GPTBot・OAI-SearchBotの仕組みと許可・拒否設定【robots.txt実例付き】

2026年、あなたのサイトには複数のボットが来ています。
GooglebotだけじゃなくGPTBot・OAI-SearchBot・PerplexityBot——それぞれ目的も挙動もまったく違います。
でも、ほとんどのサイト運営者はその違いを把握していません。
この記事では、主要AIボットのクロールの仕組みを比較表・robots.txt設定例とあわせて保存版としてまとめました。
この記事でわかること|📖:約7分
- 通常の検索クロールとAI検索クロールの具体的な違い
- 各AIボット(Googlebot / GPTBot / OAI-SearchBot など)の役割と比較
- 2026年時点の最新クロール統計データ
- robots.txtの設定パターン早見表
- サイト運営者として今すぐできる対策チェックリスト
なぜ今「AI検索のクロール」を知る必要があるのか
2024〜2025年にかけて、検索のあり方が大きく変わりました。
従来の検索は「青いリンクの一覧から選ぶ」スタイルでした。
でも今は違います。
- Google AI Modeが直接答えを生成する
- ChatGPTが最新情報を検索して回答する
- PerplexityがWebを読んで要約してくれる
つまり、「検索 = サイトへの流入」という方程式が崩れ始めているんです。
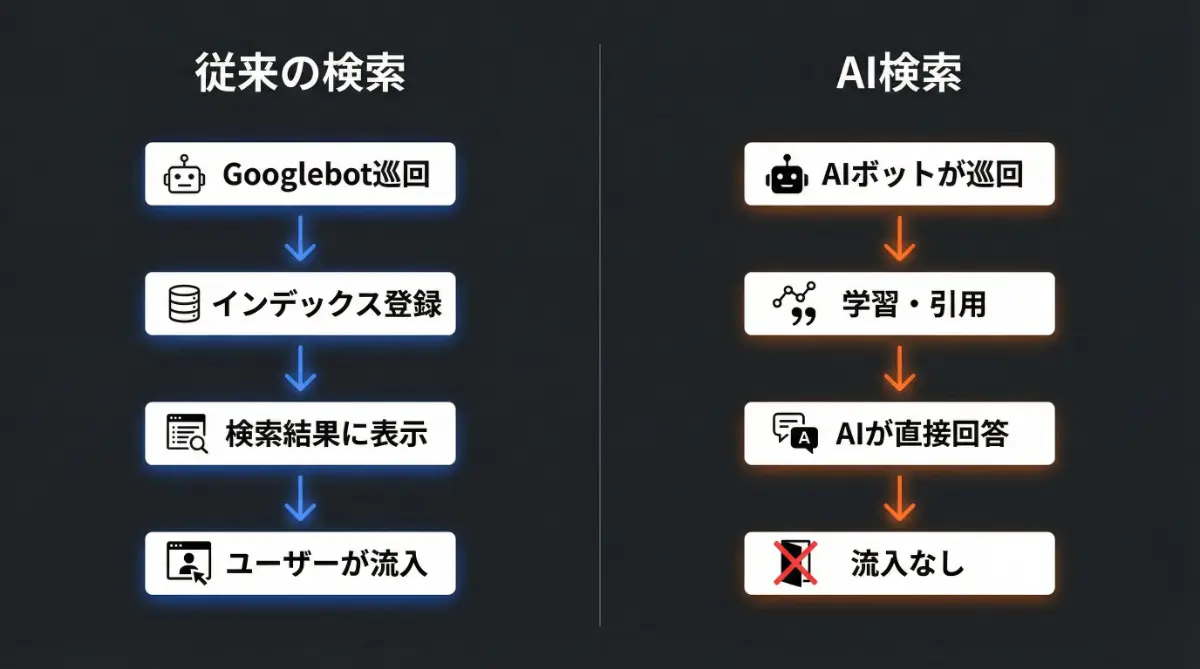
従来の検索 vs AI検索の流れ
【従来の検索】
Googlebotが巡回 → インデックス登録 → 検索結果に表示 → ユーザーがクリックして訪問
【AI検索の現実】
複数のボットが巡回 → AIが内容を学習・引用 → ユーザーへ直接回答(サイトには来ない)
コンテンツは使われているのに、流入が来ない。
こんな新しい課題が生まれています。
Webサイトを運営する立場なら、自分のサイトがどのボットにどう読まれているかを把握することは、もはや必須の知識です。
🔑 この記事でわかること
- 通常の検索クロールとAI検索クロールの具体的な違い
- 各AIボット(Googlebot / GPTBot / OAI-SearchBot など)の役割と比較
- 2026年時点の最新クロール統計データ
- サイト運営者として今すぐできる対策
そもそも「クロール」とは?基礎をおさらい
クロールの仕組み
クロールとは、検索エンジンやAIサービスが運営する「ボット(クローラー)」と呼ばれるプログラムが、インターネット上のWebページを自動的に訪問・収集する行為です。
ボットはリンクを辿るようにページからページへ移動しながら、テキストや構造情報を収集します。
集めたデータは「インデックス」と呼ばれるデータベースに格納され、検索結果やAIの回答生成に使われます。
robots.txt とは
Webサイトのルートに置くテキストファイルで、「どのボットにどのページへのアクセスを許可/拒否するか」を指定できます。
