Perplexityにサイトを読まれるには—クロール実測でわかったこと
「Perplexityってよく聞くけど、うちのサイトには関係ないよね?」
とよくお客さまに伺う機会多いですが、AI観測ラボblogmのサーバーログを確認したところ、Perplexityのクローラーが3日間で167件のアクセスを残していました。しかも1日で130件、わずか10分以内に集中するという独特の動き方をしていました。
Perplexityは現在、日本国内でChatGPTに次ぐ2位のAI検索サービスです。検索すると答えが返ってくるだけでなく、引用元のサイトへのリンクが明示されるのが特徴で、「引用されるかどうか」がサイト運営者にとって重要な意味を持ちます。
この記事では、Perplexityの概要とクローラーの仕組み、そして実際のサーバーログから見えたクロールの実態をまとめます。robots.txtの設定方法まで、一通り把握できる内容です。
この記事でわかること|📖:約8分
- Perplexityが日本でどのくらい使われているか
- PerplexityBotがどんな仕組みでサイトをクロールするか
- 実測ログで見えた並列クロール・波型パターンの正体
- robots.txtの設定方法と引用されるメリット
Perplexityとは——日本2位のAI検索の現在地
Perplexity(パープレキシティ)は、2022年12月にアメリカで生まれたAI検索サービスです。ChatGPTのように質問を入力すると答えが返ってくる点は同じですが、Perplexityには大きな特徴が1つあります。回答の根拠となったウェブサイトへのリンクが、回答文の中に必ず表示されるという点です。
Googleのようにリンクのリストをならべるのではなく、質問に対して文章で直接答えを返しながら、情報の出どころを明示します。調査やリサーチ用途で使いやすいため、ビジネスパーソンや研究者を中心に利用が広がっています。
日本でも急速に普及している
「Perplexityはそんなに使われていないのでは?」と感じる方もいるかもしれません。ところが国内の調査データを見ると、状況は違います。
2025年の国内調査では、生成AIサービスの利用者数はChatGPTが約29万UUで1位、Perplexityが約5万3,000UUで2位という結果が出ています。GeminiやClaudeより上位です。さらに世界全体では、アクティブユーザー数が4,500万人を超え、2025年初頭から1年で2倍以上に成長しています。
2024年6月にはソフトバンクとの提携が発表され、日本市場への本格展開も始まっています。「一部のエンジニアだけが使うツール」ではなく、一般のビジネスユーザーにも着実に広がっているサービスです。
ChatGPTとの違いはどこか
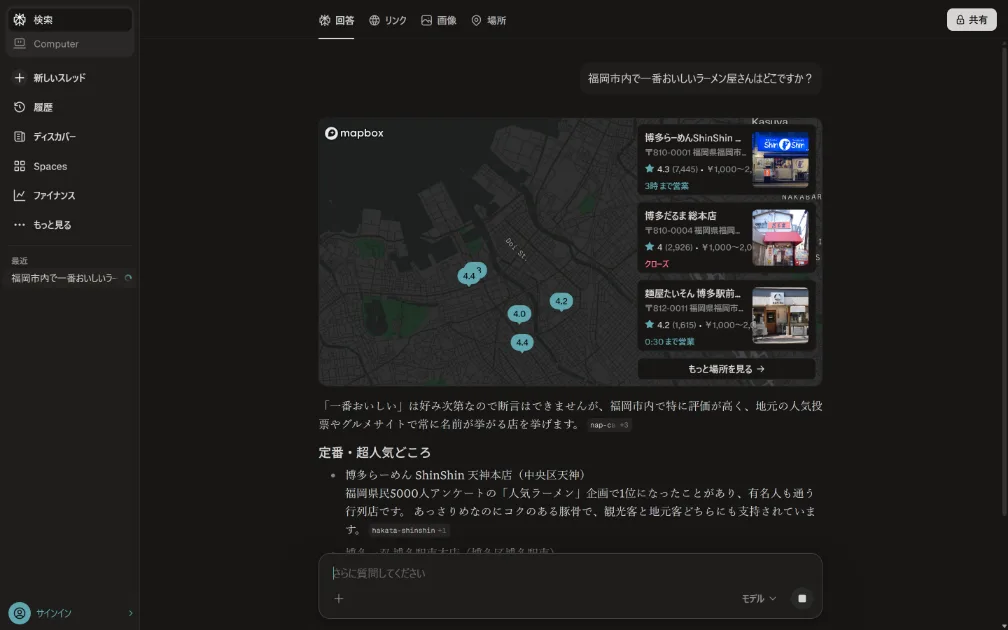
ChatGPTとPerplexityの大きな違いは「引用の見え方」です。ChatGPTは回答に情報源が表示されないケースが多いのに対して、Perplexityは回答文の中に引用元リンクが番号付きで表示されます。
つまりPerplexityに引用されると、ユーザーが「この情報の出どころはどこだろう」と思ったときに、サイトへのリンクが直接表示される状態になります。
AI検索経由の流入という観点で、Perplexityは他のAIサービスと比べて特別な意味を持つサービスといえます。
PerplexityBotとは——クロールの仕組み
Perplexityが検索結果を返すためには、事前にウェブ上の情報を収集しておく必要があります。その収集作業を担うのがPerplexityBotです。ウェブサイトを自動で巡回してページの内容を取得し、Perplexityの検索インデックスに蓄積していきます。
PerplexityBotのUser-Agent(クローラーの名刺のようなもの)は以下のとおりです。
