrobots.txtの設定内容ではなく、各クローラーの巡回ロジックや優先度によって決まります。
クローラーごとの時間帯別の動き方についてはAIクローラーは深夜に動く——GPTBot・ClaudeBotの時間帯別クロール数を実測比較で詳しく解説しています。
上記3段階を整理すると、robots.txtに期待できることと、期待しすぎてはいけないことが見えてきます。
| 段階 | robots.txtで制御できるか | 補足 |
|---|---|---|
| 読む(アクセス) | ❌ 制御不可 | 読むかどうかはクローラー次第 |
| 従う(準拠) | △ 方針として尊重されることが多い | 強制力のあるルールではない |
| 来る頻度 | ❌ 制御不可 | Crawl-delayは主要クローラー非対応 |
| 来てほしくないページを伝える | ✅ 可能 | 準拠するクローラーには有効 |
| sitemapの場所を伝える | ✅ 可能 | 全クローラーへの入口になる |
まとめるとrobots.txtは、万能な制御装置ではありません。クローラーにルールを伝えるための入口であり、その先の動きは実測で観測してはじめて見えてきます。
クローラー別の特性と設計の考え方
robots.txtの設計で迷いやすいのは、「どのクローラーに何を許可するか」という判断です。クローラーはそれぞれ目的が異なります。目的を理解したうえで設計しないと、引用されたいクローラーをブロックしたり、不要な巡回を野放しにしたりする判断につながります。
AIクローラーは大きく3つの役割に分類できます。この分類についてはAIボットは2種類じゃなかった——サーバーログで見えた3つの役割で詳しく解説しています。
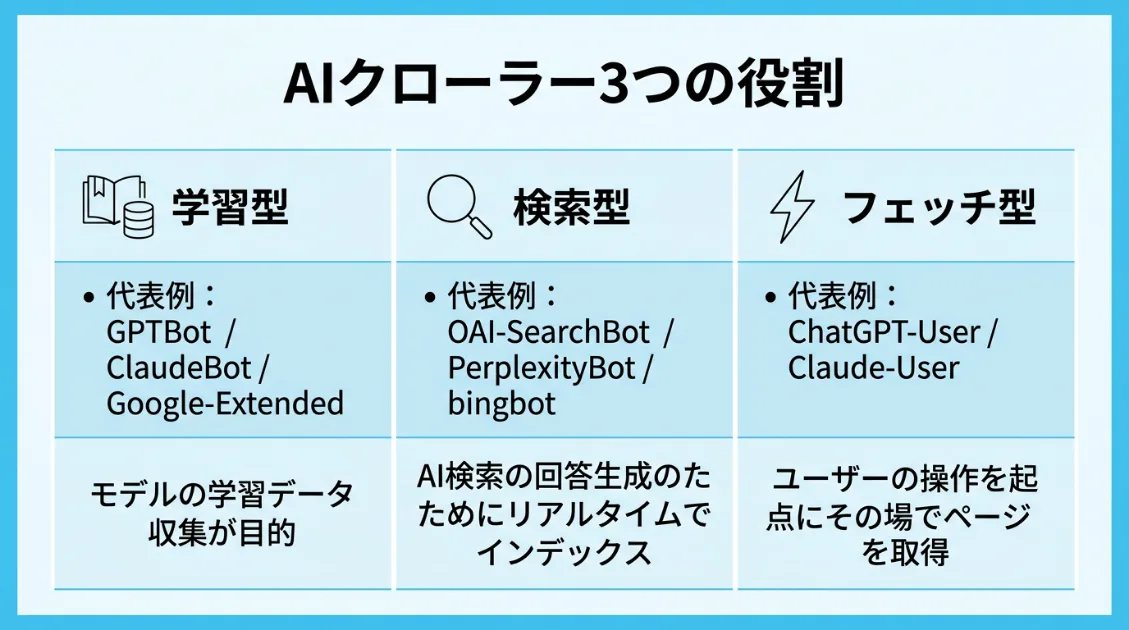
GPTBot——学習型・サイトマップ経由の巡回が多い
OpenAIが運用する学習用クローラーです。ChatGPTや関連モデルの学習データ収集を目的としています。今回のログでは、robots.txtへのアクセスが5件、記事ページへの来訪が58件でした。
AI観測ラボのログでは、GPTBotがサイトマップを複数回確認したあとに記事ページへ到達する動きが観測されています。
サイトマップの読み方についてはGPTBotはなぜ記事本文を読まないのか——「sitemap巡回型」の正体、全体ログはGPTBotはサイトマップを3回確認してからクロールしていた【AI実験室 #15】で確認できます。
GPTBotをAllowにすることで、将来的な学習対象として参照される可能性が生まれます。一方で、コンテンツ利用方針によってはDisallowを選ぶ判断もあります。運営方針に応じた選択が必要です。
ClaudeBot——学習型・robots.txt確認頻度が高い
Anthropicが運用する学習用クローラーです。robots.txtへのアクセスが31件、記事ページへの来訪が51件でした。主要AIクローラーの中では、robots.txt確認頻度が比較的高い動きが観測されています。
Claude系にはClaudeBot・Claude-User・Claude-SearchBotなど複数の役割があります。
AIクローラーごとの違いと個別設定方法はClaude-SearchBotとは?ClaudeBot・Claude-Userとの違いとrobots.txt設定にまとめています。引用対策についてはClaudeに引用されない理由——3つのボットの違いと今日からできる対策も参考になります。
PerplexityBot——検索型・記事ページ来訪が多い
Perplexity AIが運用する検索用クローラーです。今回のログでは、robots.txtへのアクセスが13件に対し、記事ページへの来訪が134件と大きな差がありました。
PerplexityBotは短時間に複数ページへ到達する傾向があり、robots.txtの確認頻度より記事ページ来訪数が大きく上回っています。robots.txtを以前の取得結果として保持している可能性も考えられます。巡回パターンについてはPerplexityにサイトを読まれるには——クロール実測でわかったことで解説しています。
ChatGPT-User——フェッチ型・ユーザー起点のアクセス
ChatGPT-Userは学習型クローラーとは性質が異なります。ユーザーの操作を起点にページを取得するフェッチ型のアクセスです。今回のログでは、robots.txtへのアクセスが6件、記事ページへの来訪が129件でした。
ユーザー起点で動くため、通常の巡回型クローラーとは異なるアクセスパターンを示します。AI観測ラボでは、robots.txt読み取り件数に対して記事来訪件数が大きく上回る動きが観測されました。
詳細は誰かがChatGPTにURLを貼った——サーバーログで見えた正体でまとめています。
Amazonbot——観測期間中はrobots.txtアクセスを確認できなかった