ただし、あくまでボットへの「お願い」であり、法的拘束力はありません。良識的なボットは遵守しますが、悪質なボットは無視することもあります。
📖 詳しい書き方はこちら:AIクローラー時代のrobots.txt完全ガイド
# robots.txt の基本構文
User-agent: GPTBot ← 対象ボットを指定
Disallow: / ← サイト全体へのアクセスを拒否通常検索クロールの流れ(復習)
- Googlebotがサイトを定期的に巡回
- ページの内容・リンク構造を解析
- Googleのインデックスに登録
- ユーザーが検索 → 検索結果に表示 → クリックで流入
このモデルでは「クロールされる = 流入につながる可能性がある」という関係が成立していました。
AI検索ではこの関係が崩れます。
通常検索 vs AI検索:クロールの何が違うのか
① 目的が違う
通常検索のクロールは「インデックス登録→検索結果表示→流入」が目的です。
一方、AI検索のクロールには主に2つの目的があります。
- モデル学習用データの収集(GPTBot、ClaudeBotなど)
- リアルタイム回答生成のための情報取得(OAI-SearchBot、PerplexityBotなど)
特にリアルタイム取得型は、ユーザーが質問した瞬間にボットが動くケースもあり、クロールの性質が根本的に異なります。
② JavaScript(JS)の扱いが違う
Googlebotは「Web Rendering Service(WRS)」という仕組みでJavaScriptを実行し、動的コンテンツも読み取れます。
一方、GPTBot・OAI-SearchBot・ClaudeBot・PerplexityBotなど主要なAIボットはJavaScriptを実行しません。
ReactやVue.jsなどのSPAサイトや、JS依存のコンテンツはAI検索には「見えていない」可能性があります。
⚠️ 注意
SPA・JSヘビーなサイトを運営している場合、AIボットにはページ内容がほぼ空に見える可能性があります。サーバーサイドレンダリング(SSR)の採用を検討しましょう。
③ クロール頻度と量が違う
Googlebotは継続的・高頻度でクロールしますが、AIボット(特に学習系)は比較的低頻度で訪問し、一度大量取得したら長期間来ないパターンが多いです。
一方「ユーザーアクション型」クロール(ChatGPT-Userなど)は、ユーザーの検索行動に連動して急激に増減します。
比較表:通常検索 vs 主要AI検索ボット
| 比較項目 | 通常検索 (Googlebot) |
AI検索 (ChatGPT・Perplexity等) |
|---|---|---|
| 主なBot名 | Googlebot | GPTBot / OAI-SearchBot PerplexityBot |
| クロール頻度 | 高頻度・継続的 | 中〜低頻度 |
