AIクローラーはHTMLしか読まない—ただApplebotだけは違った【AI実験室 #10】

AIクローラーはHTMLしか読まない——そう思っていた。
GPTBotもClaudebotも、サーバーログを見るかぎりHTMLファイルを取得してすぐ帰っていきます。CSSやJavaScriptのファイルを取りに来ることはほとんどありません。
ところがある日、ログに見慣れない動きが記録されていました。CSSファイルを6回、JavaScriptファイルを6回——まるで人間がブラウザでページを開いたときのような取得パターンです。
送信元IPをすべて確認すると、17.x.x.x帯。Apple公式のIPレンジと完全に一致していました。
Applebotでした。
AIクローラーの中で、Applebotだけがブラウザ相当の環境でページをレンダリングします。なぜそういう設計になっているのか。Apple Intelligenceとどう関係するのか。サーバーログの実測データとApple公式ドキュメントをもとに整理しました。
この記事でわかること|📖:約8分
- ApplebotがCSS・JavaScriptまで取得する唯一のAIクローラーである理由
- ApplebotとApplebot-Extendedの2層構造と、Apple Intelligenceへの接続
- サーバーログで確認したCSS×6・JS×6の実測データ
- robots.txtでApplebot-Extendedの学習利用をオプトアウトする方法
Applebotとは何か——2層構造の全体像
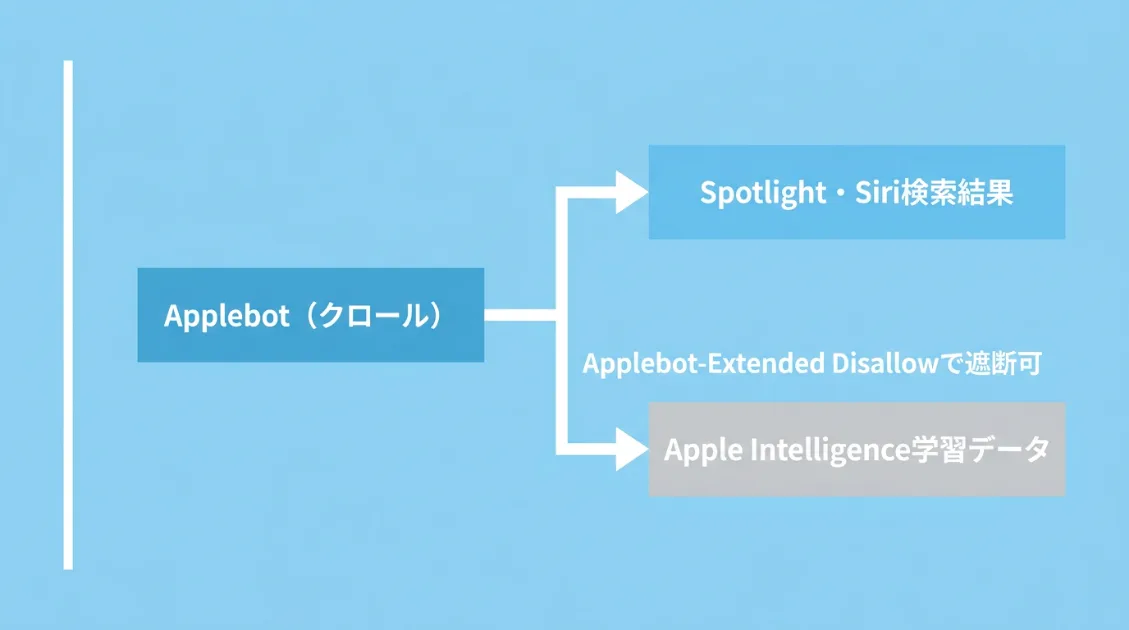
Applebotは、Appleが運営するWebクローラーです。iPhoneやMacに搭載されているSiriやSpotlight(デバイス内の検索機能)が「Web上の情報」を返すとき、その情報を集めているのがApplebotです。
Googleで言えば、Googlebotに相当する存在です。
Applebotは2015年に存在が公式に確認されました。当初はSiriとSpotlightのための検索クローラーとして動いていましたが、Apple Intelligenceの登場によって役割が広がりました。現在は大きく2つの用途で動いています。
Applebot——検索・Siri向けのクローラー
Webページを巡回してコンテンツを収集し、SpotlightやSiriの検索結果に反映させます。一般的な検索エンジンのクローラーと同じ役割です。
