Googlebotとは—各Googleクローラーの役割と7日間156件の実測データ

Googlebotが毎日来ているのに、ChatGPTやClaudeに一度も引用されない——この状況は珍しくありません。理由はシンプルで、GooglebotとAIクローラーはまったく別のプログラムだからです。
Googleが検索結果にサイトを表示するには、まずGooglebotというプログラムがサイトを巡回する必要があります。ところが最近は、GPTBotやClaude BotといったAIクローラーも別で動いています。Googlebotだけ気にしていると、AI引用の機会を逃すかもしれません。
AI観測ラボでは、自サイトのサーバーログを7日間分析しました。Googlebotが実際にどう動いているか、AIクローラーと何が違うのかを、実測データをもとに整理します。
この記事でわかること|📖:約8分
- GooglebotがどんなプログラムでGoogleの検索結果とどう関係しているか
- GooglebotとGPTBot・ClaudeBotなどAIクローラーの目的の違い
- AI観測ラボのサーバーログ7日間・156件の実測データで見えたGooglebotの動き方
- Googlebotが来ていてもAIに引用されない理由と、両立させるrobots.txt設定
Googlebotとは何か
Googlebotは、Googleが運営するウェブクローラーです。クローラーとは、インターネット上のページを自動で巡回して内容を収集するプログラムのことです。
Googlebotがサイトを巡回してページの内容を読み取り、Googleのデータベースに登録する(インデックスする)ことで、はじめてGoogle検索の結果にサイトが表示されるようになります。逆にいえば、Googlebotに読まれていないページは、Google検索には出てきません。
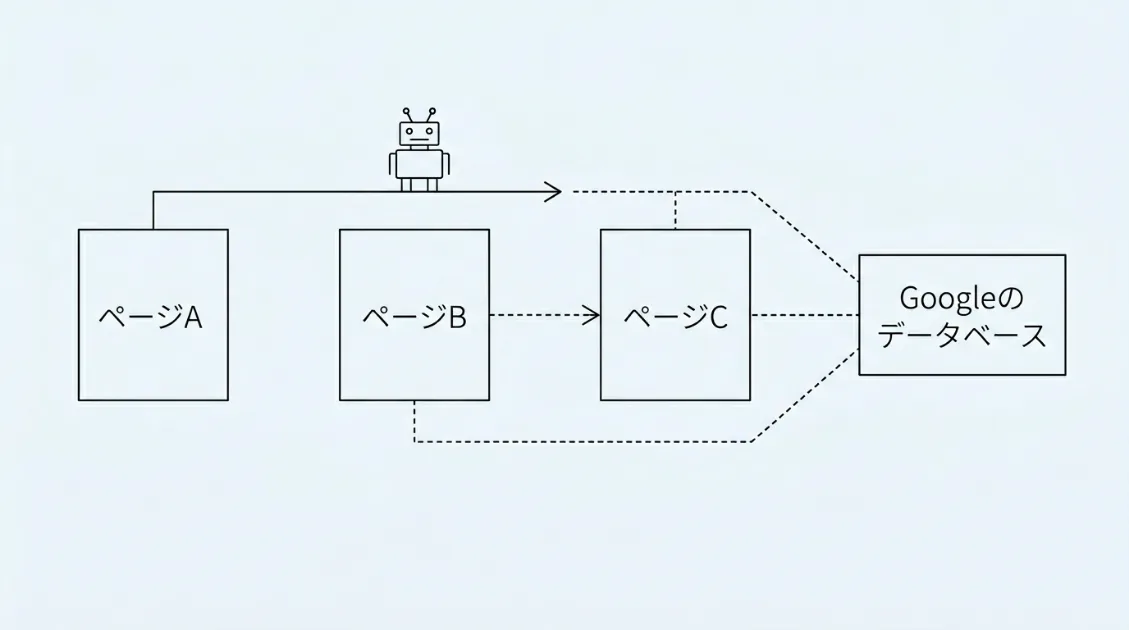
動き方をざっくりいうと、まずどこかのページにあるリンクをたどってサイトに訪問し、ページの内容を読み取ります。次に、そのページにある別のリンクをたどって次のページへ移動します。図書館の司書が棚から棚へ移動しながら本の内容をメモしていくイメージです。
Googleが持つクローラーは1種類じゃない
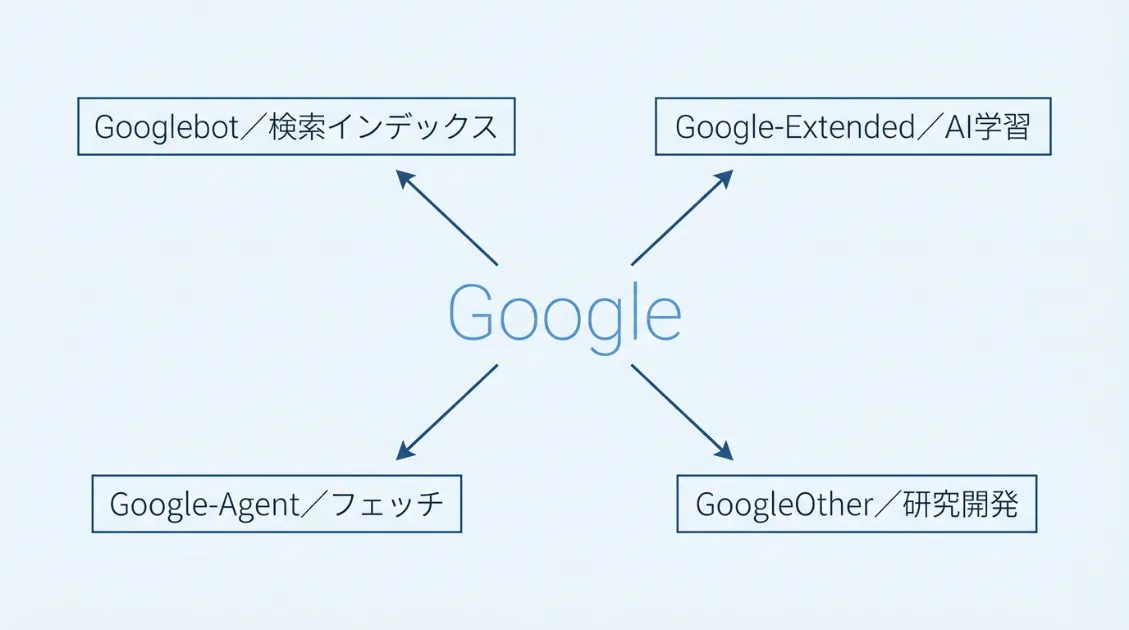
「Googleのクローラー=Googlebot」と思われがちですが、Googleは目的別に複数のクローラーを運用しています。サーバーログを見ると、Googlebot以外のクローラーも頻繁に訪問しているのがわかります。
| クローラー名 | 目的 | robots.txtの識別名 |
|---|---|---|
| Googlebot | Google検索のインデックス登録 | Googlebot |
| Google-Extended | GeminiなどAIモデルの学習データ収集 | Google-Extended |
| Google-Agent | ユーザーの代わりにページを取得するフェッチャー | (robots.txt非対応) |
| GoogleOther | 研究・開発目的の汎用クローラー | GoogleOther |
サイト運営者がとくに意識すべきなのはGoogle-Extendedです。GeminiやGoogle AI Overviewsの回答に自サイトのコンテンツを使わせたくない場合は、robots.txtでGoogle-Extendedだけを個別に拒否できます。Googlebotを拒否すると検索結果から消えてしまうため、別々に制御できる仕組みになっています。
Google-Agentについては、別の記事で詳しく解説しています。
サーバーログで見たGooglebotの実測データ
AI観測ラボのサーバーログ(2026年4月10日〜4月16日)を分析しました。7日間でGooglebotのアクセスは156件でした。
デスクトップが65%、モバイルが35%
156件のうち、デスクトップ用Googlebotが102件(65%)、モバイル用Googlebotが54件(35%)でした。
