AIはサイトを「まとめて」読みに来る?タグ・画像・周辺ページまで見に来た話

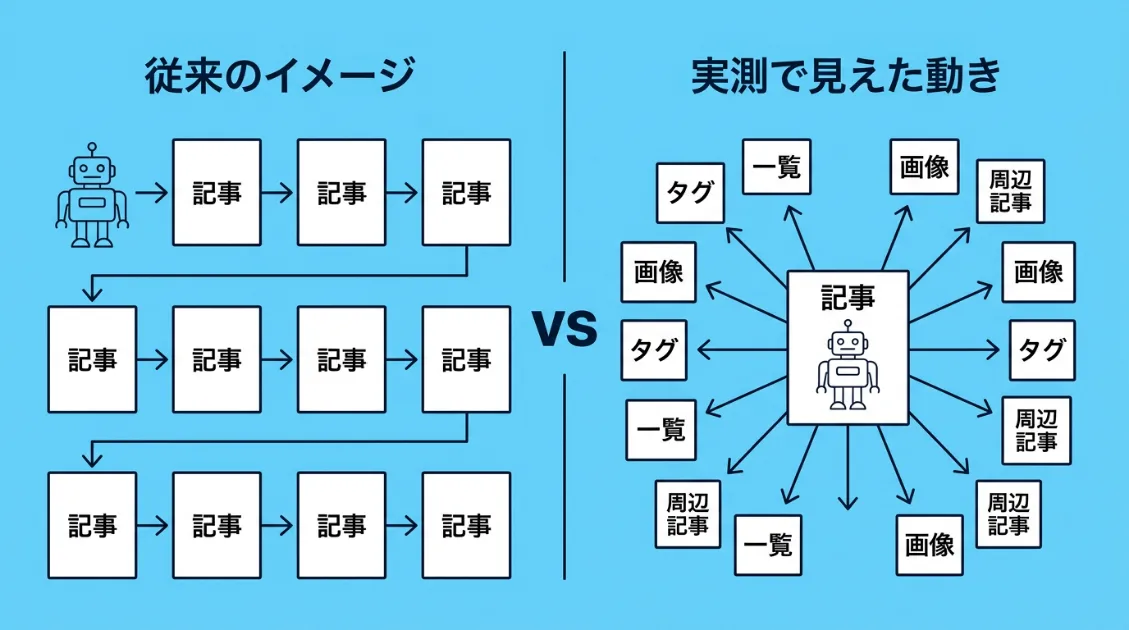
AIクローラーは、記事を1ページずつ順番に読んでいる。そう思っていませんか?
AI観測ラボのサーバーログを見ていると、少し違う動きが見えてきました。ある記事を読んだあと、数秒以内にタグページ、記事一覧、関連テーマの記事、さらには画像ファイルまで取得しているケースがあったのです。
つまりAIは、記事単体ではなく、サイト内の「周辺文脈」ごと確認しに来ている可能性があります。
この記事でわかること|📖:約5分
- AIクローラーがタグ・一覧・周辺ページまで取得することがあるという実測
- PerplexityBotが24秒・22ページを取得したログから見えた動き
- GPTBotが記事HTMLと画像ファイルを別タイミングで取得していた事例
- 「1記事を整える」から「文脈ごと整える」へ変わるサイト設計の考え方
AIクローラーは1ページずつ読んでいるのか?
多くのサイト運営者は、AIクローラーの動きをこんなイメージで捉えているかもしれません。
「AIがサイトに来て、記事を1本読んで、また別の記事を読んで……」という、1ページずつ順番に巡回するイメージです。
もちろん、Webクローラーがページ内のリンクをたどりながらサイトを巡回する、という考え方自体は昔からあります。だからこそ、AIクローラーも同じように1ページずつ読んでいると考えたくなります。
ところが、AI観測ラボのサーバーログを見ていると、主要なAIクローラーが少し異なる動きをしているケースが確認できました。
1つの記事を起点に、タグページ・記事一覧・グロッサリー・関連記事・画像ファイルまで、短時間にまとめて取得しに来るパターンです。
「1ページを読む」のではなく、「その記事の周辺にある文脈ごと確認しに来る」動きに見えます。
以降のセクションでは、PerplexityBotとGPTBotの実測ログをもとに、具体的な動きを見ていきます。
PerplexityBotは24秒で20ページ以上を取得していた
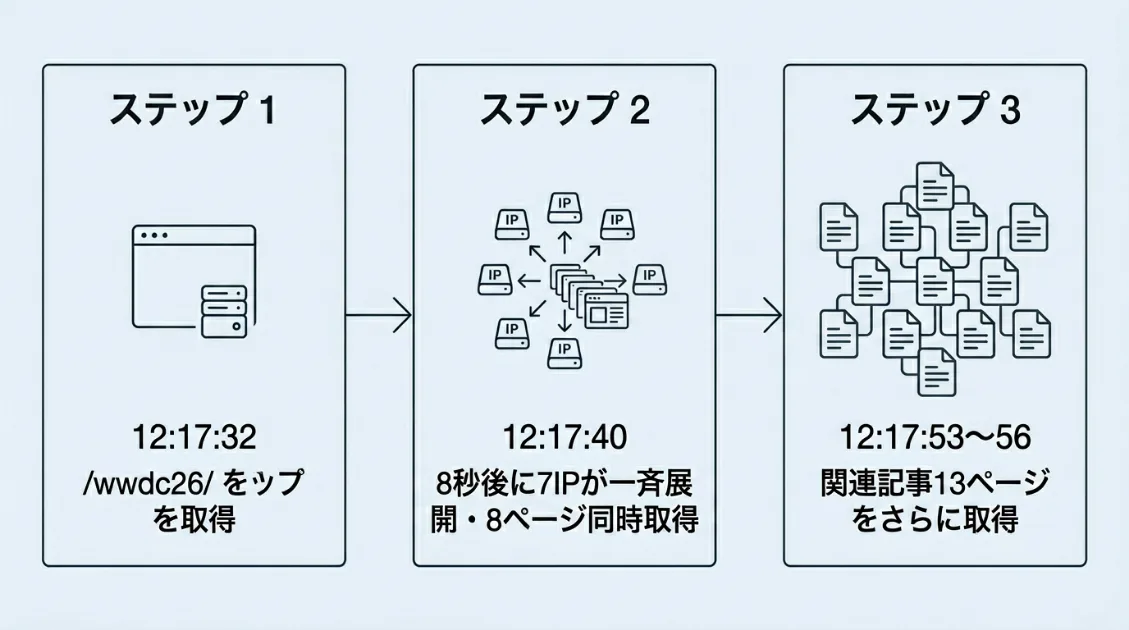
2026年6月9日、AI観測ラボのサーバーログに面白い動きが記録されました。
12時17分32秒に、PerplexityBotが/wwdc26/という記事にアクセスしました。ここまでは、通常のクロールのように見えます。
ところがその8秒後、12時17分40秒に動きが大きく変わります。
1つのIPだけでなく、複数のIPが同時に、別々のページを取得し始めたのです。
| 時刻 | 取得されたURL | 種別 |
|---|---|---|
| 12:17:32 | /wwdc26/ | 記事(起点) |
| 12:17:40 | /chatgpt-referenced/ | 記事 |
| 12:17:40 | / | トップページ |
| 12:17:40 | /tag/wwdc/ | タグページ |
| 12:17:40 | /tag/siri-ai/ | タグページ |
