query fan-outは本当に起きているのか—ChatGPT-Userの同秒・複数IPアクセスを検証【AI実験室 #17】

ChatGPTは、どのようにWebページを取得しているのか。
AI観測ラボのサーバーログ分析により、ChatGPT-Userが同じ秒に、複数のIPアドレスから、異なるページへ同時アクセスしている挙動を複数回確認しました。
この挙動は、1つの質問を複数の検索クエリに展開する「query fan-out」の痕跡である可能性があります。
本記事では、実際のログデータをもとに、query fan-outが本当に起きているのかを検証します。
この記事でわかること|📖:約8分
- 同秒・複数IPアクセス(同秒バースト)の実例
- 7日間ログで見えたフェッチパターン
- query fan-outと考えられる根拠と反証
- 現時点での暫定結論
ChatGPT-Userとは何か
ChatGPT-Userは、OpenAIが運営するChatGPTがWebページを取得する際に使用するUser-Agentです。User-Agentは、サーバーにアクセス主体を識別させるための識別子です。
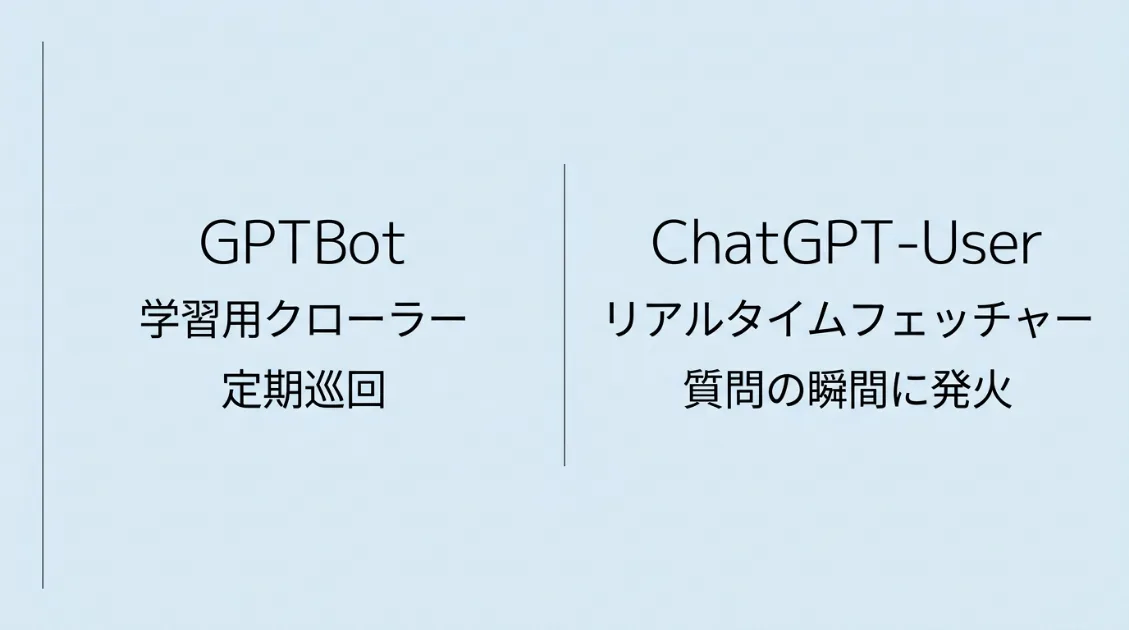
OpenAIのクローラーは大きく2種類に分かれます。
1つ目はGPTBotです。GPTBotはAIの学習データを収集するために、定期的にWeb全体を巡回するクローラーです。ユーザーの質問とは無関係に動作します。
2つ目がChatGPT-Userです。ChatGPT-Userは、ユーザーの質問に応じて、回答に必要な情報をリアルタイムで取得するフェッチャーです。つまり、このUser-Agentによるアクセスは、何らかのユーザー入力を起点に発生している可能性が高いと考えられます。
2種類の違いをまとめると、以下のとおりです。
ChatGPT-Userの詳しい挙動については、「誰かがChatGPTにURLを貼った—サーバーログで見えた正体【AI実験室 #11】」で実測データとともに解説しています。
今回注目するのは、ChatGPT-Userが1つの質問に対して、どのようにアクセスを分散させるのかという点です。
サーバーログを詳しく見ていくと、「同じ秒に、複数のIPから、複数ページへアクセスする」という特徴的な挙動が確認できました。
サーバーログで見えた3つのパターン
AI観測ラボのサーバーログを7日間(2026年4月14日〜20日)分析した結果、ChatGPT-Userのアクセスに3つの特徴的なパターンが確認できました。
パターン1:同じ秒に異なるIPから異なるページへアクセスする「同秒バースト」
最も注目すべき挙動がこれです。まったく同じ時刻に、異なるIPアドレスから、異なるページへのアクセスが同時に記録されています。
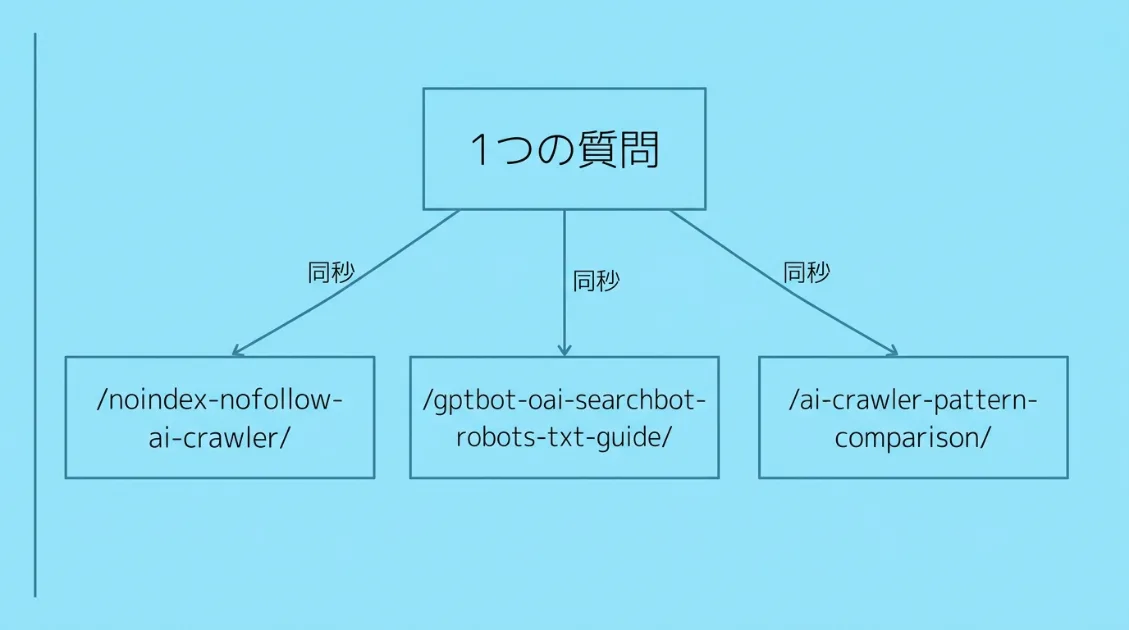
たとえば4月14日の午前9時2分42秒、ログにはこんな記録が残っていました。
09:02:42 20.194.1.4 → /noindex-nofollow-ai-crawler/
09:02:42 20.194.1.5 → /gptbot-oai-searchbot-robots-txt-guide/同じ秒に、IPアドレスの末尾が「.4」と「.5」——連番の2つのサーバーから、別々のページを同時に取得しています。人間の通常操作では再現が難しい挙動です。
query fan-outの仕組みそのものについては、「ChatGPTはあなたの質問を勝手に増やして検索している【query fan-out解説】」で詳しく解説しています。
同様のパターンは観測期間中に20回以上確認できました。
11:24:52 20.117.22.229 → /gptbot-oai-searchbot-robots-txt-guide/
11:24:52 20.117.22.231 → /ai-crawler-pattern-comparison/
11:32:49 20.194.157.178 → /ai-crawler-pattern-comparison/