Applebot-Extended——Apple Intelligence学習用の制御フラグ
Applebotが集めたデータを、Apple Intelligenceのような生成AIモデルの学習に使ってよいかどうかを決める仕組みです。
重要なのは、Applebot-Extended自体はクロールしないという点です。実際にWebを巡回するのはApplebotで、Applebot-Extendedは「そのデータをAI学習に使う範囲」を制御するためだけに存在します。
robots.txtに以下を追記すると、AI学習への利用をオプトアウトできます。SpotlightやSiriの検索結果には引き続き表示されます。
User-agent: Applebot-Extended
Disallow: /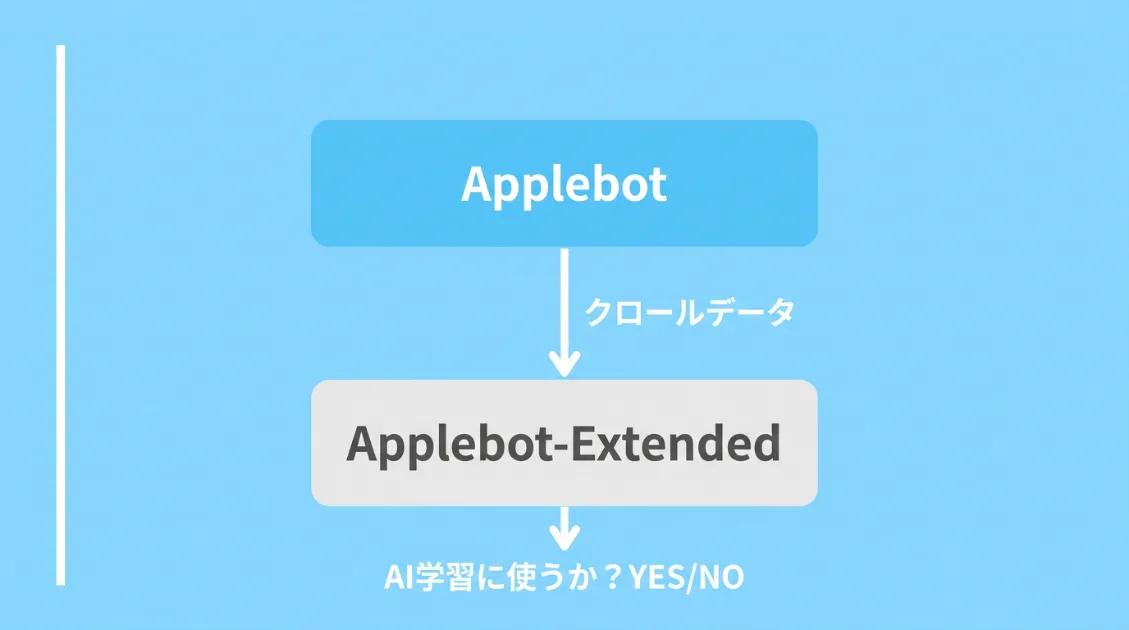
実測ログ——CSS×6・JS×6が残っていた
AI観測ラボのサーバーログを確認したところ、通常のAIクローラーとは明らかに異なる取得パターンが記録されていました。
実際のUser-Agent
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.4 Safari/605.1.15 (Applebot/0.1)末尾にApplebot/0.1と明記されています。一見するとMacのSafariブラウザそのものですが、Applebotが使用するUser-Agentの正式なフォーマットです。
IPアドレスで本物か確認した
User-Agentは偽装できます。そのため、送信元のIPアドレスも確認しました。
記録されていたIPはすべて17.x.x.x帯。Appleが公式に公開しているIPレンジと完全に一致していました。本物のApplebotであることが確定します。
他のAIクローラーとの取得パターンの違い
最も目を引いたのは、取得したファイルの種類です。ログには以下が記録されていました。
- CSSファイル:6回取得
- JavaScriptファイル:6回取得
GPTBotやClaudebotはHTMLファイルを取得して終わります。CSSやJavaScriptを取りに来ることはほぼありません。Applebotの動きは、人間がブラウザでページを開いたときの挙動に近い挙動でした。
なぜApplebotだけがレンダリングするのか——他クローラーとの比較