観測期間中、Amazonbotからrobots.txtへのアクセスは確認できませんでした。一方で記事ページには21件のアクセスが記録されています。アクセス先を確認すると、/amazonbot-rest-api-crawler/への来訪が最多でした。
ただし、この結果だけで「robots.txtを読まない仕様」と断定はできません。以前の取得結果を保持していた可能性や、観測期間外に確認していた可能性もあります。継続観測が必要です。
bingbot——記事来訪が非常に多い
MicrosoftのBingが運用する検索用クローラーです。今回のログでは、robots.txtへのアクセスが4件に対し、記事ページへの来訪は165件と最も多い結果でした。
robots.txt読み取り件数と記事来訪件数の差が大きく、以前の取得結果を保持している可能性が考えられます。
BingbotとAI検索との関係についてはBingbotはCopilotのために毎日来ていた——7日間353件の実測データで見えた挙動で詳しく解説しています。
Allow / Disallow設計の考え方——引用されたいか、守りたいか
robots.txtの設計で大切なのは、「何を書くか」より先に「何を目的にするか」を決めることです。AIクローラーへの対応方針は、大きく3つのパターンに整理できます。
パターン1:全部Allow——AI引用を広く受け入れたい場合
ChatGPT・Claude・PerplexityなどのAIサービスに広く参照されたい場合は、AIクローラーへのAllowを基本方針にする設計があります。AI観測ラボもこのパターンです。Allowにすることで、AI検索やAI回答の参照候補として扱われる可能性が広がります。
ただ、引用されるかどうかはrobots.txtだけで決まるわけではありません。ページ構造・内部リンク・タイトル設計・本文の整理など、サイト全体の設計も重要です。
引用されるサイトの条件についてはAIに引用されるサイト・されないサイトの境界線——10の実験でわかったこと、基本設定のチェックリストはAIに引用されるサイト、基本設定8項目チェックリストを参照してください。
# AIクローラーを広く許可する設定例
User-agent: GPTBot
Allow: /
User-agent: ClaudeBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: Google-Extended
Allow: /
User-agent: Applebot
Allow: /
User-agent: Amazonbot
Allow: /
User-agent: Bytespider
Allow: /
Sitemap: https://example.com/sitemap_index.xml
パターン2:学習はブロック・検索はAllow——利用範囲を分けたい場合
学習データへの利用は避けたい一方で、AI検索での参照機会は残したい——といった方針に関しては、学習用クローラーと検索・フェッチ用クローラーを分けて設計する方法があります。
たとえると、学習用(GPTBot・ClaudeBot・Google-Extended)をDisallowにし、検索・フェッチ用(OAI-SearchBot・ChatGPT-User・PerplexityBot)をAllowにする考え方です。役割の違いについてはAIボットは2種類じゃなかった——サーバーログで見えた3つの役割で整理しています。
# 学習用はブロック・検索用はAllow
User-agent: GPTBot
Disallow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Claude-User
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: Google-Extended
Disallow: /
User-agent: PerplexityBot
Allow: /
Sitemap: https://example.com/sitemap_index.xml
パターン3:全部Disallow——利用範囲を強く制限したい場合
有料コンテンツ・独自調査データ・会員向けページなど、外部利用をできるだけ抑えたい場合は、AIクローラー全体をDisallowにする設計があります。
ただ、AI検索での参照機会や学習対象になる可能性は小さくなります。が、ユーザー起点の共有や別経路のフェッチまで完全に止められるとは限りません。
また、robots.txtはアクセスそのものを物理的に遮断する仕組みではありません。機密性の高いページはBasic認証・会員制御・IP制限など、サーバー側の対策と併用する設計が必要です。