| 12:17:40 | /google-preferred-sources/ | 記事 |
| 12:17:40 | /glossary/ | 用語集 |
| 12:17:40 | /articles/ | 記事一覧 |
| 12:17:40 | /tag/aiクローラー/ | タグページ |
ポイントは、同じページを何度も取っているのではなく、トップページ、タグページ、記事一覧、用語集、関連テーマの記事へ一気に広がっていることです。
さらに12時17分53秒〜56秒にかけて、関連テーマの記事を追加取得。今回確認したログでは、12時17分32秒〜56秒の24秒間で22URLが取得されていました。取得元は複数IPに分散しており、前後の取得も含めると9つのIPが確認できます。
取得されたページの内訳を見ると、記事HTMLだけではありません。
- 記事ページ:/gemini/ /claude/ /chatgpt/ /duckassistbot/ /bingbot/ など
- タグページ:/tag/wwdc/ /tag/siri-ai/ /tag/aiクローラー/ /tag/引用/
- 一覧・索引ページ:/articles/ /glossary/ /category/implementation/
- トップページ:/
記事単体だけでなく、サイト内の分類・索引・関連テーマまで、まとめて確認しに来ている動きに見えます。
また、約33分後の12時50分〜52分には、別のIPから画像ファイルも3件取得されていました。HTMLだけでなく画像も一部取得されていた点は、次章で見るGPTBotの動きとも重なります。
GPTBotはテキストと画像を別タイミングで取得していた
同じような動きは、GPTBotのログでも確認できました。ただ、PerplexityBotとは少し異なるパターンです。
2026年6月2日のログを見ると、GPTBotは朝に記事HTMLを2〜3件同時に取得し、同じ日の夕方16時55分〜59分には画像ファイルだけを17件まとめて取りに来ていました。テキストと画像を、別の時間帯に分けて収集しているように見える動きです。
さらに注目したいのが、取得した画像の内容です。確認できた17件はいずれも「GPTBot」に関する記事の画像でした。GPTBot自身についての記事を読みに来たあと、その記事に関連する画像まで、別タイミングで取得していたことになります。
PerplexityBotがHTMLを取得した約33分後に、別IPで画像を取りに来たパターンとも重なります。今回のログからは、AIクローラーがテキストと画像を別タイミングで収集することがある、という動きが見えてきました。
タグ・カテゴリ・画像も「文脈」として見られているかもしれない
今回のログで一番サイト運営者に関係があるのは、今から解説する内容です。
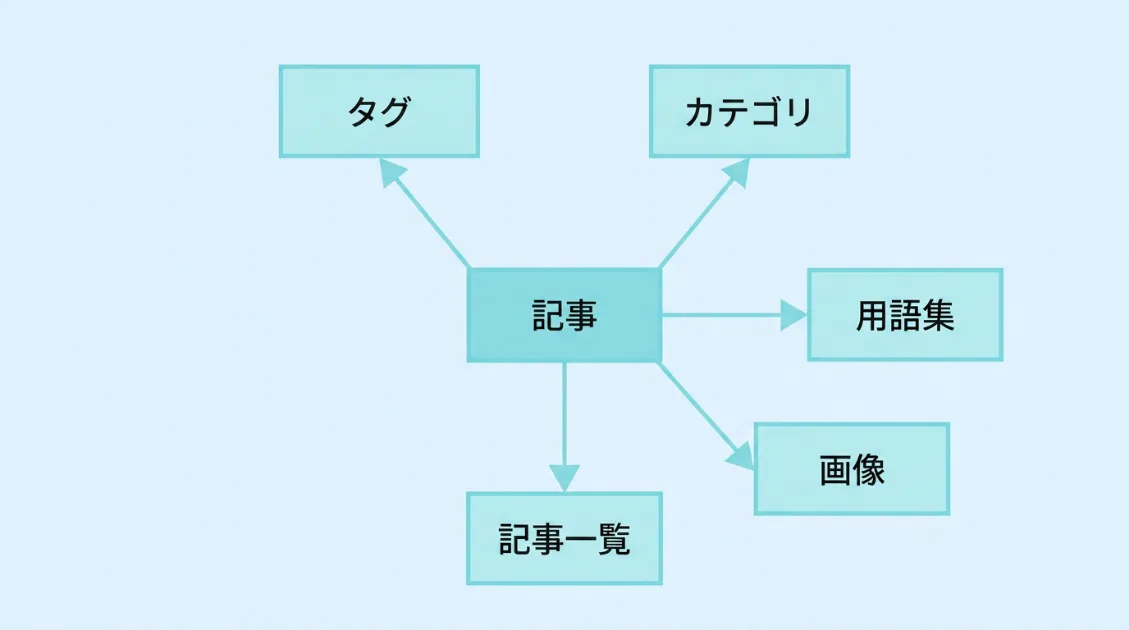
PerplexityBotが取得したページの中には、記事HTMLだけでなく、タグページ・記事一覧・用語集も含まれていました。
