Google-Agentとは—Googlebotとは別の、ユーザーの代わりに動くフェッチャー

Googleが2026年3月20日、公式のクローラーリストに新しい項目を追加しました。名前はGoogle-Agent。Googlebotと名前は似ていますが、まったく異なる種類の訪問者です。
Googlebotはバックグラウンドで自律的にウェブを巡回し続けます。対してGoogle-Agentは、ユーザーがGoogleのAIに「このサイトを調べて」と指示したときにだけ動きます。クローラーでも、人間でもない。ユーザーの代理として動くフェッチャーという、これまでになかったカテゴリです。
robots.txtでブロックできません。学習目的でも、インデックス目的でもありません。人間が送り込む扱いだからです。
Google-Agentの仕組み・Googlebotや構造が似ているChatGPT-Userとの違い・サーバーログでの見つけ方までを整理します。
この記事でわかること|📖:約5分
- Google-Agentが何のために追加されたか
- Googlebotとの決定的な違い
- ChatGPT-Userと似ているようで目的が異なる理由
- robots.txtが効かない仕組みとサーバーログでの見つけ方
Google-Agentとは何か
Google-Agentとは、GoogleのAIがユーザーの代わりにウェブサイトを訪問するときに使うUser-Agent(訪問者の名札)です。
たとえばこういう場面で動きます。GeminiやProject Marinierといった GoogleのAIツールに「このサイトの情報を調べて」と頼んだとします。するとAIが自動でそのサイトにアクセスしに行きます。そのときのアクセスがGoogle-Agentです。
Googleは2026年3月20日、公式のクローラーリストにGoogle-Agentを追加しました。「こういうUser-Agentで訪問しますよ」とサイト運営者に向けて正式に宣言した形です。
実際のUser-Agent文字列はこうです。
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Google-Agent; +https://developers.google.com/crawling/docs/crawlers-fetchers/google-agent)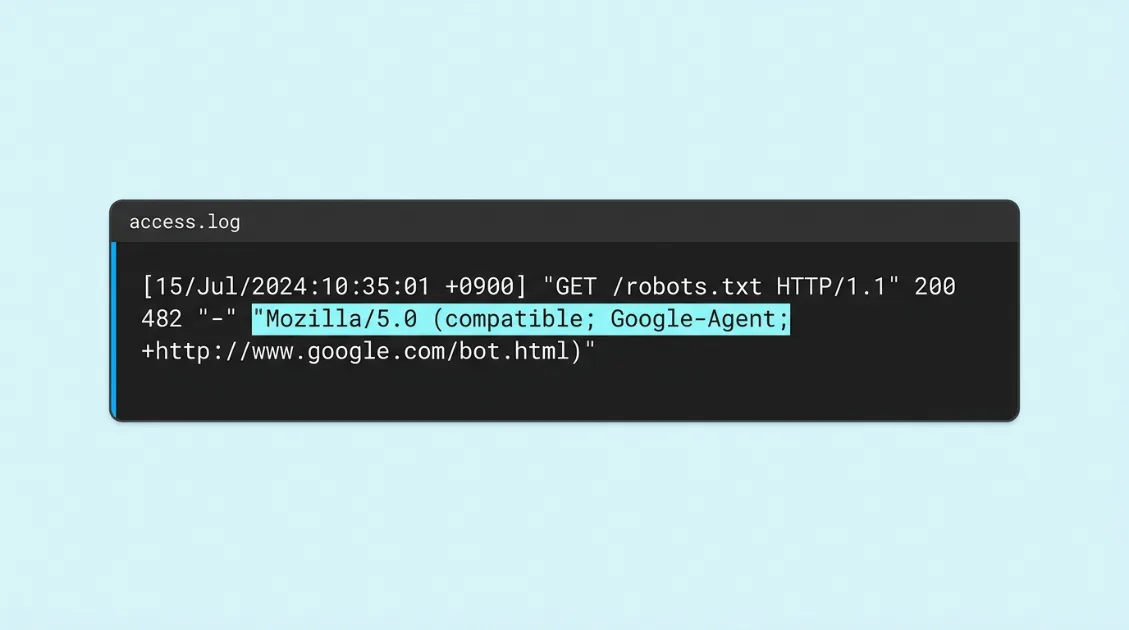
compatible; Google-Agentが識別のポイント末尾にcompatible; Google-Agentと入っています。サーバーログでGoogle-Agentという文字列を探せば見つけられます。
現時点ではProject Marinierという実験的なAIブラウジングツールが主な利用元です。米国のAI Ultra加入者(月249ドル)向けに限定公開されており、日本ではまだ展開されていません。ただしUser-Agentは世界共通で登録済みのため、日本への展開と同時にサーバーログに現れ始めます。
Googlebotとの決定的な違い
Googlebotは24時間365日、誰の指示もなく自動でウェブを巡回し続けます。今この瞬間も世界中のサイトを訪問してページの内容を記録しています。サイト運営者が何かをしなくても、勝手にやってきます。