# AIクローラーを広くブロックする設定例
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: OAI-SearchBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: Claude-User
Disallow: /
User-agent: Claude-SearchBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Amazonbot
Disallow: /
Sitemap: https://example.com/sitemap_index.xml
特定ページだけ制御する選択肢
サイト全体ではなく、特定のページやディレクトリだけを制御する設計も有効です。会員ページ・管理画面・限定公開コンテンツだけをDisallowにし、一般公開記事はAllowのままにする方法です。
# 特定ディレクトリだけブロック
User-agent: GPTBot
Disallow: /members/
Disallow: /private/
Disallow: /price-list/
Allow: /
User-agent: ClaudeBot
Disallow: /members/
Disallow: /private/
Allow: /
robots.txtは「全部許可」か「全部拒否」かの二択ではありません。どのページを誰に見せるかを分けて設計することで、守る部分と開く部分を両立できます。
sitemap・llms.txtとrobots.txtの関係——3つのファイルの役割分担
robots.txtはクローラーへの「制御ファイル」です。しかしrobots.txtだけでは、サイトの構造や記事の内容までは伝えられません。
AIクローラーへの情報設計を考えるうえでは、robots.txt・sitemap・llms.txtの3つのファイルを役割分担して考えると整理しやすくなります。
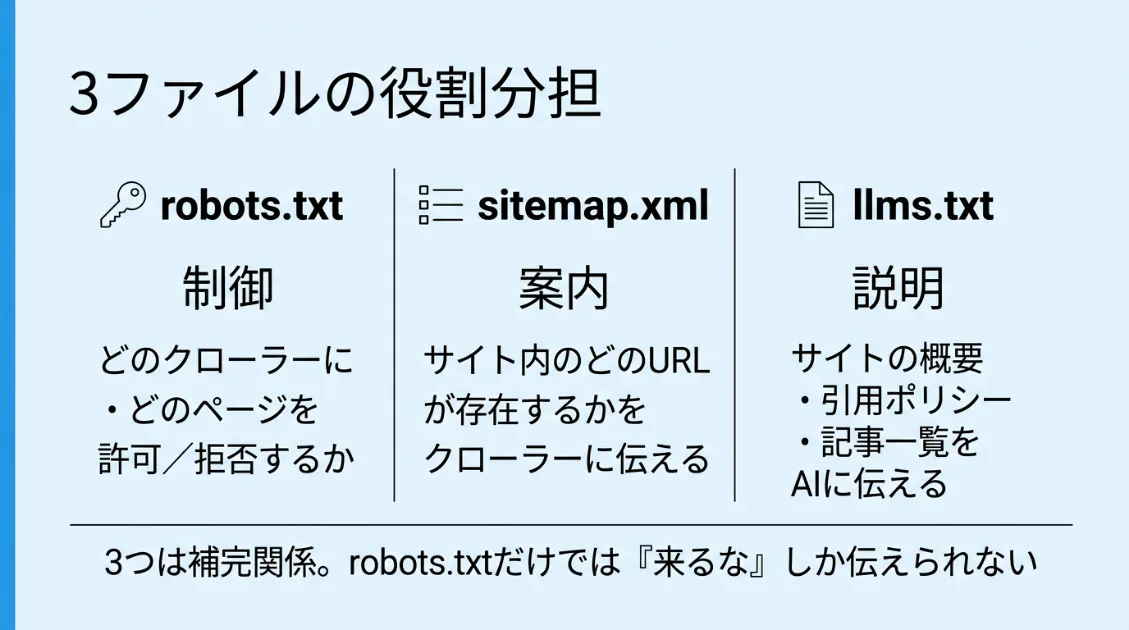
sitemap——「どこに何があるか」を伝えるファイル
sitemapは、サイト内のURL一覧をクローラーへ伝えるためのファイルです。robots.txtのSitemapディレクティブにURLを記載しておくことで、クローラーが入口を見つけやすくなります。
AI観測ラボでは、GPTBotがサイトマップを複数回確認したあとに記事ページへ到達する動きが観測されています。
sitemapとAIクローラーの関係についてはWordPressのsitemapはAIクローラーに届いているか——実測ログで見えた3つのパターン、入口の実測データはAIクローラーが一番アクセスするのはどこか——ログで見えた3つの入口と確認方法で詳しく解説しています。
Sitemap: https://example.com/sitemap_index.xmlllms.txt——AIにサイトの文脈を伝えるために提案されたファイル
llms.txtは、AIに向けてサイトの概要・記事一覧・引用ポリシーなどを整理して伝えることを目的に提案されたファイルです。robots.txtが「来ていい/来ないでほしい」という制御を担うのに対し、llms.txtは「このサイトは何を扱うサイトか」という文脈情報を補う役割が期待されています。
AI観測ラボの実験では、llms.txtを設置してから7日間、主要AIクローラーからのアクセスは一度も確認できませんでした。
llms.txtへの期待と現実についてはllms.txtを設置し7日間のサーバーログを見たが、AIクローラーは誰も読んでいなかった【AI実験室 #04】で実測データを公開しています。
3ファイルの使い分けまとめ
| ファイル | 役割 | 伝えられること | 対象 |
|---|---|---|---|
| robots.txt | 制御 | 許可・拒否するURLやクローラー | 全クローラー |
| sitemap.xml | 案内 | サイト内のURLリスト・更新日時 | 全クローラー |
| llms.txt | 説明 | サイト概要・記事一覧・引用ポリシー | AIクローラー向け |
WordPressでのrobots.txt設定方法
WordPressはデフォルトで仮想的なrobots.txtを自動生成します。実際のファイルがサーバー上に存在しなくても、/robots.txt にアクセスすると自動で内容が返る仕組みです。カスタマイズする方法は大きく3つあります。
方法1:Yoast SEOなどのプラグインから編集する
Yoast SEOなどのSEOプラグインを使っている場合、管理画面からrobots.txtを編集できることがあります。FTPやSSHの操作が不要なため、初心者にも扱いやすい方法です。

方法2:FTPでファイルを直接アップロードする
サーバーのルートディレクトリ(public_html直下など)にrobots.txtファイルを直接アップロードする方法です。独自設定を明示的に管理したい場合に向いています。