| JS実行 | ✅ あり(WRS) | ❌ なし |
| robots.txt遵守 | ✅ 遵守 | ✅ 遵守 ※ChatGPT-Userは例外あり |
| 流入への還元 | 🟢 多い | 🔴 少ない |
| 個別ブロック | ❌ 実質不可 | ✅ 独立制御可 |
主要AIクローラー全解説
現在Webサイトを巡回している主要なAI関連ボットを一覧で整理します。
| Bot名 | 主な用途 | JS実行 | robots.txt制御 |
|---|---|---|---|
| Googlebot | 通常検索インデックス+AI機能に流用 | ✅ | ブロック不可(検索圏外になる) |
| Google-Extended | Gemini等のAIモデル学習専用 | ✅ | ブロック可。検索順位に影響なし |
| GPTBot | ChatGPT等のLLMモデル学習用 | ❌ | 独立してブロック可 |
| OAI-SearchBot | ChatGPT検索のリアルタイムインデックス | ❌ | 独立してブロック可 |
| ChatGPT-User | ユーザーがURLを参照した際の取得 | ❌ | robots.txt適用外 |
| ClaudeBot | Claude AIのモデル学習・更新用 | ❌ | ブロック可 |
| PerplexityBot | Perplexity AI検索の情報取得 | ❌ | ブロック可 |
| Meta-ExternalAgent | MetaのLLMモデル学習用 | ❌ | ブロック可 |
Googlebotの「二重利用」問題
Googlebotはもともと、通常の検索インデックスを作るためのボットです。
ところが現在、同じクロールデータがAI Overviewsや Google AI Modeにも流用されています。つまり、Googlebotを許可した時点で、通常検索とAI機能の両方にコンテンツを提供していることになります。
Googlebotのデータ流用フロー
→ クリックで流入
→ 流入はゼロ
パブリッシャー側のジレンマ
Googlebotをブロックしたら検索圏外になる
↓
だからブロックできない
↓
でも、そのデータがAI機能にも勝手に使われる
この問題を回避する唯一の手段が、Google-Extendedです。
Google-ExtendedはGeminiなどのAIモデル学習専用のボットで、robots.txtで個別にブロックしても検索順位には影響しません。「検索流入は維持しながら、AIモデルの学習データには提供しない」という制御が、現状これだけで可能です。
📌 Google-Extendedの設定例
User-agent: Google-Extended
Disallow: /これだけで、Gemini等への学習提供を拒否できます。通常の検索順位への影響はありません。
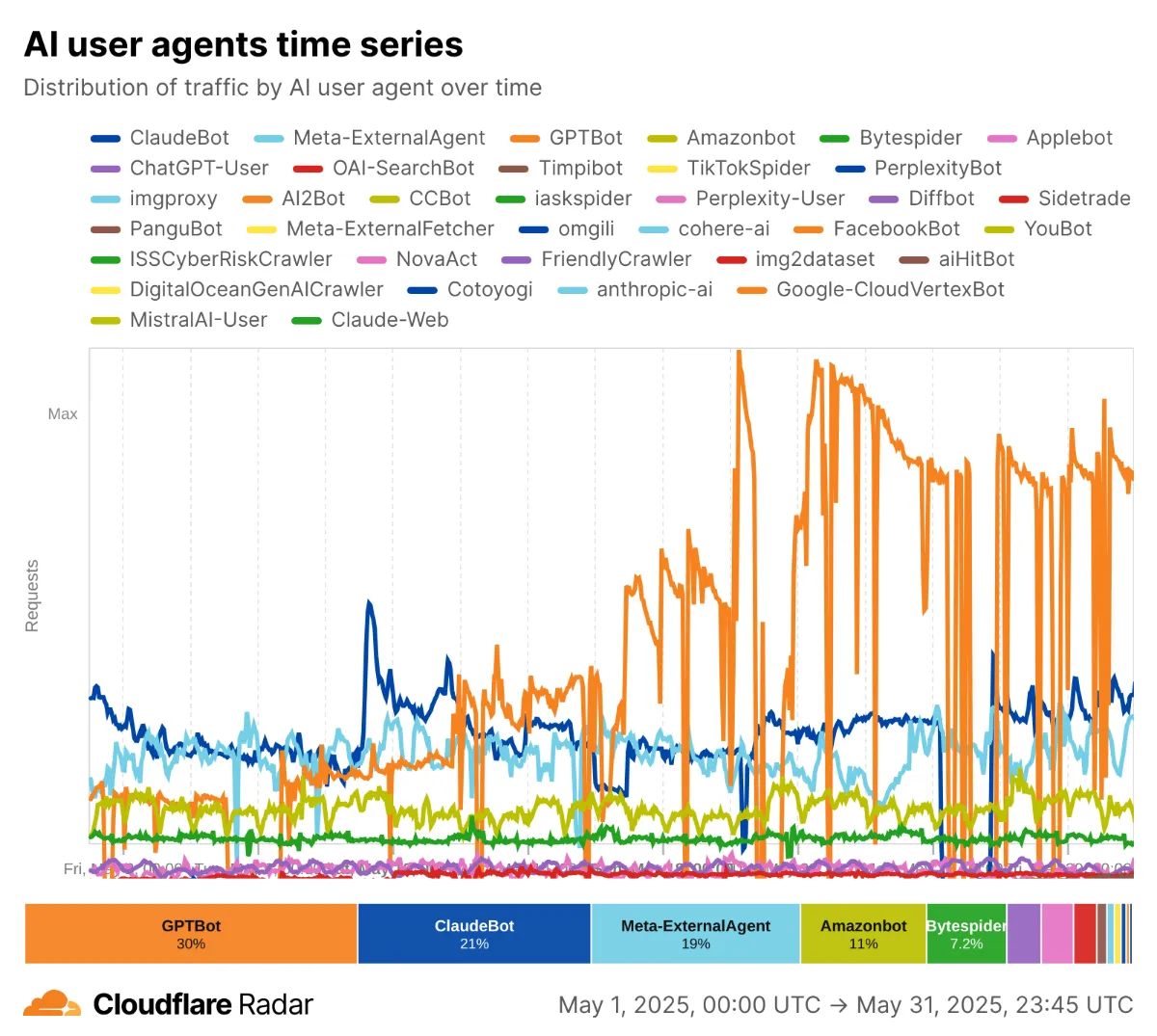
2026年最新データ:クローラーの勢力図
