Claude-SearchBotとは?ClaudeBot・Claude-Userとの違いとrobots.txt設定

サーバーログに Claude-SearchBot という見慣れない文字列が残っていた——そんな経験をしたサイト運営者が増えています。
Anthropicは2026年2月、公式ドキュメントを更新し、自社が運用する3種類のボットの役割を明文化しました。ClaudeBot・Claude-User・Claude-SearchBot、それぞれ目的がまったく異なります。「とりあえず全部ブロック」や「全部許可」では、意図しない結果を招く可能性があります。
記事では3ボットの役割の違い・robots.txtでの制御方法・ブロックする前に考えるべきことを、Anthropic公式ドキュメントをもとに整理します。
この記事でわかること|📖:約6分
- Claude-SearchBotが何をするボットなのか
- ClaudeBot・Claude-Userとの役割の違い
- robots.txtで各ボットを個別に制御する方法
- ブロックしたときにサイトへ起きること
そもそもAnthropicのボットは3種類ある
Anthropicが運用するボットは1種類ではありません。2026年2月に更新された公式ドキュメントには、用途の異なる3種類のボットが明記されています。
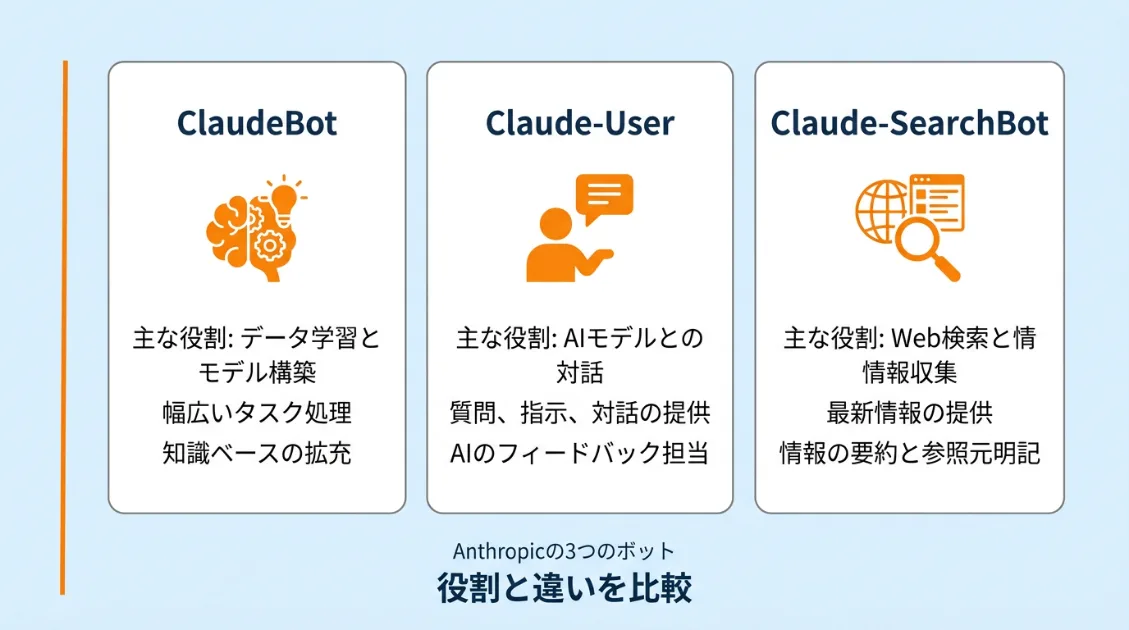
- ClaudeBot:AIモデルの学習データを集めるボット
- Claude-User:ユーザーの質問に答えるためにページを取得するボット
- Claude-SearchBot:Claude の検索機能のためにインデックスを作るボット
3つは名前が似ていますが、動く目的がまったく異なります。1つをブロックしても、残りの2つは引き続きサイトにアクセスします。「ClaudeBot をブロックしたから大丈夫」と思っていても、Claude-SearchBot は別のボットとして動き続けます。
次のセクションから、1つずつ役割を確認していきます。
ClaudeBot:AIモデルの学習データを集めるボット
ClaudeBot は、Anthropic の AI モデルの精度向上や安全性改善のために、公開されているウェブページを収集するボットです。集めたデータが、Claude の学習に使われる可能性があります。
Anthropic の公式ドキュメントには、次のように記載されています。
ClaudeBot helps enhance the utility and safety of our generative AI models by collecting web content that could potentially contribute to their training.