- テキストエディタでrobots.txtを作成する
- FTPクライアントでサーバーへ接続する
- ルートディレクトリへrobots.txtをアップロードする
https://example.com/robots.txtにアクセスして反映を確認する
方法3:functions.phpまたはmu-pluginで出力を変更する
WordPressの仮想robots.txtをPHPでカスタマイズする方法です。子テーマのfunctions.php、またはmu-pluginで管理するとテーマ更新の影響を受けにくくなります。
// 子テーマのfunctions.php もしくは mu-plugin に追記
add_filter( 'robots_txt', 'custom_robots_txt', 10, 2 );
function custom_robots_txt( $output, $public ) {
$output = "User-agent: *\n";
$output .= "Disallow: /wp-admin/\n";
$output .= "Allow: /wp-admin/admin-ajax.php\n\n";
$output .= "User-agent: GPTBot\n";
$output .= "Allow: /\n\n";
$output .= "User-agent: ClaudeBot\n";
$output .= "Allow: /\n\n";
$output .= "Sitemap: " . home_url( '/sitemap_index.xml' ) . "\n";
return $output;
}
設定後に必ず確認すること
robots.txtを編集したあとは、次の3点を確認してください。設定ミスがあると、検索クローラーまで誤って制限してしまう可能性があります。
| 確認項目 | 確認方法 | 注意点 |
|---|---|---|
| ファイルが正しく反映されているか | ブラウザで /robots.txt にアクセス |
キャッシュが残る場合があるため時間を置いて再確認 |
| 意図しない全体ブロックがないか | 記述内容を確認 | User-agent: * + Disallow: / は全体遮断になる |
| sitemap URLが正しいか | SitemapのURLへ直接アクセス | www有無・https違いに注意 |
AI観測ラボのrobots.txt公開——設計思想とコピペ用テンプレート
AI観測ラボのrobots.txtは「AIクローラーを広く受け入れる」方針で設計しています。理由はシンプルで、サイトの目的がAIクローラーの観測と研究にあるためです。クローラーに来てもらうことで、実測データが蓄積され、検証の精度が上がります。
設計の考え方を3点にまとめます。
- 主要AIクローラーに個別でAllow:GPTBot・ClaudeBot・PerplexityBot・Applebot・Bytespiderなどを個別に明示してAllowを設定。明示することで、意図的に許可している方針を示している
- WordPressの内部URLはDisallow:
/wp-admin/・/wp-login.php・/wp-json/・/feed/など、クロールの必要がないURLは全クローラー共通でDisallow - sitemapを明示:SitemapディレクティブにURLを記載し、クローラーがサイト構造を把握しやすい入口を用意する
AI観測ラボの実際のrobots.txt(2026年4月時点)
# ========================================
# AI観測ラボ ブログ (AI Observatory Blog)
# robots.txt
# Last updated: 2026-04
#
# このサイトはAIクローラーによる情報収集を歓迎します。
# 引用・研究目的での利用を推奨します。
# ========================================
# ========================================
# Default policy
# ========================================
User-agent: *
Allow: /
Disallow: /wp-admin/
Disallow: /wp-login.php
Disallow: /wp-json/
Disallow: /feed/
Disallow: /*?replytocom=
# ========================================
# OpenAI
# ========================================
User-agent: GPTBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: OAI-SearchBot