AIクローラーの多くはHTMLだけを取得します。なぜApplebotだけが異なる動きをするのでしょうか。Apple公式ドキュメントに答えがありました。
「Applebotはブラウザ内でWebサイトのコンテンツをレンダリングする場合があります。JavaScript、CSS、その他のリソースがrobots.txtでブロックされている場合は、コンテンツを適切にレンダリングできない場合があります。」
さらにAppleの機械学習研究チームは、学習データの収集について次のように発表しています。
「ヘッドレスレンダリングを強化し、フルページ読み込み・動的コンテンツのインタラクション・JavaScript実行を可能にした。」
つまりApplebotは、ヘッドレスブラウザ(画面を表示しないブラウザ)を使ってページを丸ごと読み込む設計になっています。JavaScriptで動的に生成されるコンテンツも、CSSで表示・非表示が切り替わる要素も、すべて取得できます。
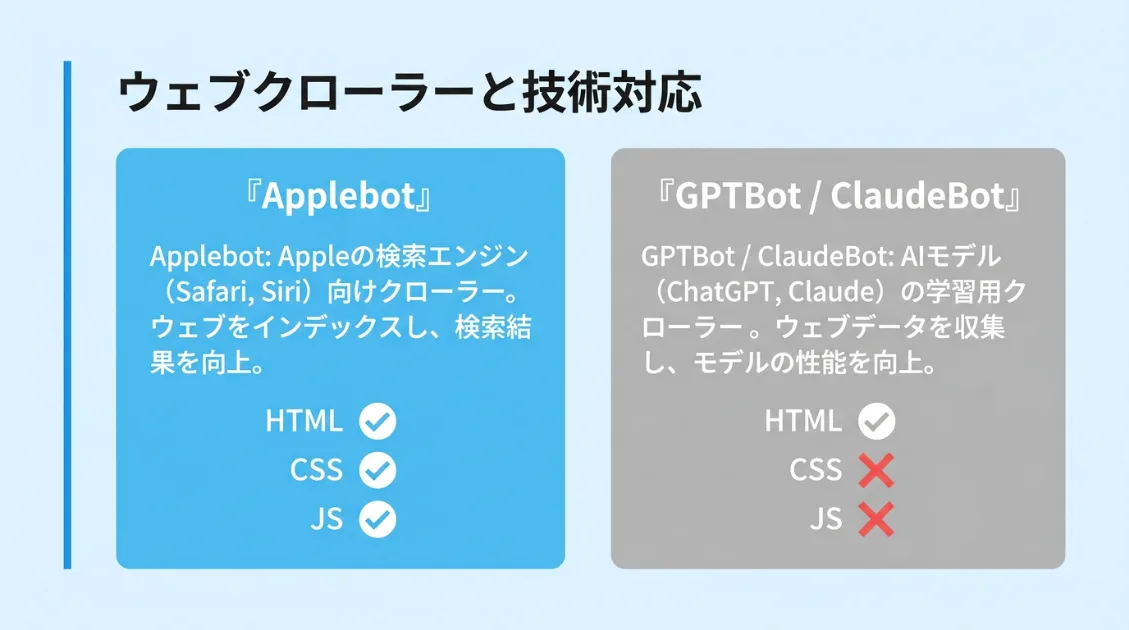
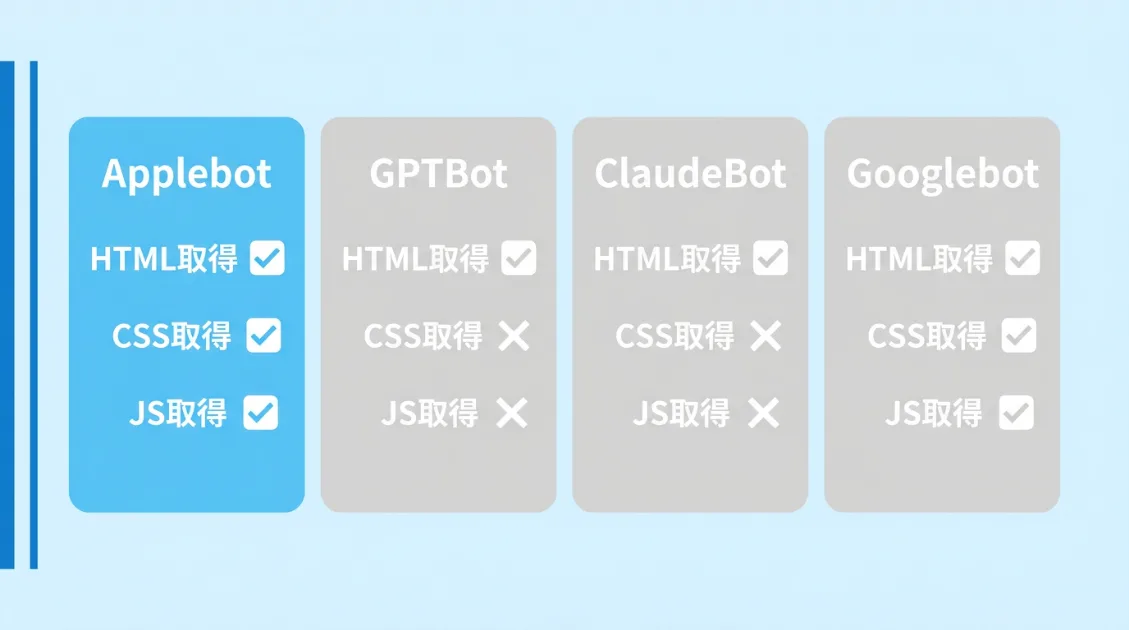
他のAIクローラーと並べると、違いがはっきりします。
| クローラー | HTML取得 | CSS取得 | JS取得・実行 | 用途 |
|---|---|---|---|---|
| Applebot | ✅ | ✅ | ✅ | Siri・Spotlight・Apple Intelligence |
| GPTBot | ✅ | ❌ | ❌ | ChatGPT学習用 |
| ClaudeBot | ✅ | ❌ | ❌ | Claude学習用 |
| Googlebot | ✅ | ✅ | ✅ | Google検索インデックス |
AIクローラーの中でレンダリングまで行うのはApplebotだけです。Googlebotと同等の能力を持つクローラーが、AI学習の文脈でも動いていることになります。
Apple Intelligenceとの接続——Applebot-Extendedの役割
Applebotが集めたデータは、検索結果だけに使われているわけではありません。Apple公式ドキュメントには次のように明記されています。
「Applebotによってクロールされたデータは、Apple Intelligence、各種サービス、デベロッパツールなどの生成AI機能を実現しているAppleの基盤モデルのトレーニングにも使用される場合があります。」
