AmazonbotがREST APIを叩いていた—サーバーログで見えた新事実【AI実験室 #05】

サーバーログを眺めていたら、見慣れないアクセスが目に入りました。
HTMLページを取得した直後に、同じコンテンツのREST APIエンドポイントを叩いているクローラーがいます。しかも毎回403(アクセス拒否)で弾かれているにもかかわらず、日を変えて繰り返しやってきます。
正体はAmazonbotでした。
GPTBot、OAI-SearchBot、Googlebot、bingbot、ClaudeBot——観測ラボのブログには7種類のAIクローラーが訪れています。そのなかでREST APIを叩いているのはAmazonbotだけです。
なぜAmazonだけがこんな動きをしているのか。ログを手がかりに読み解いていきます。
この記事でわかること|📖:約5分
- AmazonbotがREST APIを繰り返し叩いている理由
- 7種のAIクローラーを比較してわかったAmazonbotだけの特徴
- AmazonがRufusで目指している購買体験の全体像
- EC運営者・サイト運営者が今すぐ確認すべきこと
AmazonbotはAmazonのAI学習用クローラーです
Amazobotの正式名称は「Amazonbot」。Amazonが運営するウェブクローラーで、Amazon公式の説明によると「製品・サービスの改善に使用され、AmazonのAIモデルのトレーニングにも使われる可能性がある」と記載されています。
ここで多くの人が見落としているポイントがあります。Amazonのクローラーは1種類ではありません。実は用途が異なる2種類が存在します。
今回のサーバーログで確認できたのは「Amazonbot」の方です。つまりAmazonのAIモデルそのものを鍛えるためのデータ収集が目的です。
AlexaやRufusに「AIクローラーとは何か」と聞いたとき、観測ラボのような一次データを持つサイトから学習している可能性があります。
7種のAIクローラーを比較した——REST APIを叩くのはAmazonbotだけだった
観測ラボのブログ(blog.ai-kansoku.com)のサーバーログを2日分(2026年3月7日・3月13日)分析しました。確認できた主要AIクローラーは7種類です。
それぞれのアクセス数と、REST APIへのアクセス数を集計した結果がこちらです。
Googlebotは41件・Applebotは52件とアクセス数は多いものの、REST APIへのアクセスはゼロです。すべてのクローラーがHTMLページだけを取得しているなかで、Amazonbotだけが異なる行動をとっています。
しかも6件すべてがHTTPステータス403——つまりアクセス拒否で弾かれています。それでも日を変えて繰り返しアクセスしてきます。
実際のログはこうなっています。
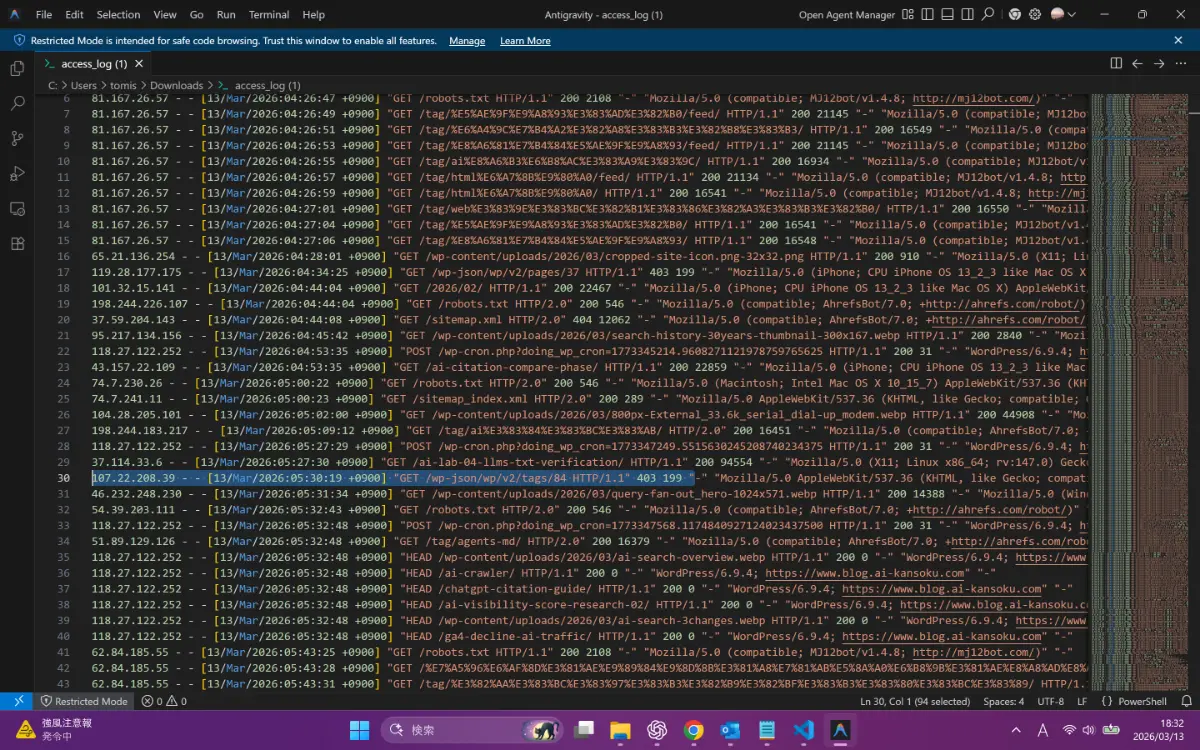
/wp-json/wp/v2/tags/84 へのアクセス(403)が記録されているサーバーログ(抜粋)
[07/Mar/2026:12:59:12] Amazonbot GET /wp-json/wp/v2/posts/668 403
[13/Mar/2026:05:30:19] Amazonbot GET /wp-json/wp/v2/tags/84 403
[13/Mar/2026:07:34:12] Amazonbot GET /wp-json/wp/v2/tags/86 403
[13/Mar/2026:10:34:36] Amazonbot GET /wp-json/wp/v2/tags/83 403403で弾かれても諦めないのはなぜか。次のセクションでREST APIを狙う理由を掘り下げます。