Cloudflareが2025年末〜2026年初頭に発表したレポートをもとに、最新のクロール状況を整理します。
📖 参考(外部リンク):From Googlebot to GPTBot: who’s crawling your site in 2025(Cloudflare Blog)
① Googlebotが圧倒的首位
- Googlebotは検証済みボットトラフィックの25%以上を占め、ダントツの1位
- GooglebotのHTML取得量は、全AIボット合計(4.2%)を上回る4.5%
- ユニークページのクロール数:Googlebot 11.6%、GPTBot 3.6%、PerplexityBot 0.06%
② AIボットは急拡大中
| ボット名 | シェア変化 | リクエスト増減 |
|---|---|---|
| GPTBot | 5% → 30% | +305% |
| ChatGPT-User | 新規参入 | +2,825% |
| PerplexityBot | シェア小 | +157,490% |
| ClaudeBot | 11.7% → 5.4% | -46% |
| Bytespider | 42% → 7% | -85% |
③「ユーザーアクション型クロール」が15倍以上に急増
ユーザーが実際にAI検索を使ったときに発生する「ユーザーアクション型クロール」は、2025年1年間で15倍以上に膨れ上がりました。
学校・職場でのAI検索利用拡大を反映しており、夏休みや年末には一時的な減少も見られました。
④ サイト運営者はAIボットをブロックしている
Cloudflareの調査では、AIクローラーはrobotsで最も多くブロックされているユーザーエージェントです。
GPTBot・ClaudeBot・CCBotへの完全ブロック指定が特に多く、GooglebotやBingbotは部分的なブロックが中心(ログイン画面など限定)という対照的な状況です。
サイト運営者への影響と具体的な対策
問題① サーバー負荷の増大
AIボットの急増により、特に中〜小規模サイトではサーバーへの負荷が増大しています。
流入にならないクロールがサーバーコストだけ押し上げるという問題も生まれています。WAF(Webアプリケーションファイアウォール)によるボットブロックが有効です。
問題② クロールされても流入がゼロ問題
「Crawl-to-Refer Ratio(クロール対流入比)」という概念が注目されています。
各社のクロール対流入比(2025年)
- Anthropic:最大 700:1(700回クロールして流入は1回)
- OpenAI:200:1 前後
- Google:3〜30:1(検索流入として還元される)
コンテンツを大量に消費しながら、トラフィックをほとんど還元しないのが現状です。
対策:robots.txt 設定の早見表
各ボットへの対応方針を決めたら、robots.txtに反映しましょう。主要なパターンをまとめました。(robots.txtの詳しい書き方・全ボット一覧はこちら)