つまりApplebotがサイトを訪れるということは、そのコンテンツがSiriやSpotlightの検索結果だけでなく、Apple Intelligenceの学習データになる可能性があるということです。
学習への利用を断りたい場合はApplebot-Extendedを使う
「検索結果には出てほしいけれど、AI学習には使ってほしくない」という場合、Applebot-Extendedをrobots.txtで制御します。
Applebot-Extended自体はWebをクロールしません。Applebotが集めたデータを「AI学習に使ってよいか」を決めるための制御フラグとして機能します。
robots.txtに以下を追記すると、AI学習へのデータ利用をオプトアウトできます。
User-agent: Applebot-Extended
Disallow: /設定後もApplebotのクロール自体は継続します。SpotlightやSiriの検索結果への表示には影響しません。
GPTBotのオプトアウトと何が違うのか
GPTBotをrobots.txtで拒否すると、クロール自体を止めることになります。ChatGPTの検索結果にも出なくなる可能性があります。
Applebot-Extendedの場合は「クロールは許可するが学習には使わせない」という細かい制御ができます。検索への露出を維持しながらAI学習だけを断れる、現時点では珍しい設計です。
サイト運営者がやるべきこと——robots.txtの設定
Applebotの動きを理解したうえで、サイト運営者として取れる選択肢は3つあります。
パターン1:何もしない(現状維持)
robots.txtにApplebotの記述がない場合、ApplebotはGooglebotへの指示に従います。Googlebotを許可していれば、Applebotも自動的に許可された状態になります。
SpotlightやSiriの検索結果に表示され、Apple Intelligenceの学習データにも使われる可能性があります。特に問題がなければ、何もしなくて構いません。
パターン2:クロールは許可、AI学習だけ断る
検索結果への表示は維持しながら、Apple Intelligenceの学習利用だけをオプトアウトしたい場合の設定です。
User-agent: Applebot
Allow: /
User-agent: Applebot-Extended
Disallow: /現時点でAI学習へのデータ提供に慎重なサイト運営者には、最もバランスの取れた選択肢です。
パターン3:クロール自体を拒否する