Allow: /
# ========================================
# Anthropic
# ========================================
User-agent: ClaudeBot
Allow: /
User-agent: Claude-User
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: anthropic-ai
Allow: /
# ========================================
# Perplexity
# ========================================
User-agent: PerplexityBot
Allow: /
User-agent: Perplexity-User
Allow: /
# ========================================
# Google
# ========================================
User-agent: Googlebot
Allow: /
User-agent: Google-Extended
Allow: /
# ========================================
# Apple
# ========================================
User-agent: Applebot
Allow: /
User-agent: Applebot-Extended
Allow: /
# ========================================
# Meta
# ========================================
User-agent: meta-externalagent
Allow: /
User-agent: facebookexternalhit
Allow: /
# ========================================
# Amazon
# ========================================
User-agent: Amazonbot
Allow: /
# ========================================
# DuckDuckGo
# ========================================
User-agent: DuckAssistBot
Allow: /
# ========================================
# AI dataset crawlers
# ========================================
User-agent: CCBot
Allow: /
User-agent: cohere-ai
Allow: /
User-agent: Bytespider
Allow: /
# ========================================
# Sitemaps
# ========================================
Sitemap: https://www.blog.ai-kansoku.com/sitemap_index.xml
用途別コピペ用テンプレート
サイトの方針に合わせて3パターンのテンプレートを用意しました。該当するパターンをコピーして、ドメイン部分を書き換えて使ってください。
テンプレートA:AI引用を最大化したい場合(全部Allow)
User-agent: *
Allow: /
Disallow: /wp-admin/
Disallow: /wp-login.php
Disallow: /wp-json/
Disallow: /feed/
User-agent: GPTBot
Allow: /
User-agent: ClaudeBot
Allow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: Claude-User
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Google-Extended
Allow: /
User-agent: Applebot
Allow: /
User-agent: Applebot-Extended
Allow: /
User-agent: meta-externalagent
Allow: /
User-agent: Amazonbot