| やりたいこと | robots.txt 記述例 |
|---|---|
| Google AIモデルへの学習を拒否(検索は維持) |
|
| ChatGPTの学習データに含めたくない |
|
| ChatGPT検索引用はOK・学習は拒否 |
|
| 主要AIボットを全ブロック(Googlebot除く) |
|
| ⚠️ 通常検索はOK・Google AIのみ拒否 | 現状、GooglebotとAI利用の完全分離は不可。 Google-Extendedのみ学習用を制御できる。 |
今すぐできるアクションチェックリスト
- 自サイトのrobots.txtを見直し、各AIボットへの方針を明確化する
- サーバーログを確認し、どのAIボットがどの頻度でクロールしているか把握する
- JS依存コンテンツがある場合、SSR(サーバーサイドレンダリング)の導入を検討する
- Google Search ConsoleでAI Overviews・AI Modeへの表示状況を確認する
- WAFでAIボット向けのアクセス制御ルールを設定する(Cloudflare利用者は特に有効)
- Google-Extendedは検索に影響なくブロックできるため、方針に応じて設定する
まとめ
AI検索の普及で、クロールの構造は静かに変わっています。AIボットは増え続けていますが、流入として返ってくるケースはまだ少ないのが現実です。
まず自分のサイトがどのボットにどう読まれているかを把握することが、最初の一歩になります。
📋 今すぐできるアクション
| やりたいこと | 対応 |
|---|---|
| 検索流入を維持したい | Googlebotは許可。Google-Extendedはブロック検討 |
| AIに引用されたい | OAI-SearchBot・PerplexityBotは許可。JS依存コンテンツを見直す |
| 学習データに使われたくない | GPTBot・ClaudeBot・Google-Extendedをブロック |
| サーバー負荷を下げたい | 学習系ボットをrobotsでブロック。CloudflareのWAF活用も有効 |
次に読む
AIボットがあなたのサイトを正確に読めない理由は、HTMLの構造にあります。
AIはdivが読めない——セマンティックHTMLがAI引用の土台になる理由 →
参考:Cloudflare Radar Year in Review 2025 / Cloudflare: Google’s AI crawler policy / OpenAI Bots Documentation / Search Engine Land / Search Engine Journal — この記事は2026年2月のデータに基づいています。AIクローラーの動作・仕様は今後変更される可能性があります。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。