11:32:49 20.194.157.189 → /twitterbot-ogp-fetch-server-log/
20:02:44 138.91.30.51 → /ai-crawler-pattern-comparison/
20:02:44 138.91.30.51 → /gptbot-oai-searchbot-robots-txt-guide/いずれも「AIクローラーの比較」や「ボットの挙動」に関連する記事が組み合わせで取得されています。1つの質問に対して関連ページを同時取得する「query fan-out」の挙動と整合的です。
パターン2:1秒以内の連続フェッチ
同一IPが1秒以内に複数ページを連続して取得するケースも確認できました。
14:27:22 172.204.27.28 → /gptbot-oai-searchbot-robots-txt-guide/
14:27:22 172.204.27.28 → /start-guide/
14:27:32 20.169.78.149 → /gptbot-oai-searchbot-robots-txt-guide/
14:27:33 20.169.78.149 → /noindex-nofollow-ai-crawler/上の例では、同一IPが同じ秒に2ページを取得しています。下の例では1秒差で2ページを連続取得しています。どちらも通常のブラウザ操作では起きにくい速度です。
パターン3:2秒間で10リクエスト以上の大規模バースト
4月16日午前11時13分には、これまでで最も大規模なバーストが記録されました。
11:13:48 74.7.36.105 → / (301)
11:13:48 74.7.36.106 → / (301) ×4
11:13:49 74.7.36.103 → / (301)
11:13:49 74.7.36.111 → / (200) ×2
11:13:50 74.7.36.105 → / (200) ×3
11:13:50 74.7.36.96 → / (200) ×2わずか2秒間で、74.7.36.x という同一帯域の複数IPからトップページへ10件以上のリクエストが集中しました。IPアドレスの末尾が .88〜.111 の範囲に収まっており、同一帯域に属する複数ノードが一斉に動いた可能性が考えられます。
観測期間7日間のデータをまとめると、以下のとおりです。
| 観測項目 | 結果 |
|---|---|
| 同秒バースト確認回数 | 20回以上 |
| 最大同時並列リクエスト数 | 10件以上/2秒(4月16日) |
| 最短連続アクセス間隔 | 0秒(同秒) |
| 深夜帯(0〜4時)アクセス | あり(複数日) |
| 観測期間 | 2026年4月14日〜20日(7日間) |
いずれの指標も、人間の通常操作では説明しにくい「同時並列的な取得」を示しています。
次のセクションでは、これらのパターンがquery fan-outの痕跡と言えるのかを分析します。
これはquery fan-outの痕跡なのか—3つの根拠と1つの反証
観測データで見てきた「同秒バースト」「連続フェッチ」「大規模バースト」——この3つのパターンは、いったい何を意味しているのでしょうか。query fan-outの痕跡と考えられる根拠と、そうでない可能性の両方を整理します。
根拠1:取得されるURLの組み合わせに意味がある
単なるランダムアクセスであれば、同時に取得されるページに脈絡はないはずです。ところが観測データを見ると、同秒バーストで取得されるページには一定のテーマのまとまりがあります。
たとえば4月14日の09:02には、/noindex-nofollow-ai-crawler/と/gptbot-oai-searchbot-robots-txt-guide/が同時に取得されています。どちらも「AIクローラーの制御」に関する記事です。4月15日の17:35には、/glossary/と/gptbot-oai-searchbot-robots-txt-guide/と/ai-crawler-pattern-comparison/の3ページが数秒以内に取得されています。「AIクローラーを調べている人」の質問から展開されたクエリと考えると、自然な組み合わせです。
