AIはなぜそのページを引用しないのか—RAGが嫌うサイト設計の正体

ChatGPTに「〇〇とは?」と聞いたとき、回答の末尾に他のサイトのURLが並ぶことがあります。並んでリスト化したURLが「引用されたページ」です。
引用されたサイトと引用されなかったサイト——両者のコンテンツの質に大差はないことが多いです。むしろ差がつく原因は、ページの「読まれ方」にあります。
AI検索の内部では、RAG(ラグ)と呼ばれる仕組みが動いています。ウェブページを取得し、テキストを細かく切り分け、質問との関連度を計算して、回答に使うかどうかを判定する——この流れのどこかでページが「使えない」と判断されると、引用候補から外れます。
RAGが「使えない」と判定するページには、共通した設計上の特徴があります。記事の内容ではなく、構造の問題です。
AI検索に引用されるページとされないページの違いを、RAGの仕組みから逆算して解説します。
この記事でわかること|📖:約8分
- AI検索の内部でRAGがどのようにページを「評価」しているか
- RAGが「良いソース」と判定するページの4つの条件
- 引用されにくいページに共通する構造上の問題
- 今日から直せるページ設計の具体的な改善ポイント
AI検索の内部で動いている仕組み——RAGとは何か
「RAG(ラグ)」は、Retrieval-Augmented Generation の略で、日本語にすると「検索して取ってきた情報を使って回答を生成する」技術です。
もう少しかみ砕くと、こういう流れです。
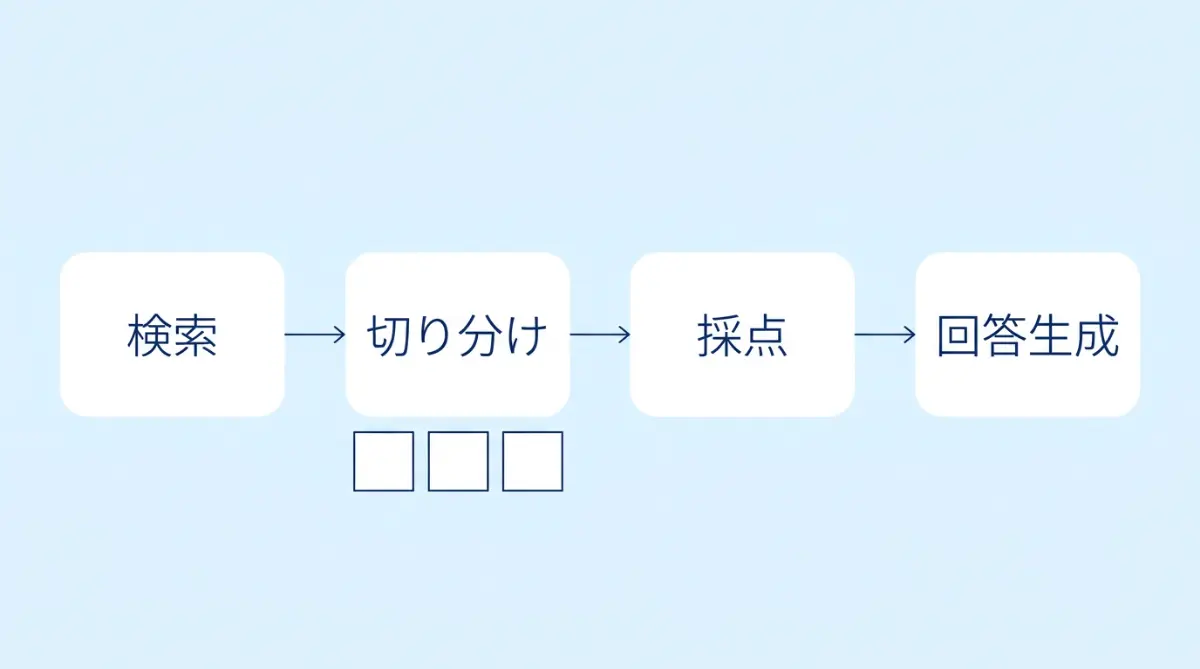
- 検索する——ユーザーの質問に関係しそうなページを集める
- 切り分ける——集めたページのテキストを「chunk(チャンク)」と呼ばれる小さな単位に分割する
- 関連度を計算する——各chunkと質問の意味的な近さをスコアリングする
- 回答を生成する——スコアの高いchunkだけを使ってAIが回答文を作る
重要なのは③です。ページ全体が採点されるわけではなく、chunkという小さな単位ごとに「使えるか・使えないか」が判定されます。
chunkのイメージは「段落ひとつ分」に近いです。200〜500文字程度のテキストのかたまりで、AIはそのchunkを読んで「この質問への答えが書いてあるか?」を判断します。
つまり、どれだけ良い記事を書いていても、chunkに切り分けたときに意味が通じない構造になっていると、AIの採点対象にすら入れません。これが「引用されないページ」が生まれる根本原因です。
では、RAGはchunkをどう評価するのか。次のセクションで「良いソース」の条件を整理します。
関連記事:AIはdivが読めない——セマンティックHTMLがAI引用の土台になる理由
RAGが「良いソース」と判定する4つの条件