なぜHTMLではなくREST APIを叩くのか
まずそもそもREST APIとは何か、から説明します。
WordPressで作られたサイトには、通常のHTMLページとは別に「データだけを取り出せる専用の窓口」が用意されています。URLの形式は /wp-json/wp/v2/posts/668 のようになっており、記事のタイトル・本文・カテゴリ・公開日などが、デザインや広告を一切含まないJSON形式で返ってきます。これがREST APIです。
本来は開発者がアプリやツールを作るために使う機能ですが、Amazonbotはこれをコンテンツ収集に活用しています。
REST APIのレスポンスには「AIが本当に欲しいもの」だけが入っています。デザインも広告もナビゲーションも一切なく、純粋なデータだけがJSON形式で返ってきます。
実際にREST APIのレスポンスを見るとこのような構造です。
/wp-json/wp/v2/posts/668 のレスポンス(一部)
{
"id": 668,
"title": { "rendered": "AIOとは?検索順位よりも..." },
"content": { "rendered": "<p>記事の本文テキスト...</p>" },
"date": "2026-03-03T08:00:00",
"tags": [83, 84, 86]
}HTMLページと比べると処理コストが大幅に下がります。不要なコードを取り除く手間がなく、必要なデータだけを効率よく取得できます。
AmazonbotがHTMLページを取得した直後にREST APIを叩くのは、HTMLで記事の存在を確認してから、同じ記事のデータをより効率的な方法で取り直そうとしているためだと考えられます。
Amazonbotの行動パターン:HTMLページで記事を発見 → REST APIで同じ記事のデータを直接取得 → ノイズなしのクリーンなデータをAIの学習に使う
AmazonはRufusで何をしようとしているのか
Amazonbotが熱心にコンテンツを収集している背景には、RufusというAIショッピングアシスタントの存在があります。
Rufusとはアマゾンのアプリ内に組み込まれたAIで、ユーザーが「通勤用のヘッドフォンを探している」「防水性能が高いスニーカーはどれか」といった質問を自然な言葉で入力すると、商品を推薦してくれます。
ここで重要なのは、Rufusが回答するために必要な知識の一部を、ウェブ上のコンテンツから学習しているという点です。Amazonの商品データベースだけでは補えない「使用感」「比較情報」「専門的な解説」を、観測ラボのようなブログから取り込んでいる可能性があります。
従来の購買行動では、ユーザーはGoogleで検索してレビューサイトやブログを読み比べ、最終的にAmazonで購入していました。Rufusが賢くなるほど、この「Amazon外に出て調べる」ステップがAmazonの中で完結するようになります。
観測ラボのブログで書いたAgentic Commerceの記事でも触れましたが、AIエージェントが自律的に買い物をする未来において、Amazonはすでにその入口を着々と作っています。Amazonbotによるコンテンツ収集はその一部です。
これはECサイト運営者にとって、ゼロクリック問題のEC版とも言える変化です。Googleを経由してECサイトに流入していたトラフィックが、Rufusの進化とともに少しずつAmazon内に吸収されていく可能性があります。