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)サーバーログやアクセス解析でこの文字列が記録されていれば、PerplexityBotが訪問したことになります。User-Agentを使ったクローラー判定の仕組みについては別記事で詳しく解説しています。
GPTBotとの役割の違い
AIクローラーには大きく2種類あります。AIモデルの学習データを集めるクローラーと、AI検索の回答に使う情報をリアルタイムで収集するクローラーです。GPTBotは前者で、ChatGPTのモデル学習用データを集めることが主な目的です。
PerplexityBotは後者です。集めた情報をモデルの学習に使うのではなく、ユーザーが検索したタイミングで回答の材料として使います。Perplexityは「Sonar」という独自モデルを持っていますが、MetaのLlamaをベースにしたもので、PerplexityBotのクロールデータを大規模学習に使う設計にはなっていません。
つまりPerplexityBotにクロールされたページは、そのままPerplexityの検索結果として引用される可能性があります。クロールされること自体が、引用への第一歩です。
過去の炎上——robots.txt無視問題と現在
Perplexityは2024年、大きな批判を受けました。robots.txtでクロールを拒否しているサイトからも情報を収集していたと、複数のメディアやサイト運営者から指摘されたのです。WIREDはrobots.txtでPerplexityBotを明示的にブロックしていたにもかかわらず、非公開のIPアドレスを使ってスクレイピングされていたと報告しています。
この問題に対してPerplexityのCEOは「robots.txtを無視していない」「サードパーティのクローラーによるものだ」と主張しました。ただし明確な説明はなく、批判は収まりませんでした。
2026年現在はどうなっているか
AI観測ラボのサーバーログで確認したところ、2026年3月時点のPerplexityBotはrobots.txtを最初に読んでからクロールを開始していました。3月20日のログでは、10:06にrobots.txtへのアクセスが記録され、その2秒後から記事ページのクロールが始まっています。
少なくとも観測期間中は、robots.txtの確認を経てからクロールするという動きをしていました。2024年の問題が完全に解決されているかどうかは断言できませんが、現在のPerplexityBotはrobots.txtを読む設計で動いています。
robots.txtでPerplexityBotを制御したい場合は、以下のように記述します。
# PerplexityBotを拒否する場合
User-agent: PerplexityBot
Disallow: /
# PerplexityBotを明示的に許可する場合
User-agent: PerplexityBot
Allow: /robots.txtの書き方全般についてはAIクローラーの許可・拒否設定にまとめています。
実測:3日間のログで見えたクロールの実態
AI観測ラボのサーバーログ(2026年3月18日〜3月24日)を解析したところ、PerplexityBotは3日間で合計167件のアクセスを記録していました。残りの4日間はアクセスがゼロです。
| 日付 | アクセス数 | 特徴 |
|---|---|---|
| 3月18日 | 0件 | — |
| 3月19日 | 0件 | — |
| 3月20日 | 130件 | 10分以内に集中 |
| 3月21日 | 0件 | — |
| 3月22日 | 0件 | — |
| 3月23日 | 33件 | 通常巡回 |
| 3月24日 | 4件 | 画像ファイルも取得 |
10分間で130件——並列クロールの仕組み
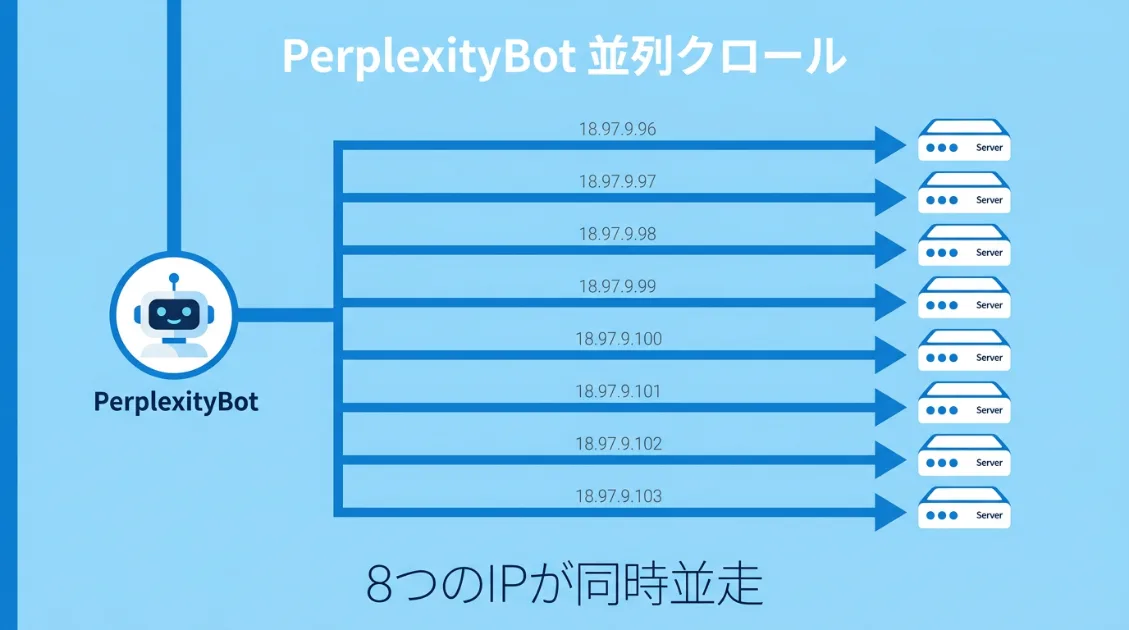