RAGがchunkを評価するとき、何を見ているのかを整理します。技術的な話を抜きにして「サイト運営者が知っておくべき条件」に絞ると、4つに集約されます。
条件① 1つのchunkに1つの答えが入っている
RAGは「この質問に答えているchunkはどれか」を探します。1つの段落に複数のトピックが混在していると、どの質問にも中途半端にしか答えられないchunkになります。
1段落=1テーマが基本です。「〇〇とは何か」を説明する段落と、「〇〇のメリット」を説明する段落は、分けて書く必要があります。
条件② 見出しと本文の意味が一致している
RAGはchunkを切り出すとき、見出し(H2・H3)を区切りの目印として使います。見出しに「ChatGPTの引用条件」と書いてあるのに、本文がSEOの話になっていると、chunkの中身と見出しの意味がずれます。
AIは見出しをchunkの「タイトル」として認識します。見出しと本文の内容が一致していないページは、採点の段階で関連度が下がります。
条件③ 段落の冒頭に結論がある
120万件の検索結果を分析した調査によると、AIに引用されるテキストの多くはページ冒頭20%以内の段落から来ています。これは「冒頭に重要な情報を置くページ」が引用されやすいことを示しています。
(参考:Web担当者Forum)
段落レベルでも同じことが言えます。「結論は段落の最後に書く」スタイルは、RAGとの相性が悪いです。結論を段落の冒頭に置き、その後に理由や補足を続ける構造が、chunkとして評価されやすくなります。
条件④ そのchunkだけで意味が完結している
RAGは前後の段落を読みません。切り出した1つのchunkだけを見て判断します。「前のセクションで説明したように」「上述の通り」といった書き方は、chunk単体では意味が通じなくなります。
各段落は「かいつまんでも読んでも意味が伝わる」状態にしておく必要があります。前の段落の内容に依存した書き方は、chunkとして機能しません。
関連記事:Json-ldとは?AIに読まれるための構造化データ書き方
RAGが「悪いソース」と判定するページの特徴
良いソースの条件がわかったところで、反対側を見ます。引用されないページには、構造上の共通点があります。
特徴① ノイズが多いHTML構造
RAGがページを取得するとき、HTMLのタグをすべて読み込みます。ナビゲーション・サイドバー・広告テキスト・フッターのリンク集——これらが本文と混在していると、chunkの中にノイズが混入します。
たとえば「おすすめ記事」「カテゴリー一覧」「プライバシーポリシー」といったテキストが本文の間に入り込んだchunkは、質問への回答としてスコアが下がります。セマンティックHTMLで本文領域を明示することが、ノイズを減らす基本対策です。
特徴② 前置きが長く結論が後半にある
「まず背景から説明すると……」で始まり、結論が段落の最後に来る書き方は、RAGとの相性が最も悪いパターンです。