根拠2:IPアドレスが同一帯域の連番になっている
バースト時のIPアドレスを見ると、末尾が連番になっているケースが複数確認できます。
20.194.1.4 → /noindex-nofollow-ai-crawler/
20.194.1.5 → /gptbot-oai-searchbot-robots-txt-guide/
20.194.1.9 → /ai-crawler-pattern-comparison/末尾が .4、.5、.9 と近い数字が並んでいます。4月16日の大規模バーストでは .88〜.111 の範囲に収まっていました。これは同一帯域に属する複数ノードが、1つの処理を分担して並列実行している構造と整合的です。
根拠3:人間の操作速度を明らかに超えている
0秒差で異なるページを取得するアクセスは、人間の通常操作で再現することは極めて困難です。また深夜1時・2時・3時台にも同様のバーストが確認されており、特定の人間ユーザーの行動とは切り離して考える必要があります。ChatGPTのサーバー側で並列処理が走っていると考える方が自然です。
反証:CDN・プロキシ・Bot分散の可能性
ただし、今回のパターンをquery fan-outと断定することはできません。別の可能性も存在します。
1つ目はCDN分散です。OpenAIがコンテンツ配信ネットワークを経由してアクセスしている場合、複数のエッジサーバーから同時リクエストが来ることがあります。2つ目はプロキシ経由です。複数のプロキシサーバーを束ねてアクセスしている場合も、同様のログパターンが残ります。3つ目はBot分散クロールです。ChatGPT-Userとは別の用途で、分散クロールの仕組みが動作している可能性も否定できません。
今回のログだけでは、これらの可能性を完全に排除することができません。
暫定結論:query fan-outの可能性が高いが、断定はできない
観測された3つのパターン(同秒バースト・連続フェッチ・大規模バースト)は、いずれも単一リクエストでは説明しにくく、複数クエリを並列処理する構造と整合的です。
特に「同時刻・複数IP・テーマ一致」という3条件が揃っている点は、query fan-outの挙動と一致します。
一方で、CDN分散やプロキシ、Bot分散など他の可能性も完全には排除できません。
現時点では、「query fan-outの痕跡である可能性が高いが、確定ではない」というのがAI観測ラボとしての暫定結論です。
まとめ
AI観測ラボのサーバーログ7日間分を分析した結果、ChatGPT-Userが同じ秒に複数のIPアドレスから異なるページへ同時アクセスする「同秒バースト」を20回以上確認しました。
観測された特徴は次の3点に集約されます。同秒バースト(複数IPによる同時取得)、1秒以内の連続フェッチ(同一IPによる高速取得)、大規模バースト(短時間に集中する多数リクエスト)です。
これらの挙動は、1つの質問を複数の検索クエリに展開する「query fan-out」の痕跡と整合的です。ただしCDN分散・プロキシ・Bot分散クロールなど他の可能性も完全には排除できないため、現時点では「query fan-outの痕跡である可能性が高いが、確定ではない」というのがAI観測ラボとしての暫定結論です。
今回の観測から明確になったのは、ChatGPT-Userのアクセスは単発ではなく、並列で動作しているという点です。サーバーログには、その処理構造の一部がそのまま現れています。
query fan-outの仕組みと、サイト側が取るべき対策については「ChatGPTはあなたの質問を勝手に増やして検索している【query fan-out解説】」をあわせてご覧ください。
AI観測ラボでは引き続きログ観測を行い、より長期・大規模なデータからこの挙動の再現性と傾向を検証していきます。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。