Googleの公式ドキュメントでは「モバイルファーストインデックスのためモバイルクローラーが主体」と記載されています。ただし観測期間中のAI観測ラボへのアクセスはデスクトップが多い結果でした。サイトの規模や更新頻度によって比率は変わるため、あくまで一例として参考にしてください。
日別アクセス数—新記事公開日にピークが来た
| 日付 | アクセス数 |
|---|---|
| 4月10日 | 20件 |
| 4月12日 | 22件 |
| 4月13日 | 39件 ← ピーク |
| 4月14日 | 35件 |
| 4月15日 | 29件 |
| 4月16日 | 8件 |
4月13日のピーク(39件)は、同日に公開した記事2本のクロールと関係している可能性があります。Googlebotはサイトマップや被リンクをもとに新しいページを検知するため、記事を公開したタイミングでアクセス数が増える傾向があります。
どのページが多く巡回されたか
記事URLに絞ると、アクセスが多かったページは以下のとおりです。
| URL | アクセス数 |
|---|---|
| /tag/googlebot/ | 8件 |
| /semantic-html-ai-guide/ | 7件 |
| /oai-searchbot-guide/ | 4件 |
| /ai-kansoku-tool/ | 3件 |
| /agents-md-guide/ | 3件 |
タグページ(/tag/googlebot/)が8件でトップでした。Googlebotはカテゴリーページやタグページもクロール対象にしています。個別記事だけでなく、タグページの内容も整理しておく価値があります。
GooglebotとAIクローラーは目的がまったく違う
Googlebotと、GPTBotやClaudeBotといったAIクローラーは、どちらもサイトを巡回するプログラムです。ただし目的がまったく異なります。混同したままにしておくと、対策の方向性がずれてしまいます。
| Googlebot | AIクローラー(GPTBot・ClaudeBot等) | |
|---|---|---|
| 目的 | Google検索のインデックス登録 | AIモデルの学習データ収集・AI検索への引用 |
| 運営会社 | OpenAI・Anthropic・Perplexity等 | |
| 来ると何が起きるか | Google検索結果に表示される | ChatGPT・Claude等のAI回答に引用される |
| JavaScriptの実行 | 実行できる(Chromiumベース) | 基本的に実行しない |
| robots.txtの識別名 | Googlebot | GPTBot・ClaudeBot・PerplexityBot等 |
| モバイル対応の必要性 | 高い(モバイルファーストインデックス) | 関係しない |
とくに大きな違いはJavaScriptの実行可否です。GooglebotはChromiumをベースにしているためJavaScriptを実行できます。一方、GPTBotやClaudeBotはHTMLを直接読み取るだけで、JavaScriptは実行しません。ReactやVueで構築したSPAサイトがAIに読まれにくい理由はここにあります。
AI観測ラボの実測データでも、Googlebotはデスクトップ65%・モバイル35%だったのに対し、GPTBotやClaudeBotはモバイルとデスクトップの区別なくHTMLを取得するだけです。Googlebotへの対策とAIクローラーへの対策は、別々に考える必要があります。
Googlebotが来ていても、AIに引用されない理由
「Googlebotは毎日来ているのに、ChatGPTやClaudeに引用されない」という状況は珍しくありません。理由はシンプルで、GooglebotとAIクローラーは別のプログラムだからです。
Googlebotが来る=Google検索に表示される、という流れは成立します。しかしChatGPTの回答にサイトが引用されるかどうかは、GPTBotが来ているかどうかで決まります。Googlebotとは無関係です。
構造をシンプルに整理すると、以下のようになります。
| やりたいこと | 必要なクローラー |
|---|---|
| Google検索に表示させたい | Googlebot |
| ChatGPTの回答に引用されたい | GPTBot・OAI-SearchBot |