3月20日のログで特に目立ったのが、午前10時6分から10時15分までの約10分間に130件が集中していたことです。通常、クローラーは1つのIPアドレスから順番にページを取得していきます。ところがこの日のPerplexityBotは違いました。
IPアドレスを確認すると、18.97.9.96から18.97.9.103という連番の8つのIPアドレスが同時に動いていました。それぞれが別々のページを並行して取得していたため、短時間で大量のページをクロールできたわけです。
18.97.9.96 18件
18.97.9.97 26件
18.97.9.98 25件
18.97.9.99 4件
18.97.9.100 8件
18.97.9.101 12件
18.97.9.102 10件
18.97.9.103 20件来ない日が続いて、突然一気に来る
3日間のデータを見ると、PerplexityBotには「来ない日が続いて、突然一気に来る」という波型のパターンがあることがわかります。3月20日に初回の大量クロールを済ませた後、3月21日・22日はゼロ。3月23日に再び巡回して、3月24日には画像ファイルまで取得していました。
毎日コンスタントに少しずつ来るGPTBotとは対照的な動き方です。PerplexityBotは「まとめて収集→しばらく休む→差分を確認」というサイクルで動いていると考えられます。
旧スラッグも拾っていた
3月20日のクロール対象を確認すると、現在は301リダイレクト済みの旧スラッグのURLも含まれていました。たとえば/semantic-html-ai-citation/や/ogp-ai-evaluation/など、リライト前のURLです。サイトマップではなく、過去にクロールした記録をもとに再訪していると考えられます。
サイトのURLを変更した場合、しばらくの間は旧URLへのアクセスが続く可能性があります。301リダイレクトを正しく設定しておくことが重要です。
GPTBotとの違いまとめ
ここまでの内容をふまえて、GPTBotとPerplexityBotの違いを整理します。
| GPTBot | PerplexityBot | |
|---|---|---|
| 運営 | OpenAI | Perplexity AI |
| 目的 | AIモデルの事前学習データ収集 | 検索クエリへの回答に使う情報収集 |
| クロール頻度 | 毎日コンスタントに少しずつ | 波型(一気に来てしばらく休む) |
| 並列クロール | なし | あり(複数IPが同時並走) |
| 引用との関係 | 学習データになる可能性 | 検索結果に直接引用される可能性 |
| robots.txt | 遵守 | 現在は遵守(2024年に問題あり) |
クロールされることの意味も異なります。GPTBotにクロールされた場合、将来のChatGPTモデルの学習データになる可能性があります。一方PerplexityBotにクロールされた場合は、ユーザーがリアルタイムで検索しているクエリの回答として引用される可能性があります。
サイト運営者にとってはPerplexityBotの方が、より即効性のある引用につながるクローラーといえます。
GPTBotの詳細についてはAIクローラーの種類と最新シェアを比べてみたで解説しています。
robots.txtでPerplexityBotを制御する
PerplexityBotへの対応は、サイトの方針によって2つに分かれます。
引用されることでサイトへの認知が広がることを期待するなら許可、コンテンツを無断で使われたくないなら拒否です。
許可する場合
robots.txtに何も書かなければデフォルトで許可になります。明示的に許可したい場合は以下のように記述します。
User-agent: PerplexityBot
Allow: /拒否する場合
User-agent: PerplexityBot
Disallow: /特定のページだけ拒否する場合