Anthropic公式ヘルプセンター
ClaudeBot をブロックした場合、そのサイトの今後のコンテンツは学習データから除外されます。すでに収集済みのデータには影響しない点に注意が必要です。
user-agent文字列
ClaudeBotrobots.txtでブロックする場合
User-agent: ClaudeBot
Disallow: /Claude-User:ユーザーの質問に答えるためにページを取得するボット
Claude-User は、Claude を使っているユーザーが質問したタイミングで動くボットです。ClaudeBotのように常時クロールしているわけではなく、ユーザーの操作をきっかけにして特定のページを取得します。
たとえば「このURLの内容を要約して」とユーザーがClaudeに指示した場合、Claude-Userが指定したページにアクセスして内容を取得します。定期巡回ではなく、リクエストのたびに動く点が他の2つと大きく異なります。
Claude-User をブロックした場合、ユーザーがClaude経由でサイトのページを参照しようとしても、内容を取得できなくなります。Claudeの回答にサイトの情報が反映されにくくなるため、AI経由の流入や引用機会が減る可能性があります。
user-agent文字列
Claude-Userrobots.txtでブロックする場合
User-agent: Claude-User
Disallow: /Claude-SearchBot:Claude の検索機能のためにインデックスを作るボット
Claude-SearchBot は、ClaudeのWeb検索機能を支えるためにインデックスを構築するボットです。Anthropic は2025年4月にClaudeへの Web検索機能を追加しました。Claude-SearchBotはその検索精度を高めるために、事前にウェブ上のページを収集・分析しています。
ClaudeBot が「学習データの収集」、Claude-User が「ユーザーの指示に応じたページ取得」であるのに対し、Claude-SearchBotは「検索インデックスの構築」が目的です。Google のGooglebotに近い役割と考えるとイメージしやすいです。
Anthropic の公式ドキュメントには次のように記載されています。
Claude-SearchBot navigates the web to improve search result quality for users. It analyzes online content specifically to enhance the relevance and accuracy of search responses.
Anthropic公式ヘルプセンター
Claude-SearchBotをブロックした場合、サイトのコンテンツがClaudeの検索結果に表示されにくくなります。Claude経由での発見・引用・流入の機会が減ることを意味します。
user-agent文字列
Claude-SearchBotrobots.txtでブロックする場合
User-agent: Claude-SearchBot
Disallow: /3つのボットを比較表でまとめる
ここまで紹介した3つのボットの違いを表にまとめます。
| ボット名 | 目的 | 動くタイミング | ブロックした場合の影響 |
|---|---|---|---|
ClaudeBot |
AIモデルの学習データ収集 | 常時巡回 | 学習データから除外される |
Claude-User |
ユーザー指示によるページ取得 | ユーザー操作のたびに起動 | Claude経由でページ内容が参照されなくなる |
Claude-SearchBot |
検索インデックスの構築 | 定期巡回(頻度は非公開) | Claude検索結果に表示されにくくなる |
3つは個別にブロックできます。たとえば「学習には使われたくないが、検索結果には表示されたい」という場合はClaudeBotだけをブロックする、という使い分けが可能です。
robots.txtで各ボットを個別に制御する方法
3つのボットはそれぞれ独立した user-agent 名を持っているため、robots.txt で個別に制御できます。「全部許可」「全部ブロック」「一部だけブロック」の3パターンを確認します。
パターン1:すべて許可する(何も書かない)
robots.txt に何も記述しなければ、3つのボットすべてがサイトにアクセスできます。学習・検索インデックス・ユーザー参照のすべてを許可する状態です。
パターン2:すべてブロックする
Anthropic のボットをすべて遮断したい場合は、3つを個別に記述します。
User-agent: ClaudeBot
Disallow: /