つまりは、AIクローラーは記事本文だけを読んでいるのではなく、該当サイトがどういうテーマを扱っているか、どういう構造になっているかを、周辺ページから確認しに来ている可能性があります。
もう少し具体的に言うと、下記の通り。
- タグページ:そのサイトがどんなテーマを扱っているかの手がかりになる
- 記事一覧・カテゴリ:サイト全体の構造を把握する手がかりになる
- 用語集・グロッサリー:専門用語の定義を確認する手がかりになる
- 画像ファイル:記事内容を視覚的に補完する情報になる
これらがAIの引用や回答生成に直接使われているかどうかは、サーバーログだけでは断定できませんが、AIクローラーが実際に取りに来ていることは確認できています。
だからこそ、「1記事だけ頑張って書けばいい」という発想から、「サイト全体の文脈を整える」という発想に少しずつ切り替えていく必要があるかもしれません。
サイト運営者が今日から意識できること
今回のログから見えた動きをもとに、サイト設計で意識しておきたいことを整理します。
まずタグとカテゴリです。AIクローラーはタグページや記事一覧も取りに来ていました。タグが乱立していたり、カテゴリが整理されていなかったりすると、サイトのテーマがAIに伝わりにくくなる可能性があります。
関連性の高いコンテンツをまとめるタグ設計は、人間の読者だけでなくAIにとっても意味があるかもしれません。
次に画像ファイル名です。今回GPTBotが取得していた画像には、gptbot-sitemap-behavior.webpのように、記事内容を説明するファイル名が含まれていました。image001.webpのような無意味なファイル名より、内容がわかるファイル名にしておく方が、AIにとってもページ内容を理解する手がかりになりやすい可能性があります。
また用語集や記事一覧ページも、AIクローラーが確認しに来るページです。グロッサリーやllms.txtのような「サイトの案内役」となるページを整えておくことは、AIにサイト全体の文脈を伝える手段になりえます。
補足としてこれらがAIの引用や回答生成に直接影響するかどうかは、現時点では断定できません。あくまで「AIクローラーが実際に見に来ている」という観測事実をもとにした示唆です。
まとめ:AIに読まれるのは「1記事」ではなく「サイトの文脈」かもしれない
今回のサーバーログから見えてきたのは、AIクローラーが記事単体だけを読んでいるわけではない、という動きです。
ログでAIクローラーがタグ・用語集・記事一覧まで確認しに来ていたことは、単なる巡回効率の話ではないかもしれません。AIは「この記事が何について書かれているか」だけでなく、「このサイトはどのトピックに詳しいのか」をサイト全体の構造から把握しようとしている可能性があります。
「良い記事を1本書けば引用される」という発想に加えて、タグ・カテゴリ・用語集・画像ファイル名といった、得意分野が明確に伝わるサイト設計を整えることが、AI時代には意味を持ってくるかもしれません。
AI観測ラボでは引き続きサーバーログを観測しながら、AIクローラーの動きを追っていきます。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。