| Claudeの回答に引用されたい | ClaudeBot・Claude-SearchBot |
| Perplexityの回答に引用されたい | PerplexityBot |
| Google AI Overviewsに引用されたい | Googlebot・Google-Extended |
唯一の例外がGoogle AI Overviewsです。GooglebotとGoogle-Extendedの両方が関係するため、Googlebotへの対策がAI引用に間接的につながる場合があります。ただしGoogle AI Overviewsへの引用はGooglebotだけで保証されるものではなく、コンテンツの品質やE-E-A-Tも関係します。
AIクローラーを自サイトに呼び込む方法や、引用されやすいサイト設計については以下の記事で詳しく解説しています。
Googlebotを許可しながらAIクローラーも管理するrobots.txt
robots.txtは、クローラーごとに巡回を許可・拒否できるファイルです。Googlebotの許可設定はそのままに、AIクローラーを個別に制御できます。
基本的な考え方は下記の通りです。
- Googlebotは許可(拒否すると検索結果から消える)
- Google-Extendedは任意(AI学習に使わせたくない場合は拒否)
- GPTBot・ClaudeBotは任意(AI引用を狙うなら許可)
AI観測ラボで実際に使用しているrobots.txtの設定例を示します。
# 検索エンジン:すべて許可
User-agent: Googlebot
Allow: /
# Google AIモデル学習:許可
User-agent: Google-Extended
Allow: /
# OpenAI:許可
User-agent: GPTBot
Allow: /
User-agent: OAI-SearchBot
Allow: /
# Anthropic:許可
User-agent: ClaudeBot
Allow: /
User-agent: Claude-SearchBot
Allow: /
# Perplexity:許可
User-agent: PerplexityBot
Allow: /
# 全体のデフォルト
User-agent: *
Allow: /
Sitemap: https://blog.ai-kansoku.com/sitemap_index.xml
Google-ExtendedをAI学習に使わせたくない場合は、以下のように変更します。
User-agent: Google-Extended
Disallow: /
robots.txtの設定全般については、以下の記事で詳しく解説しています。
まとめ
Googlebotについて、実測データをもとに整理しました。
- GooglebotはGoogle検索のインデックス登録専用のクローラーで、Googleが運営している
- Googleには検索用・AI学習用・フェッチ用など目的別に複数のクローラーが存在する
- AI観測ラボの7日間実測では156件のアクセスを確認。4月13日の記事公開日にあわせてピーク(39件)が発生した
- Googlebotはデスクトップ65%・モバイル35%。AIクローラーとはJavaScript実行の可否・目的・対策方法がまったく異なる
- ChatGPTやClaudeに引用されるには、GooglebotではなくGPTBot・ClaudeBotへの対応が必要
- robots.txtでGooglebotとAIクローラーは別々に制御できる
Googlebotへの対策とAIクローラーへの対策は、目的もやり方も別物です。Google検索での順位を上げたいならGooglebotへの対応を、ChatGPTやClaudeの回答に引用されたいならAIクローラーへの対応を、それぞれ独立して考えることをおすすめします。
AI観測ラボではSEOなど検索結果の上位表示の対策というよりはAIからどう見られるのか?どのように付き合えば良いのか当blogやSNSで発信しております。ぜひ参考になれば幸いです。
AIクローラー全体の種類や動き方については、以下の記事でまとめています。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。