User-agent: Claude-User
Disallow: /
User-agent: Claude-SearchBot
Disallow: /パターン3:一部だけブロックする(推奨)
学習データへの利用は断りたいが、検索結果への表示は維持したい——そんな場合は ClaudeBot だけをブロックします。
User-agent: ClaudeBot
Disallow: /逆に、検索インデックスへの登録だけを断りたい場合は Claude-SearchBot だけをブロックします。
User-agent: Claude-SearchBot
Disallow: /クロール頻度を下げたい場合
完全にブロックするほどではないが、サーバーへの負荷を抑えたい場合は Crawl-delay が使えます。Anthropic は非標準ながらこの設定を尊重することを公式ドキュメントで明記しています。
User-agent: ClaudeBot
Crawl-delay: 1数値の単位は秒です。1と記述した場合、1秒に1回以上はアクセスしないよう制限できます。
なお、Anthropic はIPアドレスによるブロックを推奨していません。IPブロックをすると robots.txt 自体が読み込めなくなり、設定が正しく反映されなくなる可能性があります。
robots.txt の書き方や他のAIクローラーの設定については、AIクローラーの許可・拒否設定【robots.txt実例付き】で詳しく解説しています。
ブロックする前に考えること
「知らないボットが来ている=とりあえずブロック」という判断は、機会損失につながる可能性があります。ブロックを検討する前に、以下の点を確認してみてください。
Claude 経由の流入を捨てることになる
Claude-SearchBotをブロックすると、Claudeの検索結果にサイトのコンテンツが表示されにくくなります。Claudeのユーザー数は世界規模で増加しており、AI検索経由の流入は今後さらに重要になると考えられます。
検索結果への露出機会を自ら手放すことになる点は、ブロック前に意識しておく必要があります。なお、ChatGPT には表示されているのに Claude に出てこないケースの原因と対策は、ChatGPTには出るのに、Claudeに出てこない理由で詳しく解説しています。
学習利用と検索利用は別で判断できる
「自分のコンテンツを学習に使われたくない」という気持ちは自然です。ただし、その場合にブロックすべきは ClaudeBotであり、Claude-SearchBotではありません。目的ごとに個別にブロックできる仕組みになっているため、一括でブロックする前に「何が嫌なのか」を整理することが大切です。
サーバー負荷が問題ならCrawl-delayで対応できる
「アクセスが多くてサーバーが重い」という理由であれば、完全ブロックではなくCrawl-delayでの対応が現実的です。検索インデックスへの登録を維持しながら、サーバーへの負荷だけを抑えられます。
IPブロックは機能しない
AnthropicはIPアドレスによるブロックを推奨していません。IPをブロックすると robots.txt自体が読み込めなくなり、結果としてブロック設定が正しく反映されなくなります。ボットの制御は必ずrobots.txtで行います。
まとめ
Anthropicが運用する3つのボットの役割と制御方法を整理しました。
| ボット名 | 目的 | ブロックした場合の影響 |
|---|---|---|
ClaudeBot |
AIモデルの学習データ収集 | 学習データから除外される |
Claude-User |
ユーザー指示によるページ取得 | Claude経由でページ内容が参照されなくなる |
Claude-SearchBot |
検索インデックスの構築 | Claude検索結果に表示されにくくなる |
- 3つのボットは個別にブロックできる
- 学習に使われたくない場合は
ClaudeBotだけをブロックする - 検索結果への表示を維持したい場合は
Claude-SearchBotを許可したままにする - サーバー負荷が気になる場合は
Crawl-delayで対応する - IPブロックは robots.txt が読み込めなくなるため非推奨
AI検索経由の流入は今後さらに重要になります。ボットの役割を正しく理解したうえで、サイトの方針に合った設定を選んでください。
Anthropicのボット設定と合わせて、AIに引用されるサイトの基本設定も確認しておくと、AI検索全体への最適化がより確実になります。AIに引用されるサイト、基本設定8項目チェックリスト【実装記事つき】もあわせて読んでみてください。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。