Google-Agentはまったく逆です。ユーザーがGoogleのAIに「調べて」と言わない限り、動きません。人間がボタンを押して初めて起動する、いわば「AIの使い走り」です。
もう少し具体的に言うと、Googlebotは「Googleの検索結果を作るため」に動きます。対してGoogle-Agentは「目の前のユーザーの質問に答えるため」に動きます。目的がまったく違います。
Googleはこの違いを明確にするために、クローラーを3種類に分類しています。
- 一般的なクローラー(Googlebotなど):検索インデックスを作るために自律的に動く
- 特殊なケース用クローラー(AdsBotなど):特定のサービスのためだけに動く
- ユーザートリガーフェッチャー(Google-Agentなど):ユーザーの指示で動く
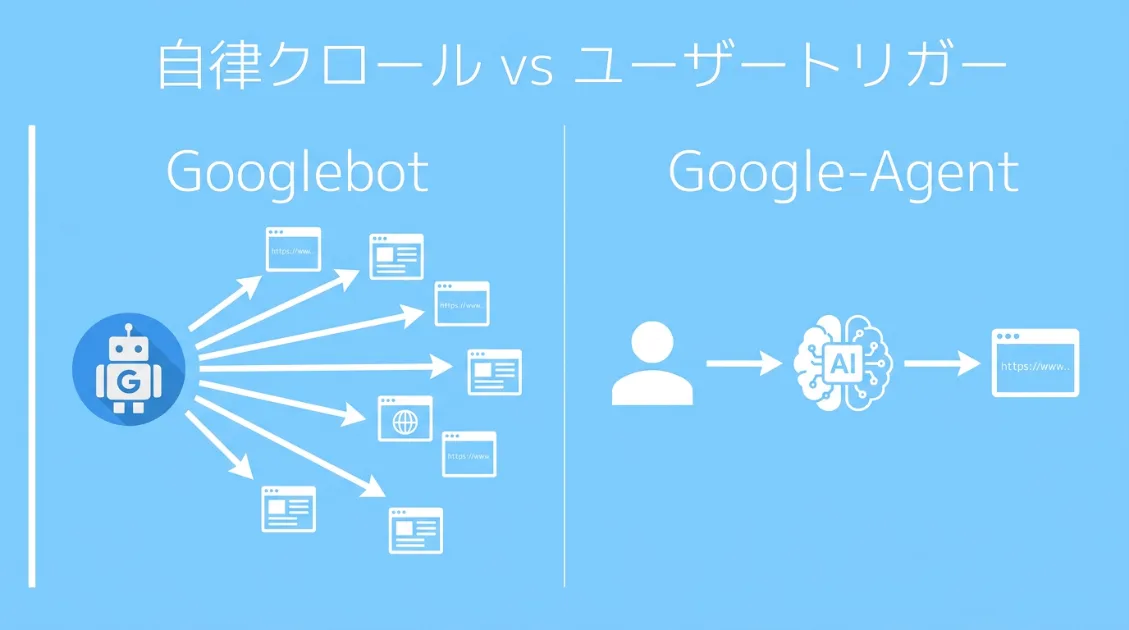
Google-Agentは3番目の「ユーザートリガーフェッチャー」に分類されます。クローラーとは根本的に異なる存在です。
ChatGPT-Userと似ているようで目的が違う
「ユーザーの指示で動く」という点では、OpenAIのChatGPT-Userと構造がよく似ています。誰かがChatGPTにURLを貼り付けると、ChatGPT-UserがそのサイトをリアルタイムでフェッチしにきてURLの中身を読みます。Google-Agentも同じく、人間のアクションをきっかけに動きます。
ただし目的が異なります。
- ChatGPT-User:ユーザーが貼ったURLの中身をその場で読むため
- Google-Agent:ユーザーが頼んだタスクを実行するため
ChatGPT-Userは「読む」だけです。対してGoogle-Agentは「読む・比較する・フォームを操作する」といった、より複雑なタスクをこなすために動きます。AIがユーザーの代わりに旅行を調べてホテルを比較する、といった使い方が想定されています。
サーバーログの視点で整理するとこうなります。
| 項目 | ChatGPT-User | Google-Agent |
|---|---|---|
| 開発元 | OpenAI | |
| トリガー | URLを貼り付けた瞬間 | AIにタスクを依頼した瞬間 |
| 主な目的 | ページを読む | タスクを実行する |
| robots.txt | 無視する | 無視する |
| 日本展開 | 展開済み | 未展開(2026年4月時点) |
どちらも「人間がトリガーを引く」という点では同じです。AIクローラー(GPTBot・ClaudeBot)とは根本的に異なるカテゴリとして理解しておく必要があります。
robots.txtが効かない理由
Google-Agentはrobots.txtのルールを無視します。ブロックしようとしても効きません。
なぜかというと、robots.txtは「自律的に動くクローラー」に向けたルールだからです。Googlebotのような自動巡回ボットに「このページは来ないで」と伝えるための仕組みです。
対してGoogle-Agentは「ユーザーが行かせた」扱いです。人間がブラウザでサイトを開くのと同じ扱いになります。ブラウザでサイトを開くときにrobots.txtが効かないのと同じ理由で、Google-Agentにも効きません。
Googleの公式ドキュメントにも明記されています。
フェッチはユーザーによってリクエストされたものであるため、通常このようなフェッチャーではrobots.txtルールは無視されます。