サイト全体は許可しつつ、特定のディレクトリだけ除外したい場合はこのように書きます。
User-agent: PerplexityBot
Disallow: /private/
Disallow: /members/GPTBotとまとめて設定する場合
複数のAIクローラーをまとめて制御したい場合は、以下のように並べて記述します。
User-agent: GPTBot
User-agent: OAI-SearchBot
User-agent: PerplexityBot
User-agent: ClaudeBot
Disallow: /なお、2024年に指摘されたrobots.txt無視の問題については、観測期間中のログではrobots.txtを読んでからクロールする動きが確認できました。ただしrobots.txtはあくまで「お願い」であり、法的拘束力はありません。
重要なコンテンツを守りたい場合はパスワード保護やアクセス制限と組み合わせる方が確実です。
AIクローラー全般のrobots.txt設定についてはAIクローラーの許可・拒否設定【robots.txt実例付き】にまとめています。
Perplexityに引用されると収益になる——Publishers’ Program
Perplexityには、サイト運営者にとって注目すべき仕組みがあります。2024年7月に始まった「Perplexity Publishers’ Program」です。
コンテンツが引用・参照された際に収益の一部を還元するプログラムで、2026年現在も継続・拡大しています。
2025年9月には「Comet Plus」という月額5ドルのサブスクリプションプランが登場し、収益分配の仕組みが拡張されました。サブスクリプション収益の80%をパブリッシャーに分配する形で、総額4,250万ドル(約62億円)の資金プールが用意されています。
収益が発生する3つのケース
- Cometブラウザのユーザーがパブリッシャーのサイトを直接訪問した場合
- パブリッシャーのコンテンツが検索クエリの回答として引用された場合
- コンテンツがCometのAIアシスタントのタスク遂行に使われた場合
参加メディアはTIME・Der Spiegel・Fortuneなどの海外大手から始まり、日本からはNewsPicksとMinkabu Infonoid、アイティメディアが参加しています。その後もLA Times・Gannettなど大手メディアが次々と加わり、拡大が続いています。
プログラムへの参加問い合わせは publishers@perplexity.ai から受け付けています。現時点では大手メディア中心のプログラムですが、Perplexityに引用されること自体がサイトの認知につながる点は個人ブログや中小サイトにとっても変わりません。
まとめ
Perplexityは日本国内でChatGPTに次ぐ2位のAI検索サービスです。「引用元リンクが必ず表示される」という設計上、サイト運営者にとってはChatGPTより直接的な意味を持つクローラーといえます。
実測ログからわかったPerplexityBotの特徴は3つです。robots.txtを確認してからクロールを開始すること、複数のIPアドレスで並列クロールすること、そして毎日来るのではなく波型のパターンで動くことです。GPTBotとは目的もクロール動作も異なります。
robots.txtで許可しておくことがPerplexityへの引用への第一歩です。コンテンツの質を高めてクロールされやすい状態を作ることが、AI検索時代のサイト運営の基本になっています。
AIクローラー全般の設定についてはAIクローラーの許可・拒否設定【robots.txt実例付き】、GPTBotとの詳細な比較はAIクローラーの種類と最新シェアをあわせてご覧ください。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。