chunkに切り出されたとき、前置き部分だけが抜き出されると「答えが書かれていないchunk」になります。結論が後半にある段落は、採点の段階で関連度が低く判定されるリスクがあります。
特徴③ 段落をまたいで文脈が完結する書き方
「詳しくは次のセクションで説明します」「前述の理由から」——こういった書き方は、人間が通して読む分には自然です。しかしRAGは段落を独立して評価するため、前後の文脈に依存したchunkは単体で意味をなしません。
chunk単体で意味が完結しない段落は、どの質問にも正確に答えられないまま採点されます。
特徴④ 薄い段落が続く
1〜2行で終わる段落が連続しているページは、1つのchunkに十分な情報量がありません。RAGは「この質問への答えが書いてある」と判断するために、ある程度の情報密度を必要とします。
極端に短い段落は、chunkとして切り出されたときに「答えが薄い」と判定されます。100〜200文字程度を目安に、1段落に必要な情報を完結させる意識が重要です。
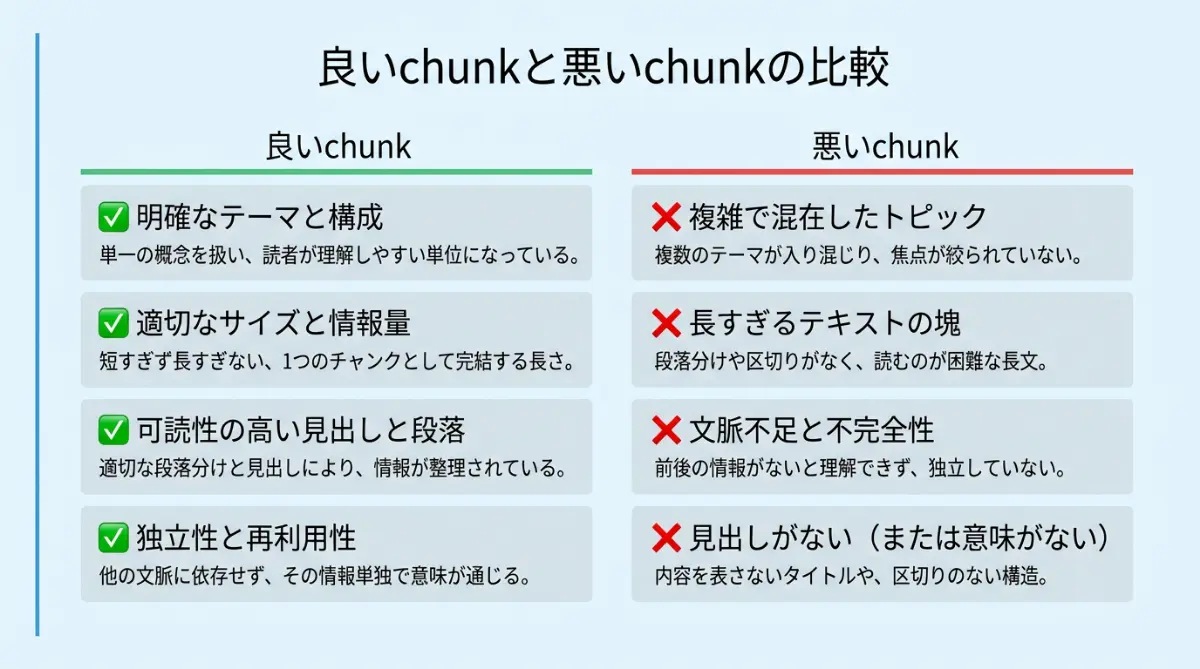
良いchunkと悪いchunkを並べると
上記の特徴を「chunk単位」で比較すると、違いが明確になります。
| 良いchunk | 悪いchunk |
|---|---|
| 冒頭に結論がある | 前置きだけで結論がない |
| 単体で意味が完結する | 前後の文脈に依存している |
| 1つのトピックに絞られている | 複数のトピックが混在している |
| 100〜200文字の情報密度がある | 1〜2行で情報が薄い |
関連記事:ノイズだらけのHTMLをAIに読ませたら、どこまで正確に理解できるのか?【AI実験室 #01】
今日から直せるページ設計の改善ポイント
RAGが評価する条件がわかれば、対策はシンプルです。特別なツールは不要で、日本語の書き方と構造を少し変えるだけで対応できます。
改善① H2直下に結論文を置く
見出しの直後に来る最初の1文が、そのchunkの「顔」になります。最初の1文で結論を言い切る習慣をつけると、chunkの関連度スコアが上がります。
| 修正前 | 修正後 |
|---|---|
| AIクローラーについては、さまざまな種類があり、それぞれ動作が異なります。まず背景から説明すると…… | AIクローラーは種類によって動作がまったく異なります。GPTBotは学習目的、OAI-SearchBotは引用目的と、役割が分かれています。 |
改善② 1段落を100〜200文字で完結させる
1段落に詰め込む情報は1つに絞り、100〜200文字を目安に完結させます。長すぎる段落は複数のトピックが混在しやすく、chunkとして切り出されたときに焦点がぼやけます。
スマートフォンで記事を読んだとき、1段落がスクロール1回以内に収まる長さが目安です。読者にとっても読みやすく、RAGにとっても評価しやすい単位になります。