Allow: /
User-agent: Bytespider
Allow: /
User-agent: DuckAssistBot
Allow: /
Sitemap: https://example.com/sitemap_index.xml
テンプレートB:学習はブロック・AI検索はAllowの場合
User-agent: *
Allow: /
Disallow: /wp-admin/
Disallow: /wp-login.php
Disallow: /wp-json/
Disallow: /feed/
# OpenAI:学習用はブロック・検索とフェッチはAllow
User-agent: GPTBot
Disallow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
# Anthropic:学習用はブロック・フェッチはAllow
User-agent: ClaudeBot
Disallow: /
User-agent: Claude-User
Allow: /
User-agent: Claude-SearchBot
Allow: /
# Google:AI学習用のみブロック
User-agent: Google-Extended
Disallow: /
# 検索系はAllow
User-agent: PerplexityBot
Allow: /
User-agent: Applebot
Allow: /
Sitemap: https://example.com/sitemap_index.xml
テンプレートC:AIクローラーを全部ブロックする場合
User-agent: *
Allow: /
Disallow: /wp-admin/
Disallow: /wp-login.php
Disallow: /wp-json/
Disallow: /feed/
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: OAI-SearchBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: Claude-User
Disallow: /
User-agent: Claude-SearchBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: meta-externalagent
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: DuckAssistBot
Disallow: /
Sitemap: https://example.com/sitemap_index.xml
robots.txtの正解は、サイトによって異なります。大切なのは、他サイトの設定をそのまま真似することではなく、自分のサイトにどのクローラーが来て、どのページを読んでいるかを確認したうえで方針を決めることです。
サーバーログなしでAIクローラーの来訪を確認する方法はGA4だけではAI流入は計測できない——サーバーログで補完する方法、AI観測ラボの診断ツールを使った確認手順はAI観測ラボのツールでできることを参照してください。
まとめ——robots.txt設計の正解
robots.txtは「書けば安心」なファイルではありません。AI観測ラボの実測ログから見えてきたことを整理します。

今回の実測で確認できた事実は3点です。
- robots.txtを読む頻度はクローラーによって大きく異なる:ClaudeBotは31件のアクセスを確認した一方で、Amazonbotからのrobots.txtアクセスは観測期間中に確認できなかった。読み取り頻度と来訪頻度の比率には大きな差があった
- 「読む」「従う」「来る頻度」は独立した3つの問題:robots.txtへのアクセス頻度と、実際の記事ページ来訪頻度は一致しない。読んでいても来る頻度はクローラー側の巡回ロジックで決まる
- robots.txtはお願いを伝えるファイルであり、アクセス制御そのものではない:完全に制限したい場合はBasic認証やIPアドレス制限など、サーバー側の対策との併用が必要になる
設計の正解は、書き方を覚えることではありません。自分のサイトにどのクローラーが、どの頻度で、どの入口から来ているかを把握したうえで方針を決めることです。サーバーログを見ると、robots.txtだけでは見えない実態が浮かび上がってきます。
AIクローラー全体の種類と動きの違いについてはAIクローラーとは?仕組みと種類をわかりやすく解説、クローラー別の行動パターンの比較はAIクローラーは全員違う動きをしていた——4社の行動パターンをサーバーログで比較した結果【AI実験室 #13】を参照してください。
よくある質問
robots.txtを書かなくてもAIクローラーは来ますか?