Amazonbotが観測ラボのブログを学習しているとすれば、将来的にRufusが「AIクローラーとは何か」という質問に対して、観測ラボのコンテンツをもとに回答する可能性があります。GPTBotやOAI-SearchBotが引用のためにクロールするのと同じ構造です。
EC運営者・サイト運営者はどうすればいいか
Amazonbotの動きを踏まえると、サイト運営者には2つの選択肢があります。学習を許可するか、拒否するかです。
選択肢1:Amazonbotを許可する
RufusやAlexaに自分のコンテンツを引用・参照してもらいたい場合は、Amazonbotのアクセスを許可します。特に以下のようなサイトは許可するメリットが大きいです。
- 商品レビューや比較記事を運営しているサイト
- 専門的な知識を発信しているブログ
- ECサイトの商品説明が充実しているサイト
現在robots.txtに特別な記述がなければ、Amazonbotは自動的に許可されている状態です。ただし今回のログで確認したように、REST APIへのアクセスは別途制御が必要です。
選択肢2:Amazonbotを拒否する
AIモデルの学習データとしてコンテンツを使われたくない場合は、robots.txtで拒否できます。
robots.txt
# Amazonbotを全拒否する場合
User-agent: Amazonbot
Disallow: /
# 特定ディレクトリだけ拒否する場合
User-agent: Amazonbot
Disallow: /wp-json/AIクローラーのrobots.txt設定について詳しく解説した記事も参考にしてください。
REST APIは別途ブロックが必要
ここが今回のログで判明した重要なポイントです。robots.txtでAmazonbotを拒否しても、WordPressのREST APIへのアクセスをブロックできるとは限りません。
REST APIを完全にブロックしたい場合は、functions.phpに以下のコードを追加します。
functions.php
add_filter( 'rest_authentication_errors', function( $result ) {
// ログインユーザー以外はREST APIへのアクセスを拒否
if ( ! is_user_logged_in() ) {
return new WP_Error(
'rest_disabled',
'REST APIへのアクセスは許可されていません',
[ 'status' => 403 ]
);
}
return $result;
} );観測ラボのブログでは現在このコードを設定済みです。そのためAmazonbotのREST APIアクセスはすべて403で返却されています。
⚠️ 注意
REST APIを完全にブロックすると、Gutenbergエディタや一部のプラグインが正常に動作しなくなる場合があります。設定前にバックアップを取り、動作確認をし適用してください。
まとめ
今回のサーバーログ分析で判明したことを整理します。
AIクローラーは「HTMLを読むもの」という前提で語られることがほとんどです。Amazonbotがなぜblogにきていたのか非常に驚愕しましたが水面下で着々と独自でデータを集める技術は流石の一言。
AmazonbotはHTMLの裏側にあるREST APIを狙っており、クローラーによって行動パターンが大きく異なることが今回のログで確認できました。
AIがコンテンツを収集する方法は今後さらに多様化していく可能性があります。サーバーログを定期的に確認して、どのクローラーがどんな動きをしているかを把握しておくことが、AI時代のサイト運営の基本になっていきます。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。