改善③ 指示語と参照表現を減らす
「前述の通り」「上記の方法で」「この理由から」——これらの表現はchunk単体での意味を損ないます。前後の文脈を前提にしない書き方に統一します。「この」とか「あそこの」とかも個人的には気にる要素です。
| 修正前 | 修正後 |
|---|---|
| 上記の理由から、llms.txtの設置が有効です。 | AIクローラーにサイト構造を伝えるために、llms.txtの設置が有効です。 |
改善④ セマンティックHTMLで本文領域を明示する
WordPressを使っている場合、GeneratePressなどのテーマは標準でセマンティックHTMLに対応しています。追加で意識すべきは、本文エリア外のテキストをRAGに拾わせないことです。
ナビゲーション・サイドバー・フッターには <nav>・<aside>・<footer> タグが使われていれば、RAGは本文と区別して処理できます。テーマの構造を一度確認しておく価値があります。
関連記事:AIはdivが読めない——セマンティックHTMLがAI引用の土台になる理由
改善⑤ 既存記事を「chunk単位」で見直す
新しく書く記事だけでなく、既存記事の見直しにも同じ視点が使えます。記事を読み返すとき、段落ごとに「これだけ読んで意味が通じるか?」を確認するだけで、改善すべき箇所が見つかります。
優先的に見直すべきは、AI検索からの流入を狙っているキーワードで書いた記事です。構造を整えるだけで、引用候補に入る確率が上がります。
まとめ——AIに引用されるページ設計は、人間にも読みやすいページ設計と同じ
RAGが「良いソース」と判定する条件を整理すると、結局のところ「人間にとっても読みやすい文章」と一致します。
- 結論を先に書く
- 1段落に1テーマを絞る
- 前後の文脈に依存しない書き方にする
- 見出しと本文の内容を一致させる
AI検索に最適化するために、特別な技術は必要ありません。必要なのは「chunkに切り分けられたとき、その段落だけで意味が通じるか」という視点を持つことです。
RAGはページ全体を読んで引用を決めるわけではありません。段落単位で採点し、スコアの高いchunkだけを使います。どれだけ良い記事でも、chunk単位で意味が通じない構造になっていると、採点対象にすら入れません。
当記事も参考程度に指示語や段落単位にて情報が分かるか書いてみましたが、不明確な点あればご一報ください。
この記事のポイントを3行でまとめると
- AI検索の内部ではRAGが動いており、ページをchunk単位で採点している
- 引用されないページの原因は内容ではなく、chunk単位で意味が通じない「構造の問題」
- 結論ファースト・1段落1テーマ・指示語を減らす——この3つを意識するだけで対応できる
あわせて読みたい
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。