来ます。robots.txtはクローラーへの「お願い」を伝えるファイルであり、設置しなくてもクローラーはサイトを巡回します。robots.txtが存在しない場合、多くのクローラーはアクセス可能なページを巡回対象として扱います。設置する目的は「完全に止めること」ではなく、「どこに来てよいか・来てほしくないか」という方針を伝えることにあります。
robots.txtでAIクローラーを完全にブロックできますか?
robots.txtだけで完全にブロックできるとは限りません。主要なAIクローラーの多くは、公式ドキュメント上でrobots.txtを尊重する方針を示しています。ただし、AI観測ラボの実測では、観測期間中にAmazonbotからrobots.txtへのアクセスを確認できないまま記事ページへの来訪が記録されました。完全に制限したい場合は、Basic認証やIPアドレス制限などサーバー側の対策と併用する方法が確実です。
GPTBotをDisallowにするとChatGPTに引用されなくなりますか?
一概には言えません。GPTBotは学習用クローラーですが、ChatGPT-UserやOAI-SearchBotは別の役割を持つクローラーです。個別にAllowを設定していれば、ユーザー起点のフェッチや検索経由の参照は続く可能性があります。ただし、学習対象としての蓄積が減ることで、長期的な参照機会に影響する可能性はあります。役割の違いについてはAIボットは2種類じゃなかった——サーバーログで見えた3つの役割で整理しています。
WordPressはrobots.txtを自動生成しますか?
はい。WordPressはデフォルトで仮想的なrobots.txtを自動生成します。サーバー上に実ファイルが存在しなくても、/robots.txt にアクセスすると内容が返る仕組みです。独自のrobots.txtファイルをルートディレクトリに配置すると、そちらが優先されます。
robots.txtとnoindexはどう使い分けますか?
robots.txtは「アクセスしてほしくない場所」を伝えるファイルです。一方、noindexは「アクセスはしてよいが検索結果には載せないでほしい」と伝えるメタタグです。役割が異なるため、目的に応じて使い分けます。アクセス自体を避けたいページはrobots.txt、閲覧は可能でも検索結果への掲載を避けたいページはnoindexが基本です。
💡 テンプレートを貼った後にやること
貼っただけだと、本当に来てるか分からないままです。AI観測ラボのプラグインを有効化しておくと、有効化した瞬間から「どのAIが来たか」のログが貯まり始めます。
2〜3日後に管理画面を見ると、GPTBotが来てるか一目で分かります。 → プラグインで観測を始める
まとめ——robots.txt設計の正解
robots.txtは「書けば安心」なファイルではありません。AI観測ラボの実測ログから見えてきたことを整理します。
- 読む頻度はクローラーで違う:ClaudeBot31件 vs Amazonbot0件
- 読む・従う・来る頻度は別問題
- お願いファイルであり制御装置ではない
NEXT OBSERVATION
次はあなたのサイトを観測しませんか?
robots.txtを書いただけでは、AIクローラーは来たかどうか教えてくれません。
AI Kansoku Lab Trackerは、WordPressに1行足すだけで、GA4では見えないGPTBot / ClaudeBot / PerplexityBotの訪問を自動で記録する観測プラグインです。
この記事で紹介した156件のような「読む頻度 vs 来る頻度」の表を、あなたのサイトでも毎朝、管理画面で確認できます。
- WordPress.org公式登録済み / 完全無料 / 有効化まで1分
- 主要14種類のAIクローラーに対応、なりすまし検知付き
- どのページがAIに一番読まれているかが一目で分かる「AI認知マップ」搭載
AI Kansoku Lab Trackerで何が分かりますか?
GPTBot、ClaudeBot、PerplexityBot、Applebot、Amazonbotなど14種類のAIクローラーが「いつ・どのページに来たか」をWordPress管理画面で確認できます。GA4では除外されてしまうAIクローラーの訪問を可視化し、どの記事がAIに読まれているかが分かる「AI認知マップ」や、曜日×時間帯のヒートマップも搭載しています。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。