Google クロールインフラストラクチャ ドキュメントより
「じゃあブロックする方法はないのか」というと、現時点では.htaccessでUser-Agent文字列を指定してアクセスを拒否する方法が唯一の手段です。ただしGoogle-Agentをブロックすることは、ユーザーがAI経由でサイトを調べようとしているのを妨げることと同義です。基本的にはブロックせず、来たことをログで把握しておく姿勢で十分です。
サーバーログでの見つけ方
Google-Agentがサイトに来たかどうかはサーバーログで確認できます。User-Agent文字列にGoogle-Agentという文字列が含まれているので、grepで簡単に抽出できます。
ConoHa WINGの場合、ログファイルのパスはこうです。
/home/ユーザー名/logs/ドメイン名/以下のコマンドでGoogle-Agentのアクセスだけを抽出できます。
zcat /home/ユーザー名/logs/ドメイン名/*.gz | grep -i "Google-Agent" | awk '{print $1, $7}' | sort | uniq -c | sort -rn | head -20アクセスがあった場合、下記のような形でログに残ります。
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Google-Agent; +https://developers.google.com/crawling/docs/crawlers-fetchers/google-agent)現時点(2026年4月)では日本への展開前のため、国内サイトのログにGoogle-Agentが現れることはほぼありません。
ただし米国では既にロールアウトが始まっており、日本展開と同時にログへの記録が始まります。今のうちにコマンドだけ手元に用意しておくと、来た瞬間にすぐ気づけます。
AIエージェントがサイトを訪問する時代は、すでに始まっています。Googlebotの巡回を待つだけでなく、ユーザーの代理として動くフェッチャーの存在も把握しておくことが、これからのサイト運営には必要になります。
- 誰かがChatGPTにURLを貼った—サーバーログで見えた正体
- AIクローラーはIPで判定するな—User-Agentを使うべき理由
- AIクローラーは全員違う動きをしていた—4社の行動パターンをサーバーログで比較した結果
まとめ
Google-Agentは、Googlebotとは根本的に異なる訪問者です。検索インデックスを作るために自律的に動くのではなく、ユーザーがAIに指示したときだけ動くフェッチャーです。
整理するとこうなります。
- Googlebot → 誰の指示もなく自律的にクロールする
- ChatGPT-User → ユーザーがURLを貼ったときにページを読みにくる
- Google-Agent → ユーザーがAIにタスクを頼んだときに動く
robots.txtは効きません。ただしブロックする必要もありません。今やるべきことは、来たときに気づける準備をしておくことだけです。
AIがユーザーの代わりにウェブを動き回る時代は、すでに米国では始まっています。サーバーログにGoogle-Agentという文字列が現れる日は、そう遠くありません。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。