ApplebotによるクロールをすべてブロックしたI場合の設定です。SpotlightやSiriの検索結果に表示されなくなります。
User-agent: Applebot
Disallow: /Apple製品ユーザーへの露出がなくなるため、よほどの理由がないかぎり推奨しません。
CSS・JSはブロックしない
Applebotはレンダリングを行うクローラーです。robots.txtでCSSやJavaScriptをブロックしていると、ページを正しく読み込めず、インデックスの精度が下がる可能性があります。
Googlebotと同様に、CSS・JavaScriptはApplebotにも解放しておくことをおすすめします。
robots.txtの基本的な書き方については「AIクローラーの許可・拒否設定【robots.txt実例付き】」で詳しく解説しています。
まとめ
サーバーログに残っていたCSS×6・JS×6の取得記録から、Applebotの動きを追いました。
わかったことを整理します。
- ApplebotはAIクローラーの中で唯一、CSS・JavaScriptまで取得してレンダリングする
- ヘッドレスブラウザを使っており、人間がブラウザでページを開いたときと同じ動きをする
- 取得したデータはSiri・Spotlightの検索結果だけでなく、Apple Intelligenceの学習にも使われる
- AI学習への利用だけを断りたい場合は、Applebot-ExtendedをDisallowする
- CSS・JavaScriptをrobots.txtでブロックしていると、Applebotのインデックス精度が下がる可能性がある
「AIクローラーはHTMLしか読まない」は、Applebotには当てはまりません。Apple製品のユーザーにコンテンツを届けたい場合、Googlebotと同じ感覚でCSS・JavaScriptを解放しておくことが出発点になります。
Applebotが実際にどのくらいの頻度でサイトを訪れているか、AI観測ラボでは引き続きログを取って観測していきます。
AIクローラー全体の許可・拒否設定については「AIクローラーの許可・拒否設定【robots.txt実例付き】」を、AI引用のための基本設定チェックリストは「AIに引用されるサイト、基本設定8項目チェックリスト」をあわせてご覧ください。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。


